CUDA C++ 编程指引:编程模型 | CUDA
本系列参考自 CUDA C++ Programming Guide。
可扩展编程模型
可扩展的编程模型使得已编译好的 CUDA 程序能够在任意核心的 GPU 上执行。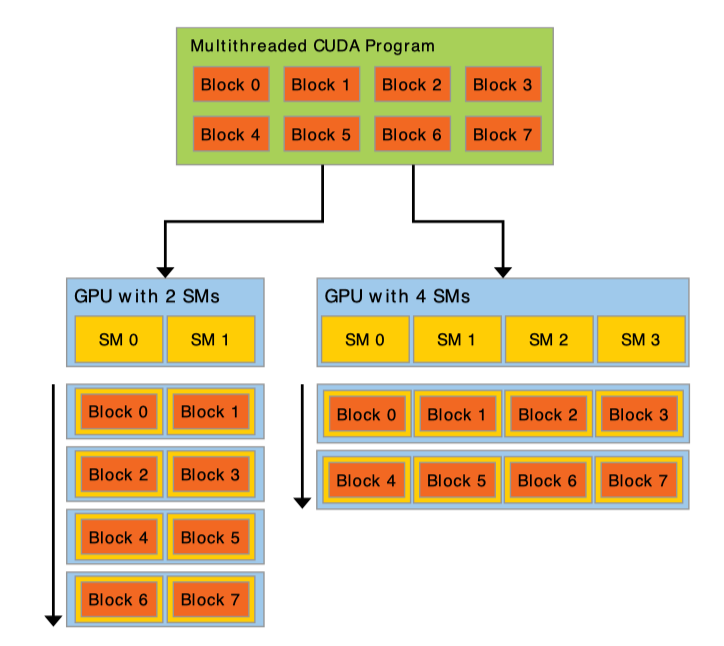
内核函数
下面这段代码通过语法 <<<...>>> 指定使用 N 个线程去执行 VecAdd 函数,每个执行内核函数的线程拥有一个独一无二的线程 ID,可以通过内置的 threadIdx 变量在内核函数中访问。限定符 __global__ 声明某函数为内核函数,在设备上执行,只能从主机端调用。
1 | __global__ void VecAdd(float* A, float* B, float* C) { |
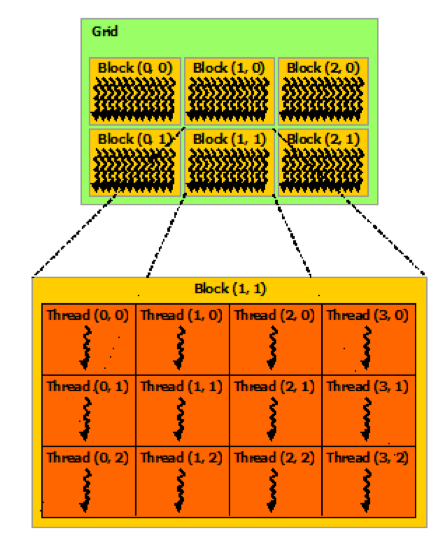
线程
下面这段代码指定使用 1 个含有 N*N 个 线程(二维网格形状)的线程块执行 MatAdd 函数。另外,一个块内的线程数目是有限的,在目前的 GPU 中,一个线程块最多有 1024 个线程。
1 | __global__ void MatAdd(float A[N][N], float B[N][N], float C[N][N]) { |
一个内核函数可被多个同样大小的线程块执行。下面这段代码指定使用 N/threadsPerBlock.x*N/threadsPerBlock.y 个含有 16*16 个线程的线程块执行 MatAdd 函数。
1 | __global__ void MatAdd(float A[N][N], float B[N][N], float C[N][N]) { |
参考
CUDA C++ Programming Guide
《CUDA C Programming Guide》(《CUDA C 编程指南》)导读
《CUDA 并行程序设计:GPU 编程指南》
CUDA C++ 编程指引:编程模型 | CUDA