CUDA C++ 编程指引:硬件实现 | CUDA
本系列参考自 CUDA C++ Programming Guide。
SIMT 架构
根据计算机历史上有名的的费林分类法(Flynn’s Taxonomy),如下图所示计算机体系架构可以简单分为四类,分别是:
- 单一指令流单一数据流计算机(SISD, Single Instruction Single Data)
- 单一指令流多数据流计算机(SIMD, Single Instruction Multiple Data)
- 多指令流单一数据流计算机(MISD, Multiple Instruction Single Data)
- 多指令流多数据流计算机(MIMD, Multiple Instruction Multiple Data)
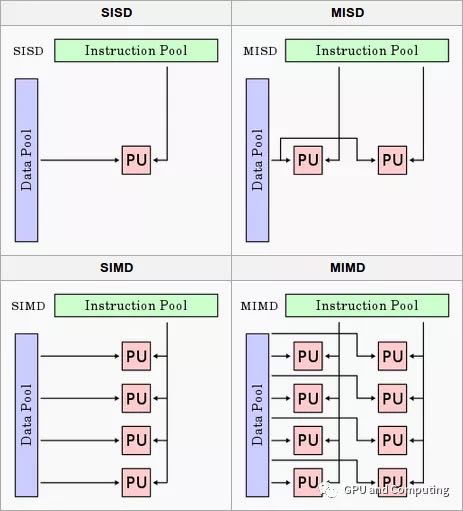
单核 CPU 可以归类为 SISD,多核 CPU 属于 MIMD。平时常见的 SIMD 指的是采用一个控制器来控制多个处理单元,同时对一组数据的元素分别执行相同的操作从而实现空间上并行的技术。传统 CPU 的指令扩展 SSE 和 NEON 都属于典型的 SIMD。现代 GPU 在 SIMD 基础上发展出 SIMT(Single Instruction Multiple Thread)的执行架构。
传统 SIMD 是一个线程调用向量处理单元(Vector ALU)执行向量指令来操作向量寄存器完成运算,而 SIMT 往往由一组标量处理单元(Scalar ALU)构成,每个处理单元对应一个硬件线程,所有处理单元共享指令预取/译码模块并接收同一指令共同完成 SIMD 类型运算,运行其上的线程可以有自己的寄存器堆,独立的内存访问寻址以及执行分支。下图是有关分发 CUDA 的计算任务到 GPU 硬件上执行,展示了软硬件视角各个层级的对应关系:
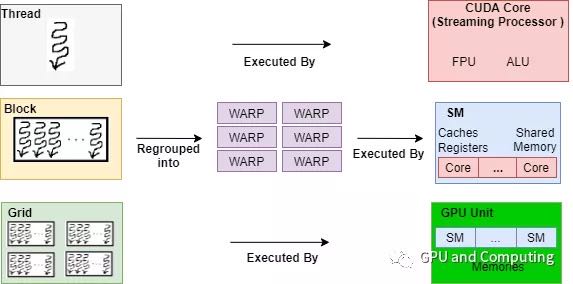
硬件架构
GPU 由内存和一系列流处理器簇(Streaming Multiprocessors, SM)组成,不同 GPU 的具有不同的内存大小和 SM 数量。多个 GPU 可以挂在 PCI-E 总线上,可以跟主机端或其他 GPU 通信。

SM 由一系列流处理器(Streaming Processor,SP)、寄存器文件、共享内存、SPU(特殊运算单元),以及纹理/常量/L1 缓存组成。L2 cache 是由所有 SM 共享的。SP 是 GPU 的 ALU,每个 SP 运行调度器分配给它的一个线程。SP 是每个线程具体执行指令所在,SP 也采用流水线设计以提高指令级并行,但它一般都是顺序执行,很少使用分支预测、动态执行等复杂技术。
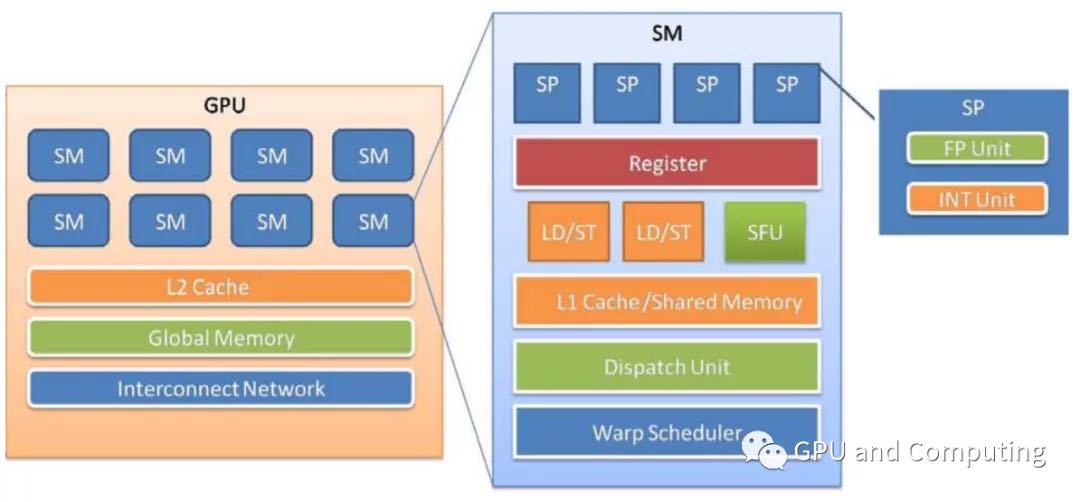
内存层级
下图为 GPU 内存层级的示意图。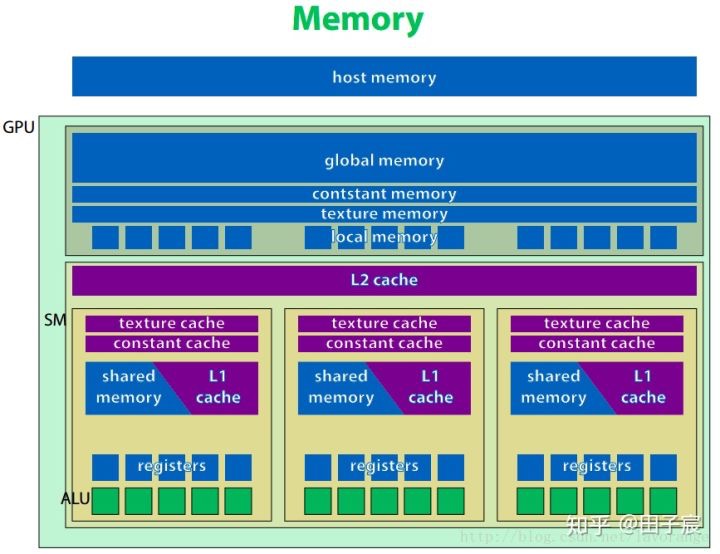
编程模型与硬件架构的对应:
- 线程(thread):SP、寄存器、local memory
- 线程块(block):SM、共享内存
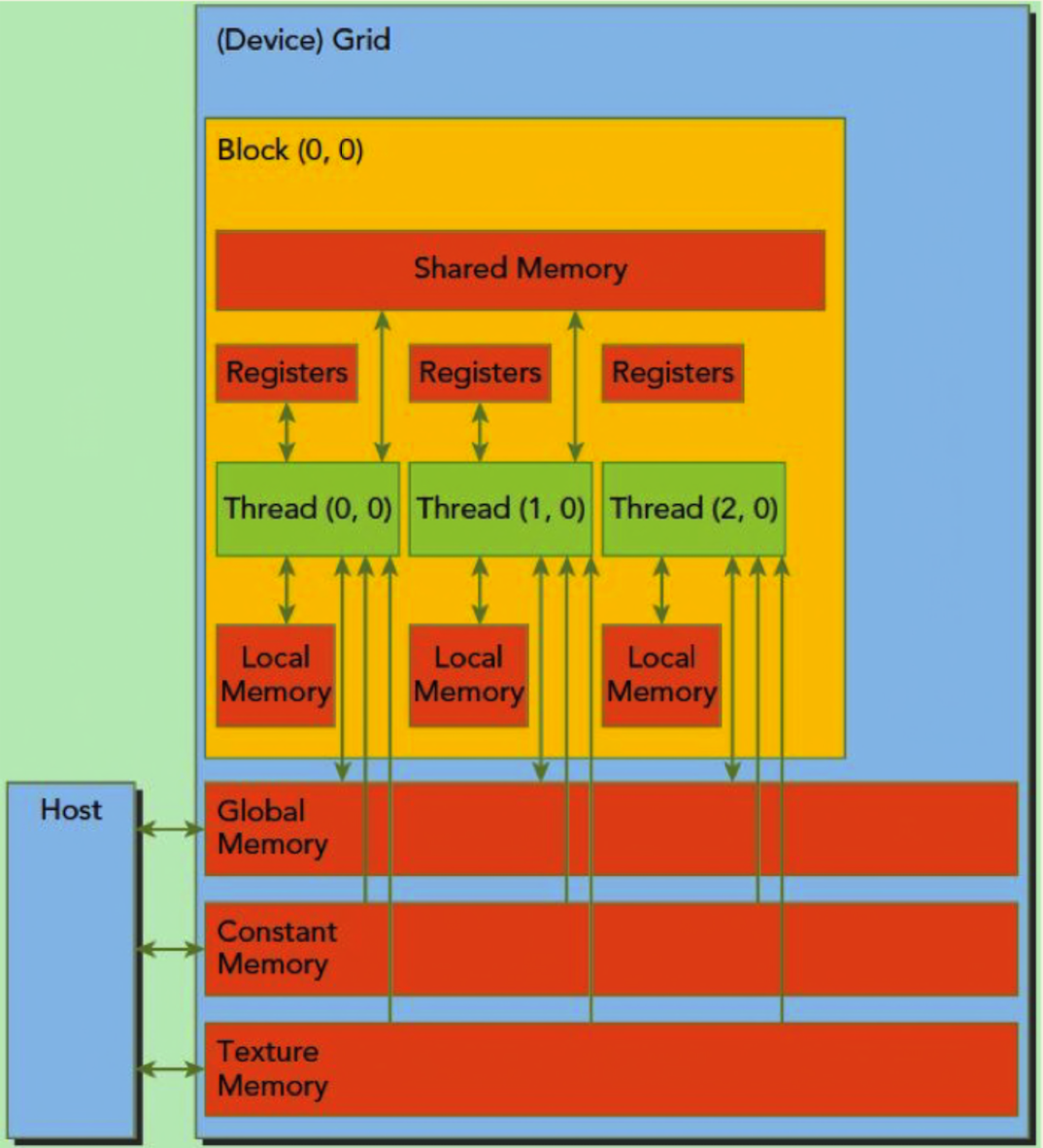
注:
- L2 cache 为所有 SM 共享,而 L1 cache 为每个 SM 内部共享
- 局部内存虽然和线程层级对应,但是其不在片内,访问速度较慢
- 共享内存只能在 SM 内共享,但是即使两个线程块被调度到了同一个 SM 内也无法互相通信
- 内核函数创建出线程块,然后由调度器分配到 SM 上去执行
- 一个线程块只能在一个 SM 上被调度,SM 可执行多个线程块
- 同一个线程块内的中线程可通过共享内存通信
- 常量内存和纹理内存对于 GPU 来说是只读的,只能被 CPU 修改
- 寄存器是每个线程私有的,如果寄存器溢出,变量就会放在每个线程私有的 local memory 中
束
处理器中最小的调度单位是束(warps),一个束包含 32 个线程。一个束中的线程会运行同样的指令。如果同一束内的线程因为条件分支导致行为不同,束会顺序执行每个分支路径,在执行某个分支时禁用其他不在此分支的线程。比如有 10 个线程执行一系列判断语句,每个线程对应一个条件分支,那么就会顺序执行这 10 个分支:执行第一个分支时禁用其他 9 个线程,然后执行第二个时禁用其他 9 个线程,以此类推。
硬件多线程
每个束的执行上下文(PC、寄存器等)被维护在片上,切换执行上下文没有消耗。在每个指令发射间,束调度器选择所有线程已准备好执行的束并且向这些线程发射下个指令。
参考
CUDA C++ 编程指引:硬件实现 | CUDA