Stable Diffusion 原理 | 深度学习算法
本文不涉及复杂的数学推导,仅介绍原理和流程。
Stable Diffusion
整体流程
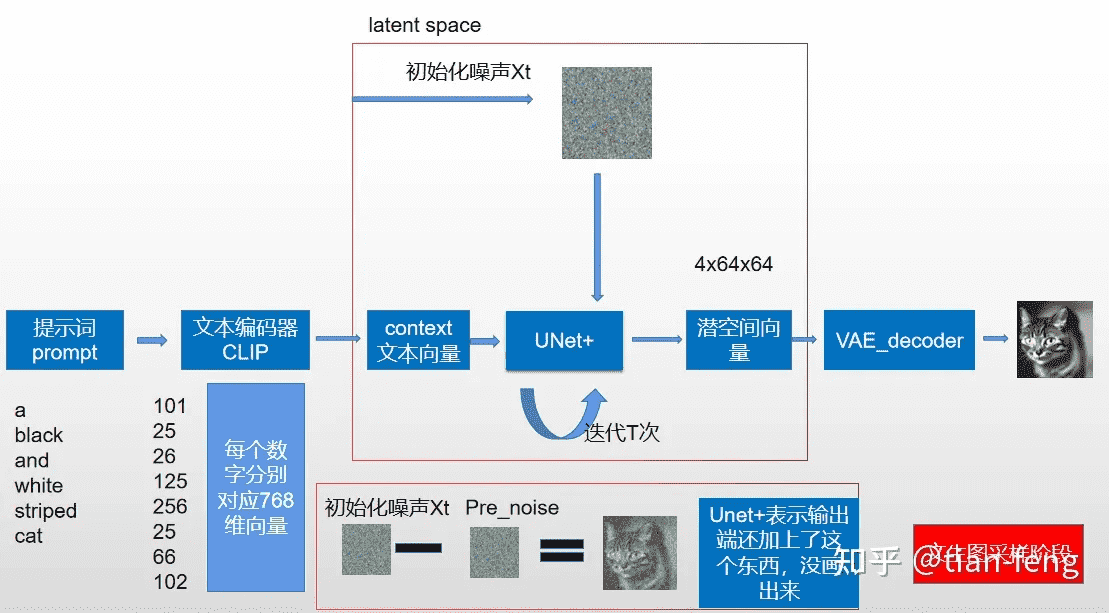
这张 Stable Diffusion 的原理图展示了文生图算法的基本处理流程:
- 提示词经过 CLIP 文本编码器被转换成 77*768(这里最多支持 75 个单词的输入,加上起止符一共是 77 个 token)的 embedding,即图中的「context 文本向量」
- Xt 是一个随机生成的 64*64 大小的纯噪声图片
- 上述两者一起被输入 UNet 中,UNet 在每一步迭代中会预测图片中的噪声,然后使用带有噪声的图减去预测出的噪声,注意这一步骤是在隐空间而非像素空间中完成的(像素空间的图片会被压缩到高维的隐空间进行处理)
- 基于 VAE 的图像解码器会将图片从隐空间中解码出来,得到 512*512 大小的图片输出
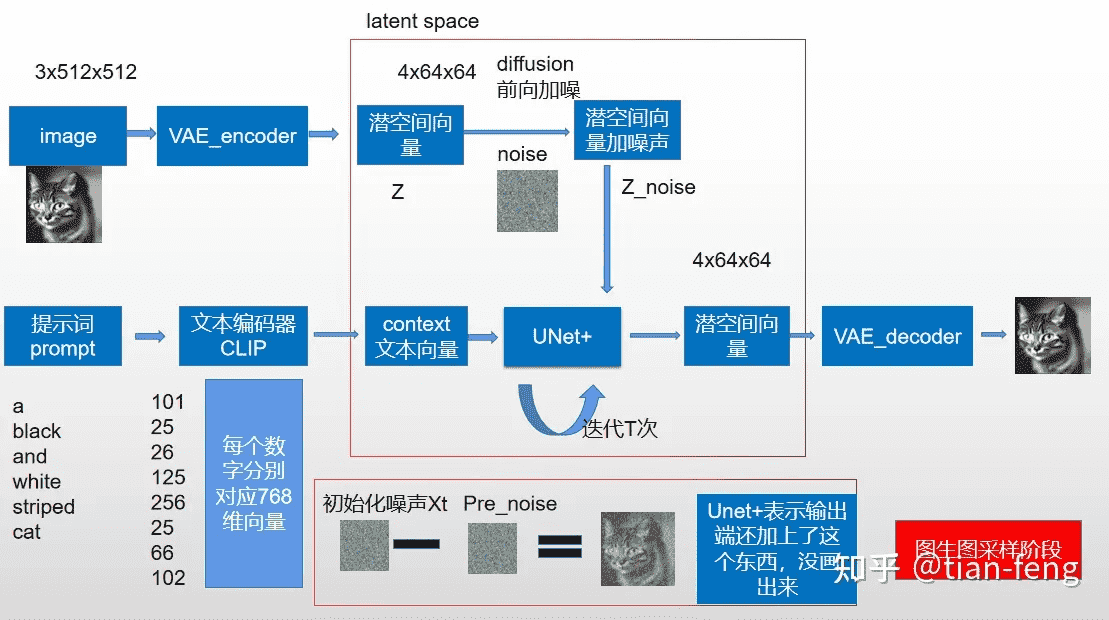
可以看出相比于文生图,图生图的算法的图片输入从纯噪声图变成了带有噪声的用户输入图。
常规的扩散模型是基于像素的生成模型,而 Stable Diffusion 是基于 latent 的扩散模型,其优势在于计算量更小,因为图像的 latent 空间要比图像 pixel 空间要小。
CLIP:文本编码
CLIP(Contrastive Language-Image Pre-training)模型包含一个图片编码器和一个文本编码器。在训练的过程中,从训练集中随机取出一张图片和一段文字(文字和图片未必是匹配的),图片编码器和文本编码器分别将其压缩成两个 embedding 向量,然后用余弦相似度来比较两个 embedding 向量的相似度,然后根据文字和图片实际的匹配程度(0 或 1)进行反向传播训练。训练 CLIP 时不仅仅要选择匹配的图文来训练,还要选择完全不匹配的图文进行训练,正负样本的数量需要平衡。
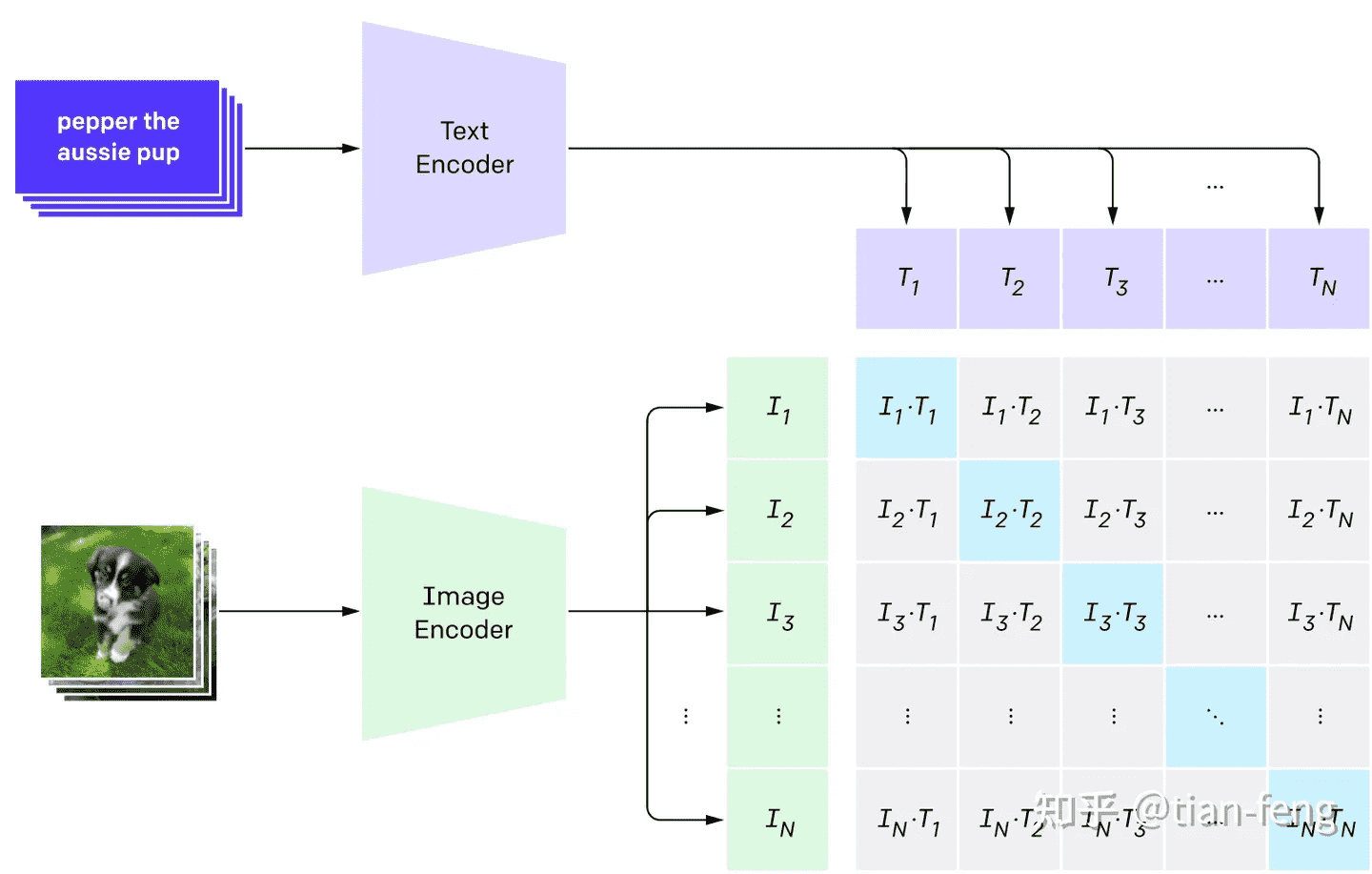
当训练完成后,图片和文本这两个原本不相干的信息就通过 CLIP 联系到了一块,二者就拥有了统一的数学表示了,二者就能够相互作用了。
VAE:图像编解码
VAE(Variational AutoEncoder)既能够将图片从像素空间压缩到隐空间,让扩散过程在隐空间中进行,又可以让图片从隐空间重建到像素空间(即图片重建),简化的过程如下图所示:
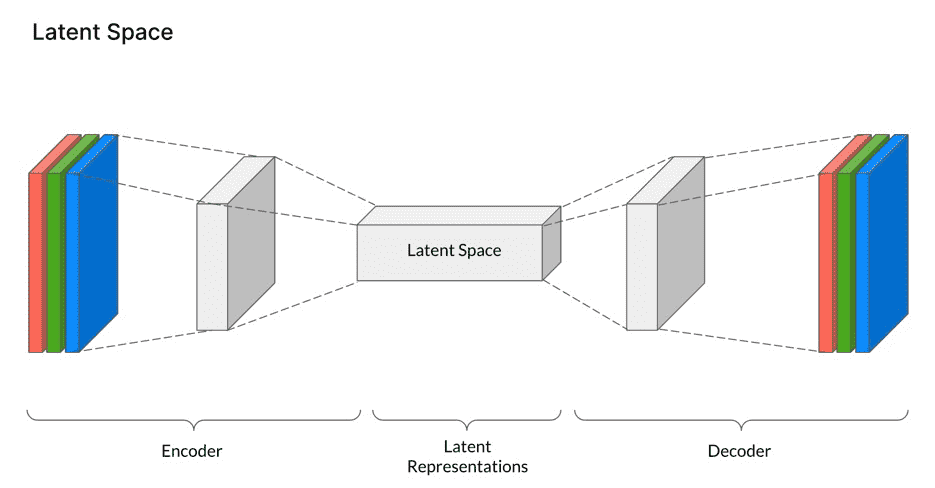
上述仅仅是从整体架构层面简单地描述了图片的隐空间与像素空间的转换与重建过程,具体的实现则用的是 VQGAN。VQGAN 使用了 VQ(Vector Quantization)技术,将连续的数据表示为离散化的向量。在 VQGAN 中,输入图像或文本先被编码为连续的向量表示,然后被映射到离散的向量空间,即是隐空间的表现形式。离散的向量空间可以大大减少的图片组成长度(相比像素),也使得能用 Transformer 来对图片进行建模(Transformer 的输入是离散序列)。
输入图片 $x$ 通过 CNN encoder 编码后得到中间特征变量 $\hat{z}$,这时就和普通的 autoencoder 不同了。普通的 autoencoder 会将 $\hat{z}$ 直接送入解码器中进行图像重建,而在 VQVAE/VQGAN 中,会将 $\hat{z}$ 进行进一步的离散化编码,具体做法为:预先生成一个离散数值的 codebook $\mathcal{Z}$,在 $\hat{z}$ 的每一个编码位置都去 $\mathcal{Z}$ 中去寻找其距离最近的 code,生成具有相同维度的变量 $z_q$。注意,这里 $\hat{z}$、$\mathcal{Z}$、$z_q$ 中的单个编码特征的维度都为 $n_z$。
对于训练过程,接下来就是在已经数值离散化的 $z_q$ 基础上使用 CNN decoder 进行解码:
$$\hat{x}=G\left(z_{\mathbf{q}}\right)=G(\mathbf{q}(E(x)))$$
训练过程将使得 $\hat{x}$ 和 $x$ 尽可能接近,训练的内容包括编码器、解码器和 codebook。
在 VQGAN 无条件生成图片的过程就用到了 Transformer,这里的思路就类似 NLP 的自回归模型「预测下一个词」的操作:从 codebook 中选一个初始的 code,然后用 Transformer 一步步推出完整的 code 序列,然后再送入前面训练好的解码器进行解码。
VQGAN 可以将图片输入编码到低维的 codebook 空间(即隐空间),然后再对 codebook 空间重建为图片的像素空间。这个过程的中间产物——隐空间——可以迁移到 attention 机制底座的下流任务,比如 Stable Diffusion。
Diffusion
正如第一节中描述的,图生图算法的应用过程涉及到了加噪和去噪两个过程,而文生图算法的应用过程则只涉及到了去噪这个过程。本节以图生图算法算法为例进行讲解。上述加噪和去噪这两个步骤分别对应前向扩散过程与反向扩散过程。

前向扩散过程逐步对输入图像加入高斯噪声,一共有 T 步,该过程将产生一系列噪声图像样本 $x_1, …, x_T$。当 $T$ 趋近于正无穷时,最终的结果将变成一张完包含噪声的图像,就像从各向同性高斯分布中采样一样。这一过程并不一定非得一步一步完成,还可以通过一个封闭形式的公式通过特定的时间步长 $t$ 直接得到 $x_t$。封闭公式的具体形式和推导过程可以参考 Diffusion 和Stable Diffusion的数学和工作原理详细解释。这样可以加速训练过程。
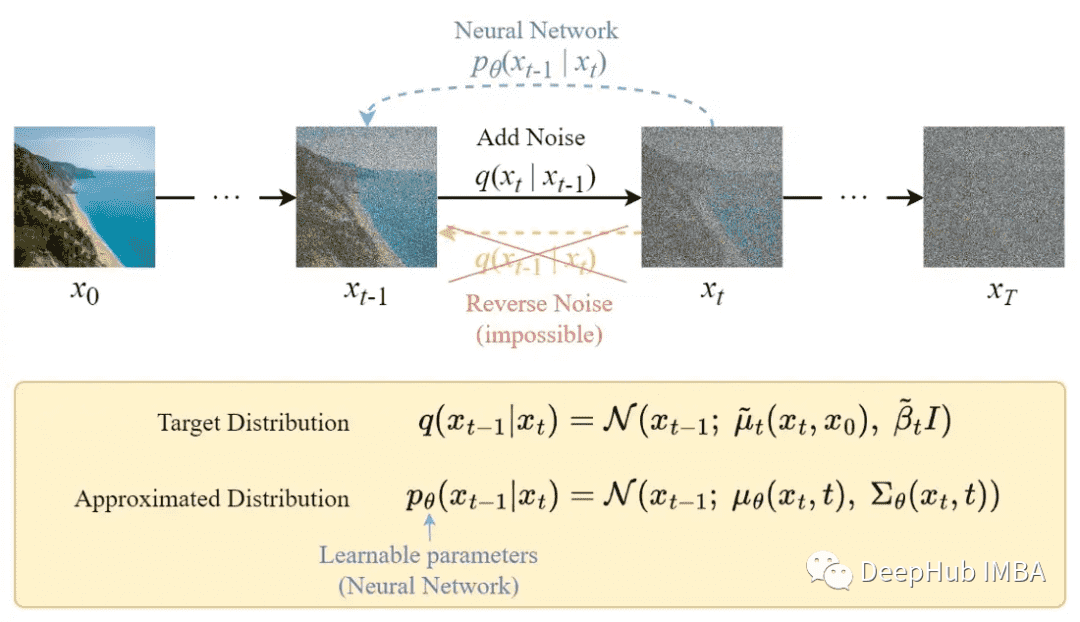
与正向过程不同,不能使用 $q(x_{t-1}|x_t)$ 来反转噪声,因为它是无法计算的。所以需要训练神经网络 $p_\theta(x_{t-1}|x_t)$ 来近似 $q(x_{t-1}|x_t)$。
下面展示一下算法的训练和应用过程:
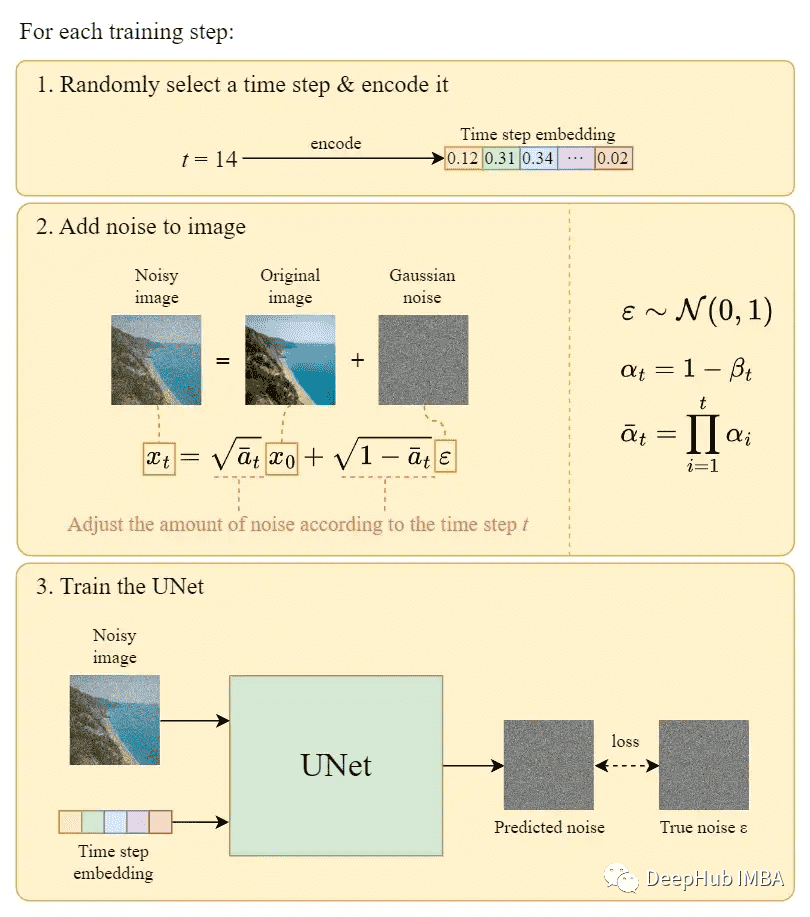
注:$\beta_t$ 是一个随着 t 增大的参数。
上图中的第 3 步就用到了采样(即去噪)过程:
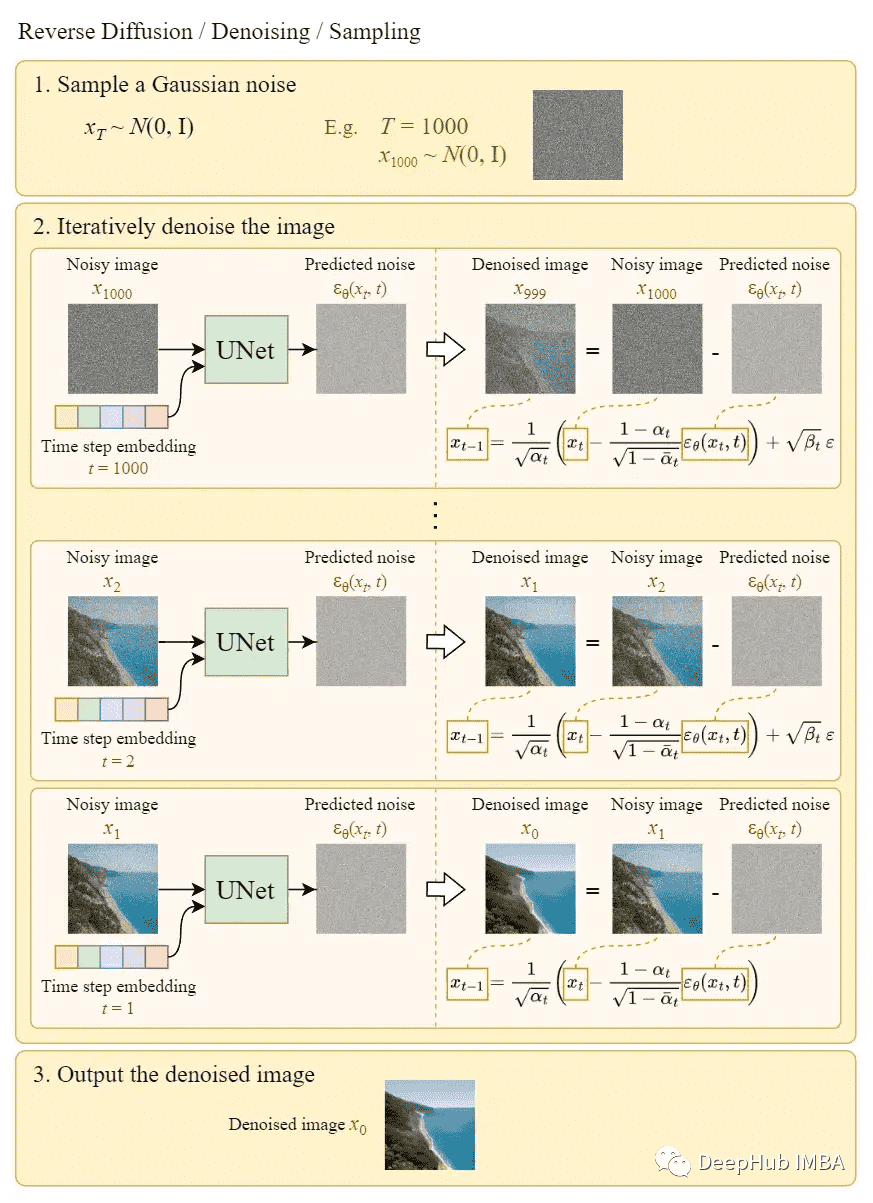
以上便是 DDPM(Denoising Diffusion Probabilistic Model)的原理。
UNet
稳定扩散模型的原名是潜扩散模型(Latent Diffusion Model),正如它的名字所指出的那样,扩散过程发生在潜在空间中。稳定扩散模型的真正强大之处在于它可以从文本提示生成图像,这是通过令 UNet 接受条件输入来完成的。在分类、检测等传统 CV 算法中,CNN 学习到的能力是「提取特征」,而在 Stable Diffusion 中,UNet 学习到的能力是「预测噪声」。
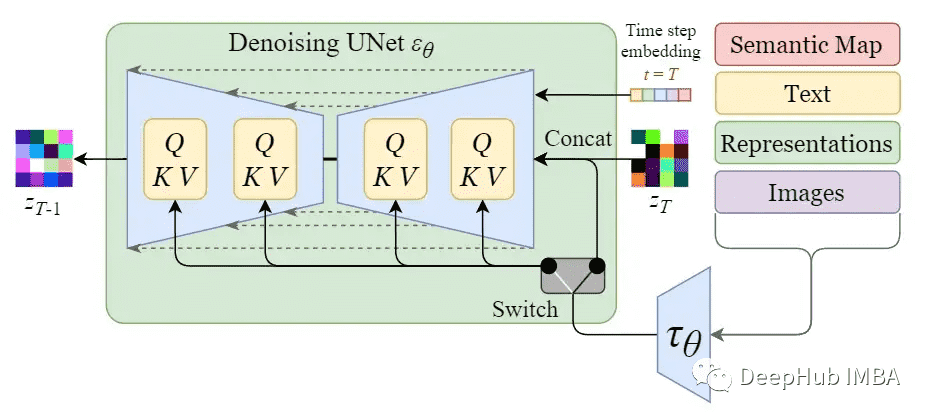
上图中的 switch 用于在不同类型的调节输入之间进行控制:
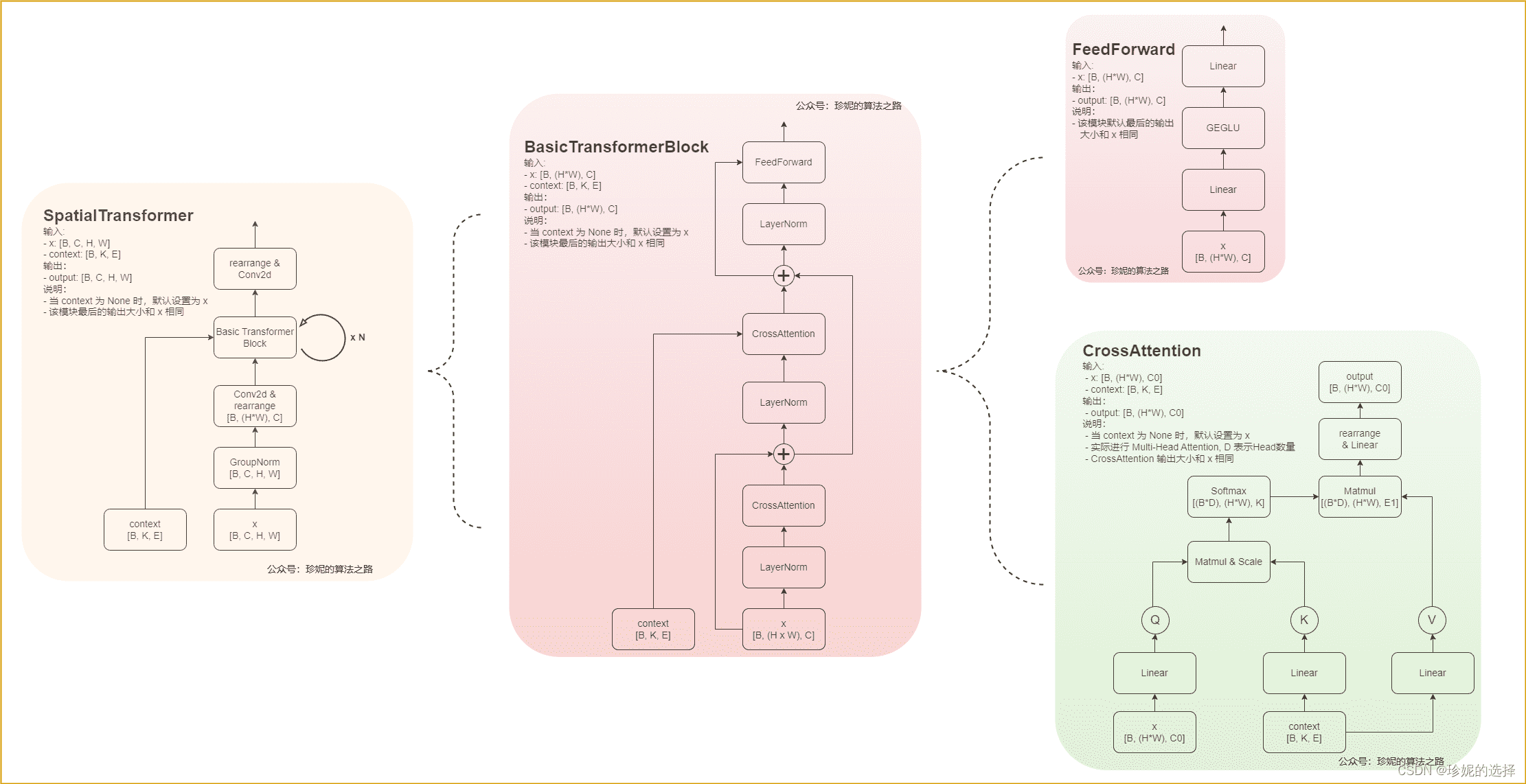
- 对于文本输入,首先使用语言模型 $\tau_{\theta}$(例如 BERT、CLIP)将它们转换为 embedding,然后通过注意力层映射到 UNet
- 对于其他空间对齐的输入(例如语义映射、图像、修复),可以使用连接来完成输入
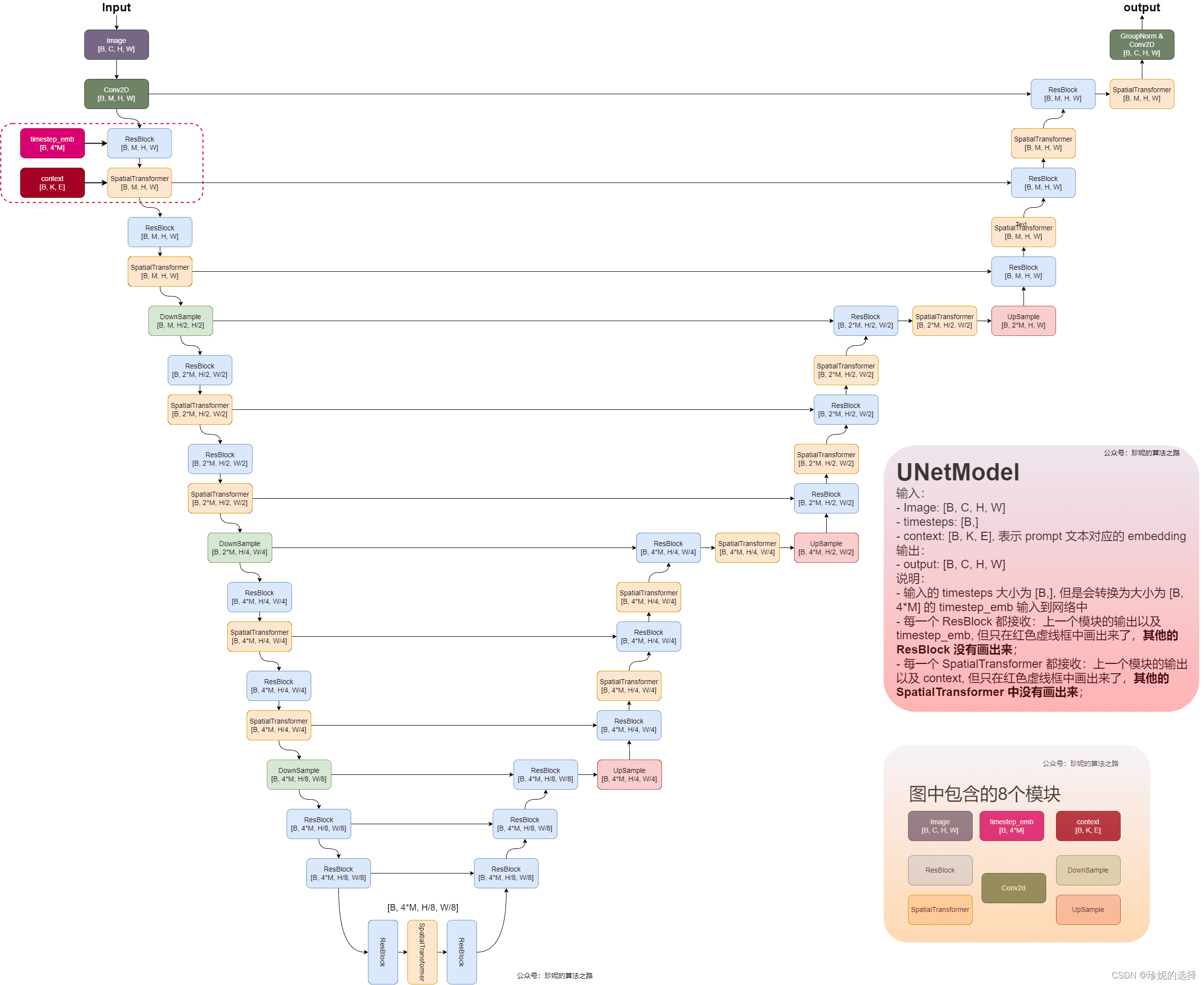
注:对于图中的尺寸标注,如果是 tensor,则是其本身的尺寸;如果是网络 block,则是其输出 tensor 的尺寸。
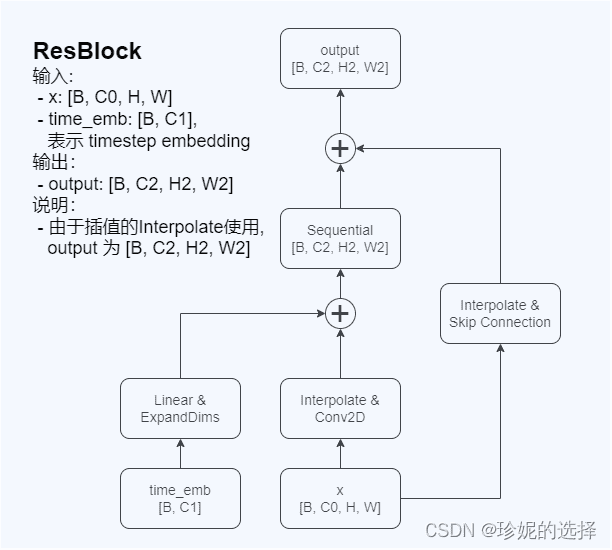
1. ResBlock
2. SpatialTransformer
3. UNet 跳步连接
这里的 UNet 同样使用了跳步连接,具体连接方式如下:
4. 时间步 embedding
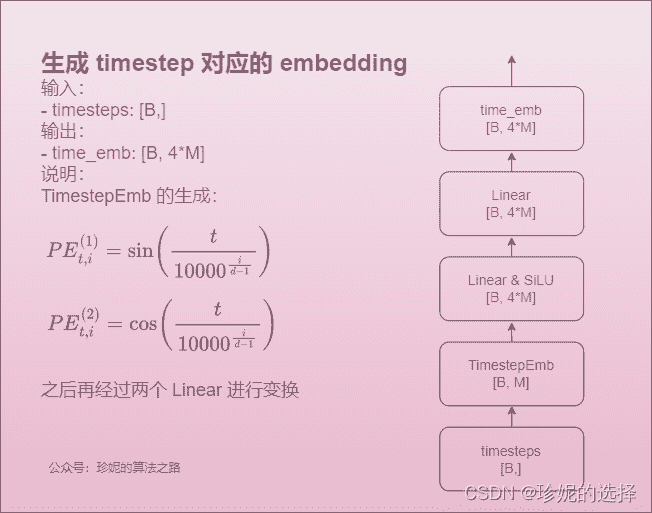
这里的时间步采用了 Transformer 中的位置编码相同的编码方案:
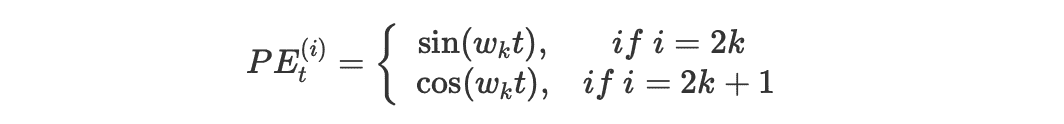
其中:
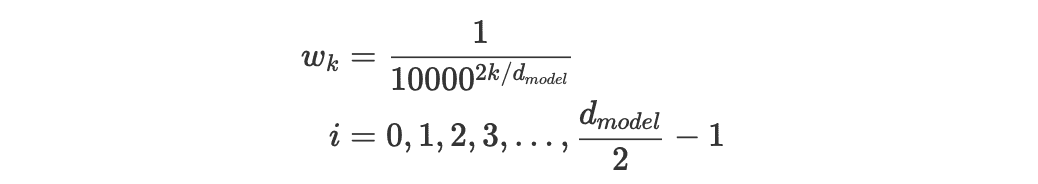
解释下几个符号的含义:
- $t$ 是某次输入的时间步在整个时间步序列中的实际位置(例如第 n 个 时间步 t=n)
- $PE_{t}$ 是这个时间步的编码向量,$PE_t^{(i)}$ 表示这个向量里的第 i 个元素
- $d_{model}$ 是这个时间步编码向量的维度(Transformer 中是 512)
SDXL
整体架构
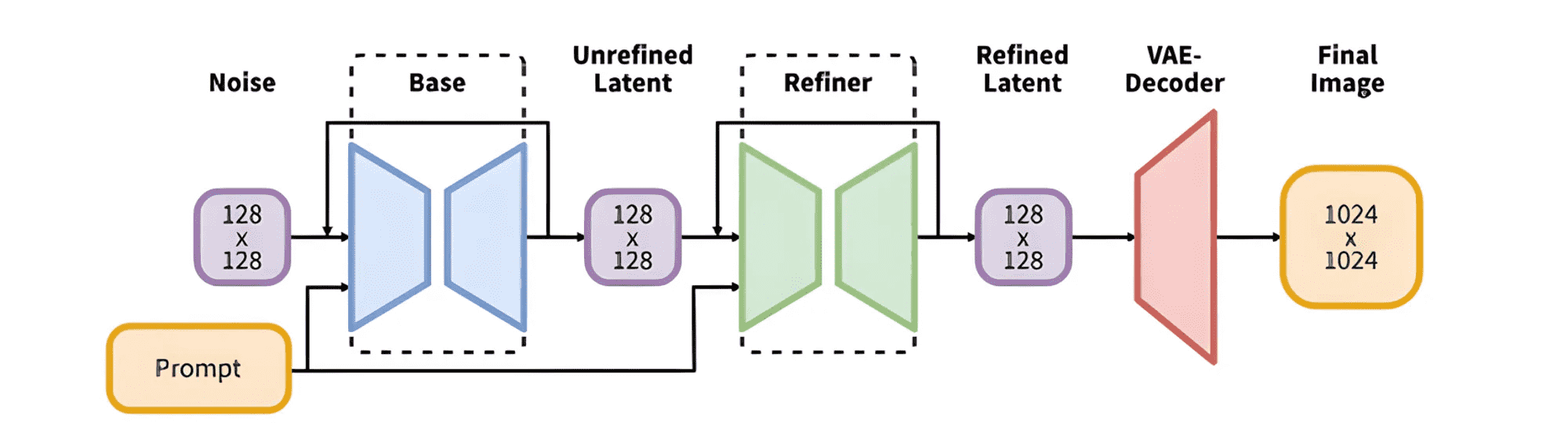
和标准版 Stable Diffusion 相比,SDXL 是一个二阶段的级联扩散模型,包括 base 模型和 refiner 模型。其中 base 模型的主要工作和 Stable Diffusion 一致,具备文生图、图生图等能力。在 base 模型之后,级联了 refiner 模型,对 base 模型生成的隐空间图像进行精细化,其本质上是在做图生图的工作。除了结构上的变化,SDXL 还使用了更大的 backbone,
CLIP
SDXL 与之前的系列相比,使用了两个 CLIP 文本编码器,分别是OpenCLIP ViT-bigG 和 OpenAI CLIP ViT-L,从而大大增强了模型对文本的提取和理解能力。
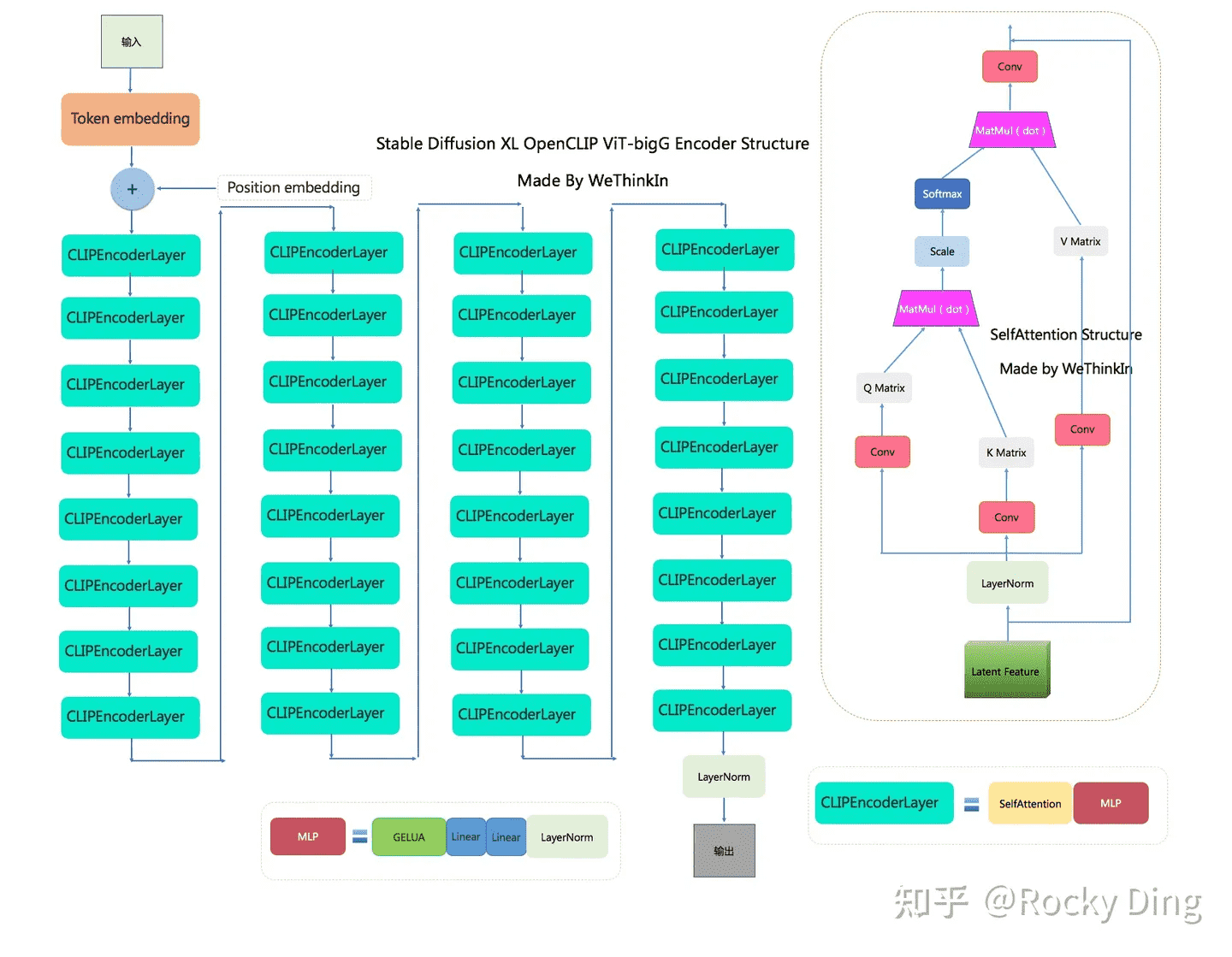
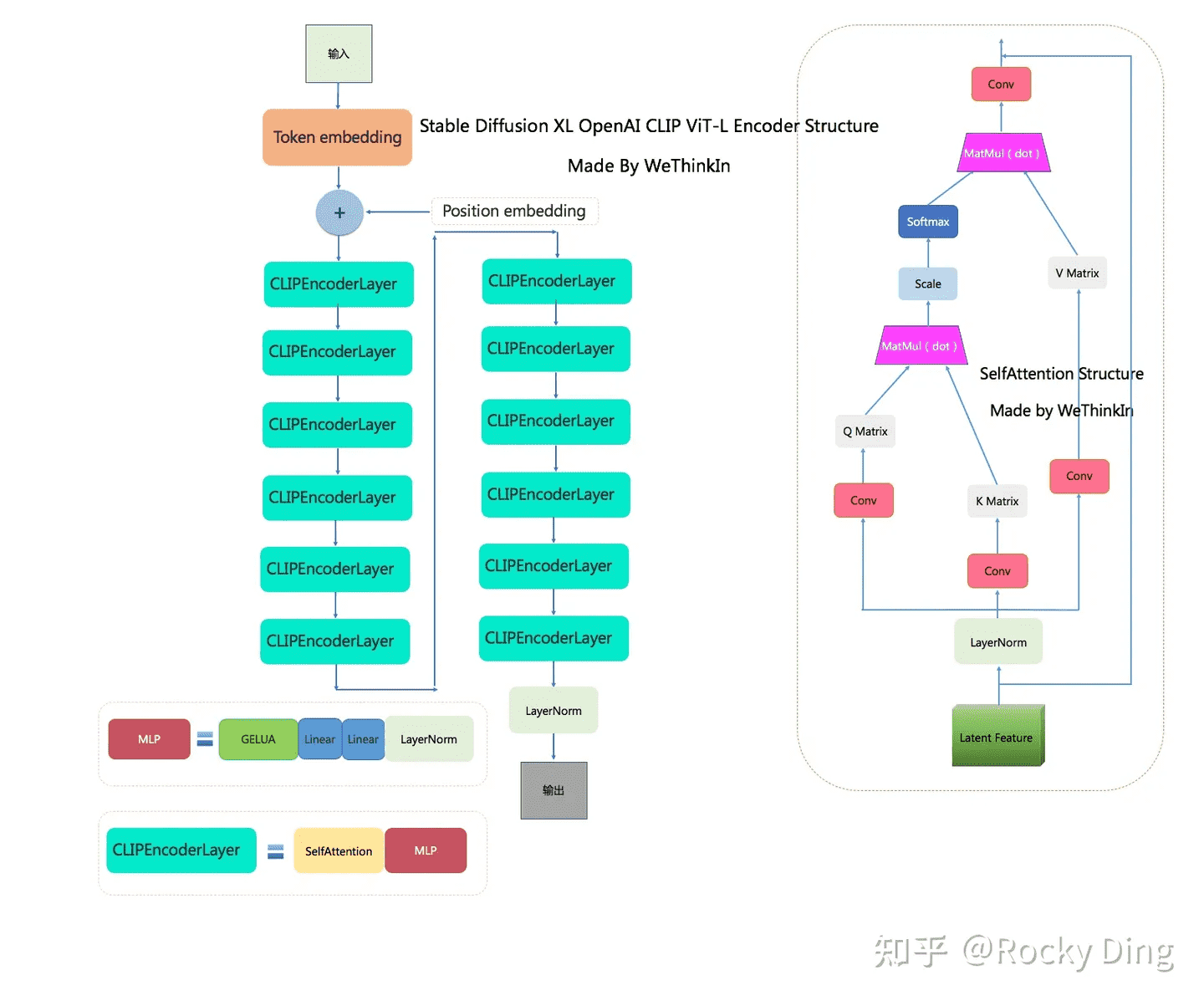
由上面两个结构对比可知,OpenCLIP ViT-bigG 的优势在于模型结构更深,特征维度更大,特征提取能力更强,但是其两者的基本 CLIPEncoder模块是一样的。
传统深度学习中的模型融合类似,SDXL 分别提取两个文本编码器的倒数第二层特征,并进行 concat 操作。这里提取倒数第二层是因为倒数第一层的特征之后就是 CLIP 的对比学习任务,所以倒数第一层的特征可能部分丢失细粒度语义信息。
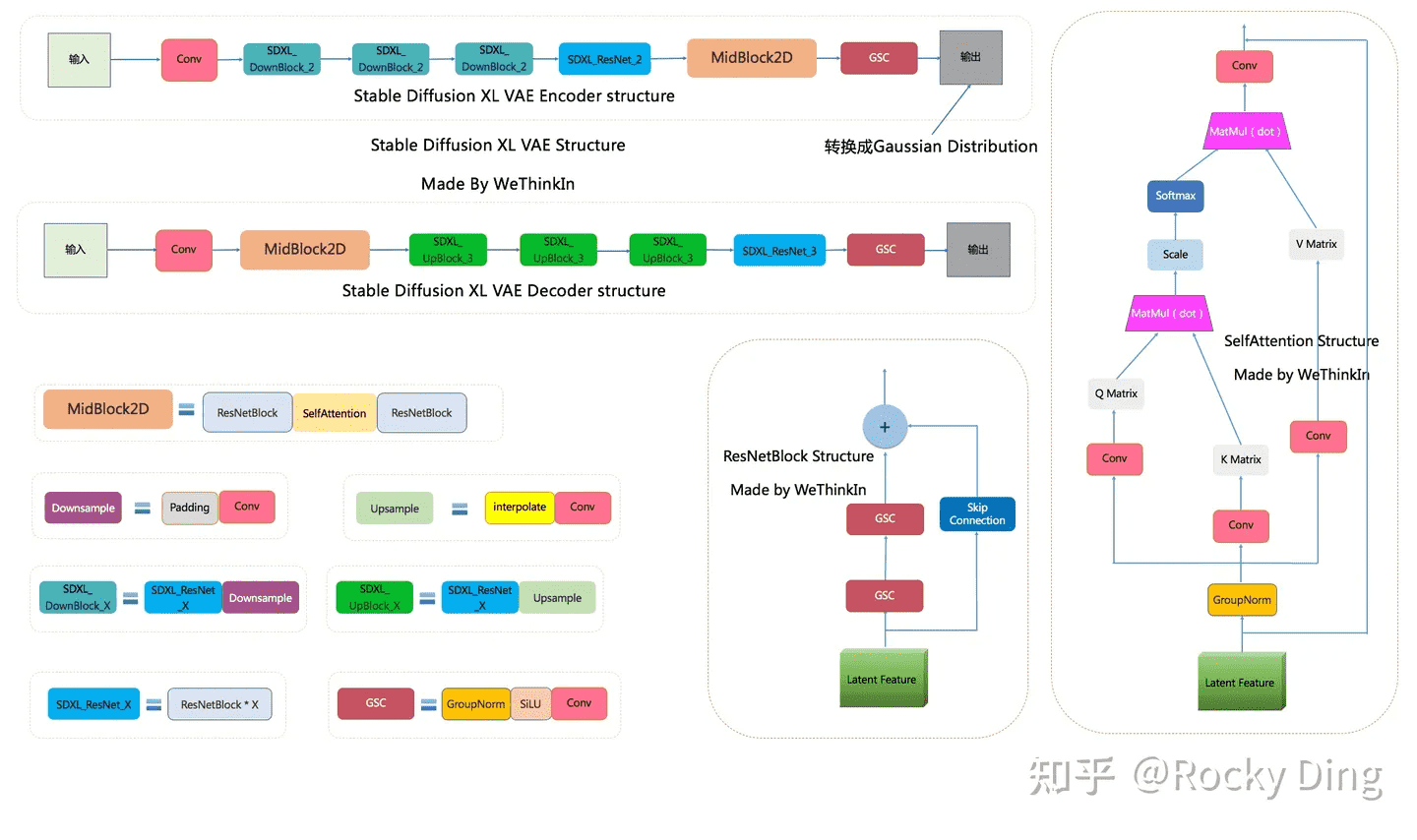
VAE
SDXL 使用了和之前一样的 VAE 结构,但在训练中选择了更大的 batch size(9 -> 256)。除了提取隐空间特征和图像的像素级重建外,VAE 还可以改进生成图像中的高频细节,小物体特征和整体图像色彩。
base 模型
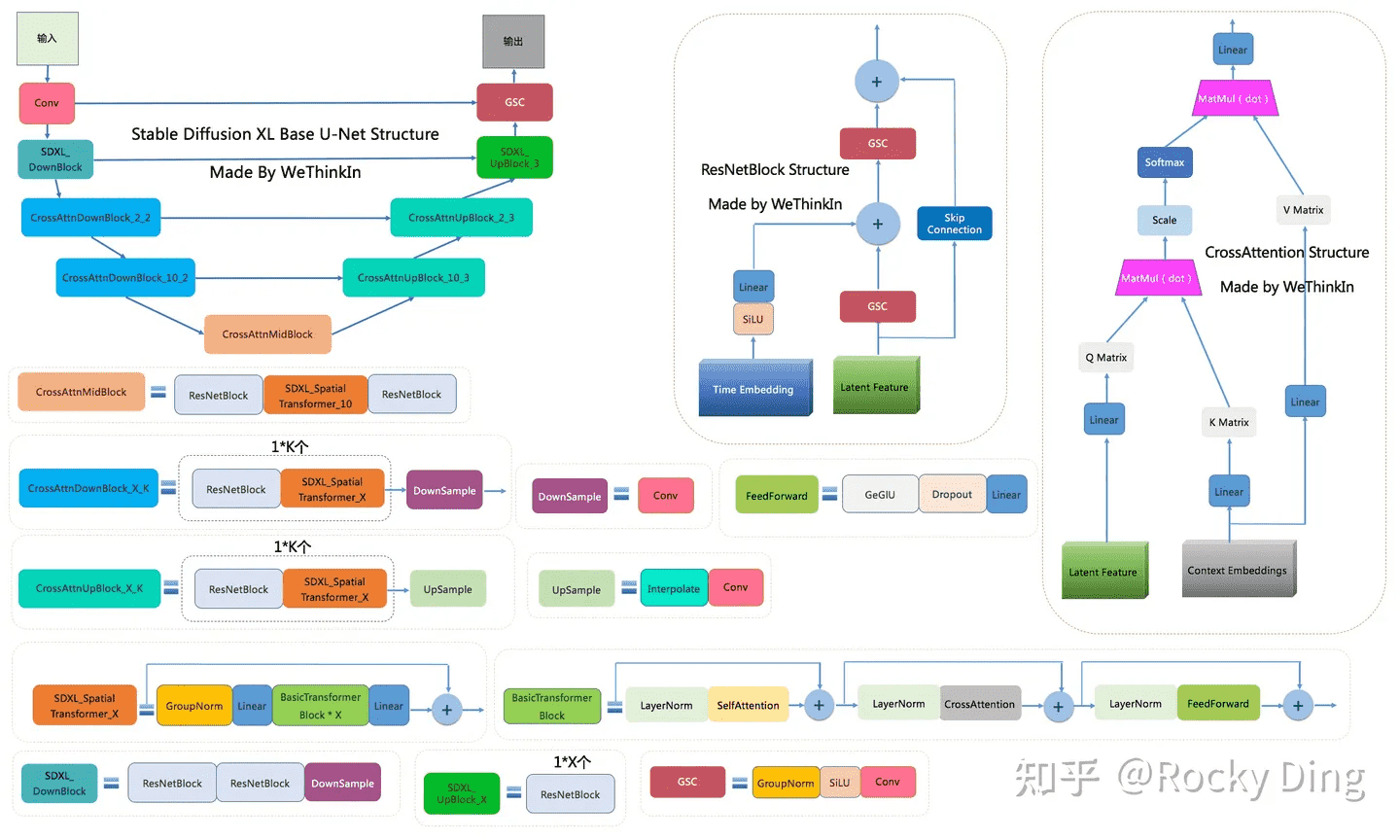
上图中包含 SDXL base UNet 的十四个基本模块,这里只对其中部分模块进行额外说明:
- DownSample 模块:SDXL base UNet 中的下采样组件,使用了
conv2d(kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))进行采下采样 - SelfAttention 模块:SelfAttention 模块的整体结构与 CrossAttention 模块相同,这是输入全部都是图像信息,不再输入文本信息。
- BasicTransformer Block 模块:由 LayerNorm + SelfAttention + CrossAttention + FeedForward 组成,是多个注意力模块的级联,并且每个注意力模块都是一个「残差结构」。通过加深网络和多注意力模块机制,大幅增强模型的学习能力与图文的匹配能力。
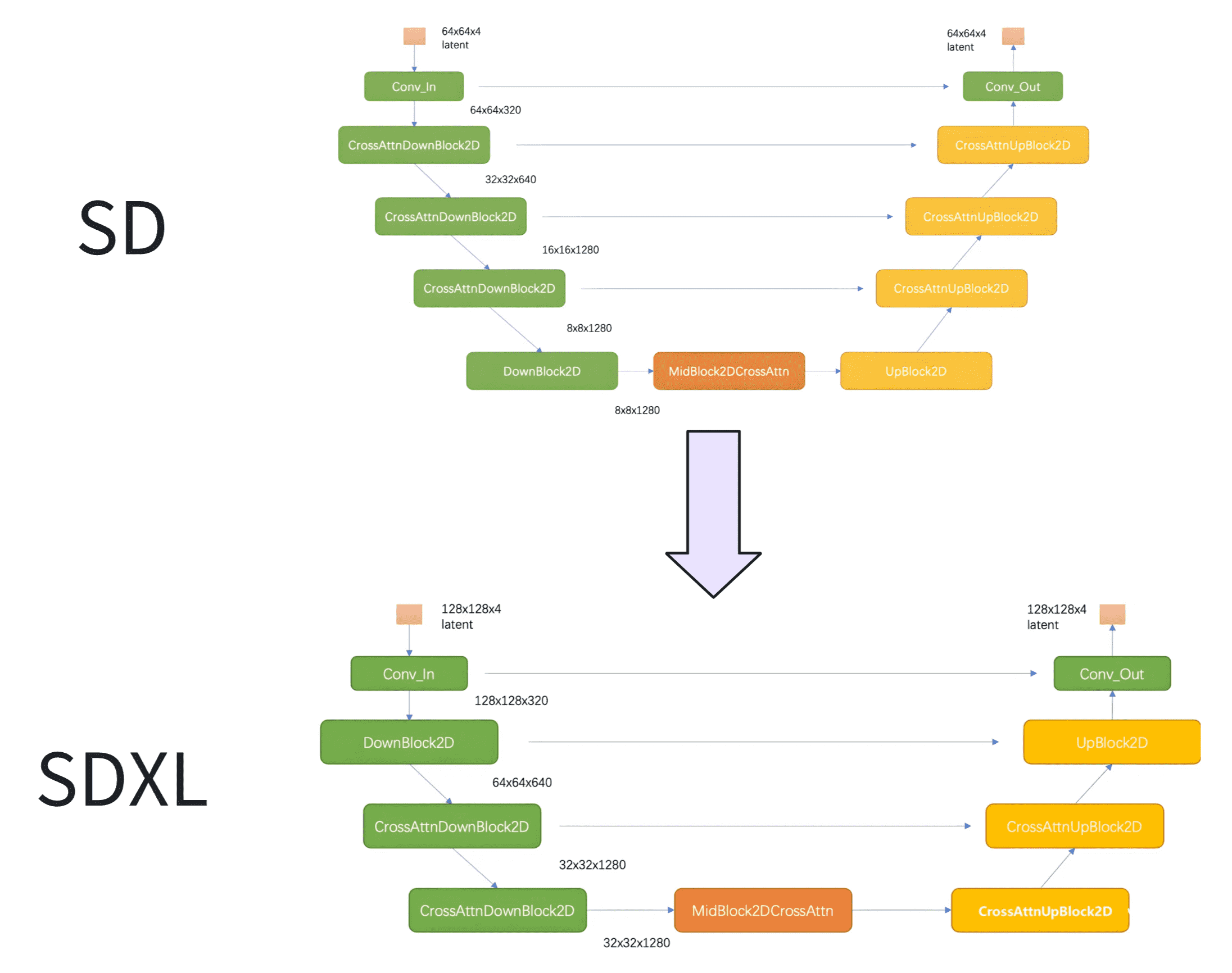
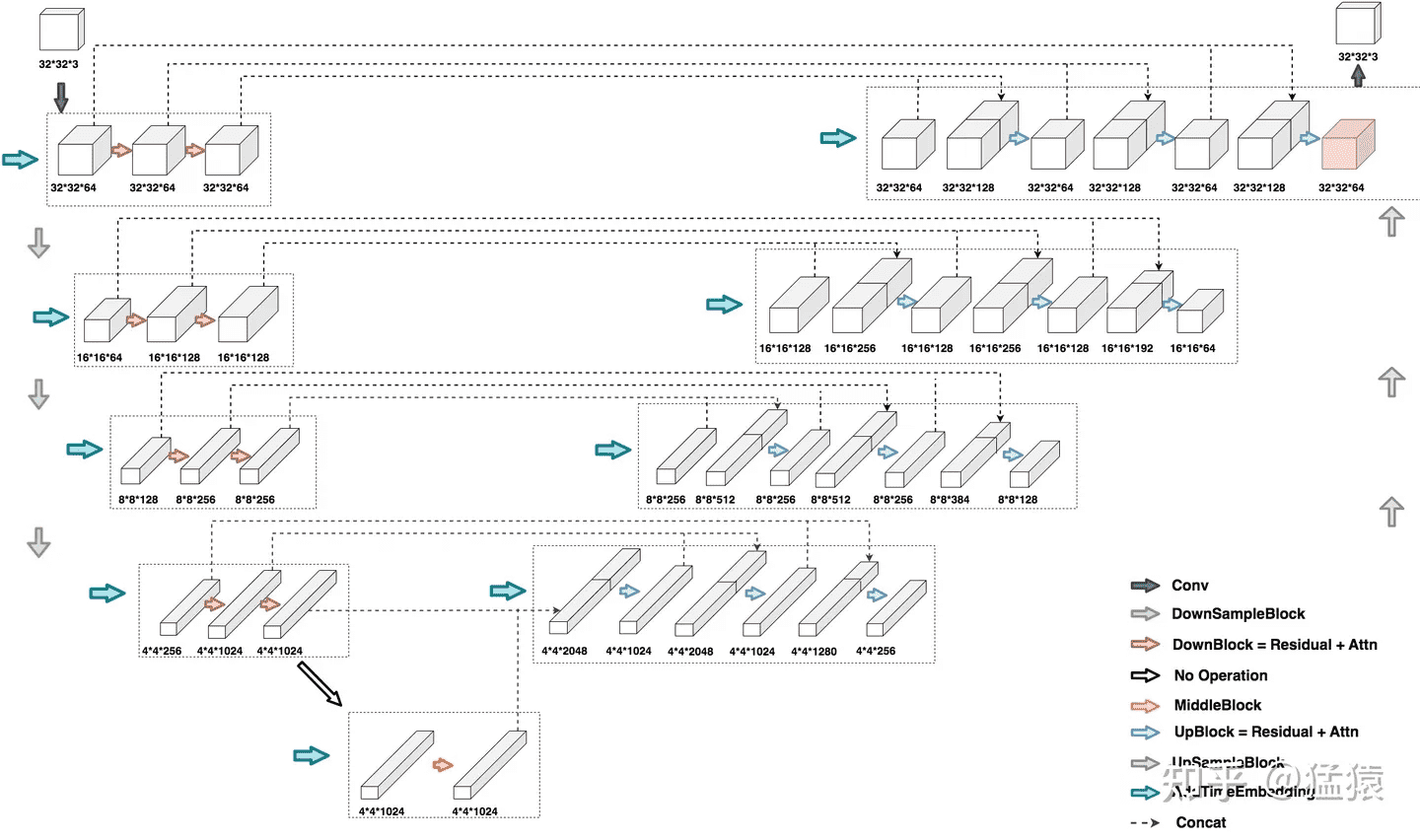
和之前的版本相比,SDXL 的第一个 stage 采用的是普通的 DownBlock,而不是基于 attention 的 CrossAttnDownBlock。此外,SDXL 只用了 3 个 stage,只进行了两次 2x 下采样,而之前的 SD 使用 4 个 stage,包含 3 个 2x 下采样。
SDXL 参数量的增加主要是使用了更多的 transformer blocks,在之前的版本,每个包含 attention 的 block 只使用一个 transformer block(self-attention -> cross-attention -> feed forward),但是 SDXL 中 stage2 和 stage3 的两个 CrossAttnDownBlock 中的 transformer block 数量分别为 2 和 10,并且中间的 CrossAttnMidBlock 的 transformer blocks 数量也为 10。
SDXL 中的文本控制信息由两个文本编码器提供,通过 cross-attention 嵌入,作为 K 矩阵和 V 矩阵。与此同时,图片的隐空间特征作为 Q 矩阵。
refiner 模型
refiner 模型的主要工作是对隐空间特征进行小噪声去除和细节质量提升。refiner 模型和 base 模型一样是基于隐空间的扩散模型,也采用了 encoder-decoder 结构,和 base 兼容同一个 VAE 模型,不过 refiner 模型的文本编码器只使用了 OpenCLIP ViT-bigG。在 SDXL 推理阶段,输入一个 prompt,通过 VAE 和 base 模型生成隐空间特征,接着给这个特征添加一定的噪音,在此基础上再使用 refiner 模型进行去噪,这样可以提升图像的整体质量与局部细节。

ControlNet
Stable Diffusion 是通过引入 CLIP 模型对文本信息的编码,ControlNet 则通过直接使用 Stable Diffusion 的 UNet 作为图像编码器,以此引入图像控制信息。
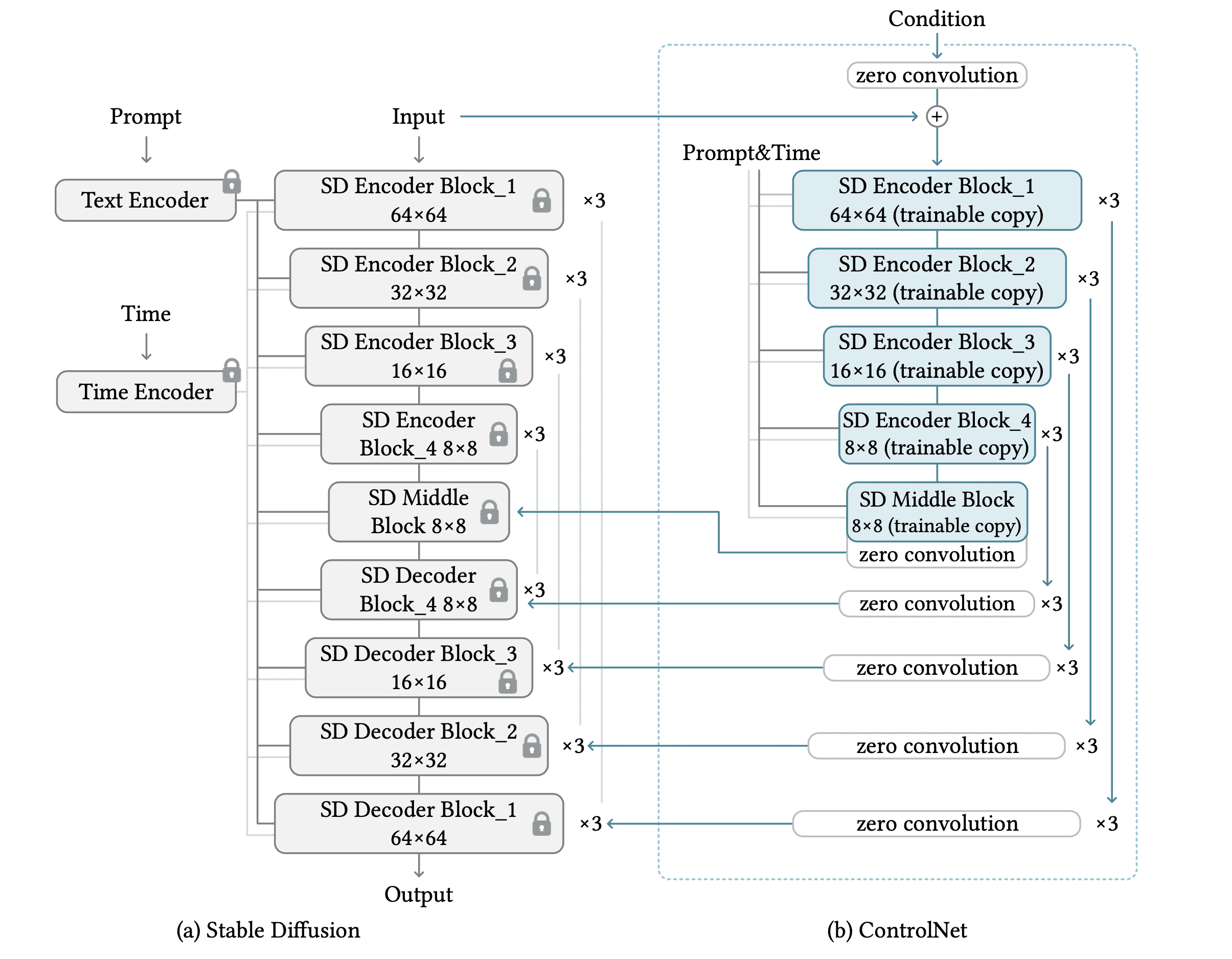
左图是 Stable Diffusion 的 UNet,右图是增加的 ControlNet。ControlNet 的网络结构是左侧 UNet 的一个镜像,只包含 encoder 部分和 middle 部分,并且为每一个 block 的输出加上了一个 1x1 的零卷积层。零卷积层是带有零初始化权重和偏差的 1x1 卷积层,在训练开始的时候,权重为零,此时 ControlNet 对原网络没有影响。在训练过程中,零卷积将逐渐变成具有非零权重的常规卷积层。
ControlNet block 的输出会和对应的 UNet encoder/middle block 的输出元素相加,然后一起通过 skip connection 输入给对应的 UNet decoder block,但是两者输出加在一起的结果并不会传递给下一层的 UNet encoder/middle block,只会直接输入给对应的 UNet decoder block。
ControlNet 是一个任务相关的端到端方法,即对于每一种控制类型都要训练一个特定的 ControlNet,比如线图控制、深度图控制、姿态控制等等。这样有好处也有坏处:单独看一个场景,拥有使用简单、训练成本低等优点;但是如果面对一个多场景反而变得麻烦,每一个细分场景都要训练和维护一个模型,成本高昂,也不易用。
LoRA (Low-Rank Adaptation)
Stable Diffusion 的参数量很大,如果全量参数进行 fine-tune 成本巨大,当遇到一些下游细分任务时,全参训练性价比不高,同时这些下游细分任务的域比较好约束,在这种情况下,LoRA可以在使用大模型适配下游任务时只需要训练少量的参数即可达到一个很好的效果。


可以在任何模型层上做这样的操作,比如 Transformer 中的 cross-attention 层的权重、MLP 层的权重、embedding 层de权重。在原始论文中只对 cross-attention 层的权重做了低秩适配。
LoRA 大幅降低了 Stable Diffusion 模型训练时的显存占用,因为并不优化主模型,所以主模型对应的优化器参数不需要存储。并且计算量没有明显变化,虽然 LoRA 是在主模型的全参梯度基础上增加了「残差」,但是节省了主模型优化器更新权重的过程。由于可以通过 $W=W+\frac\alpha rBA$ 把 LoRA 参数和主模型参数进行合并,所以推理过程的成本也没有增加。
这里对比一下 ControlNet 和 LoRA:
- ControlNet:使用图像和文本输入进行微调和生成
- LoRA:仅使用文本输入进行微调和生成
LCM (Latent Consistency Model)
扩散模型的奠基性工作之一 DDPM 定义了两个过程:前向过程对数据添加噪声,逆向过程利用模型逐渐去除噪声,最终得到干净的图片。从连续时间的角度上看,扩散模型的去噪问题可以理解为求解一个增广概率流常微分方程的过程(具体推推导可以参考原论文)。
传统的扩散模型采用数值方法对常微分方程进行迭代求解,虽然可以通过设计更加精确的求解器(DDIM、DPM-Solver、DPM-Solver++ ……)来改善每一步的求解精度,从而减少所需要的迭代次数,但是这些方法中最好的也仍然需要 10 步左右的迭代步数来得到足够好的求解结果。
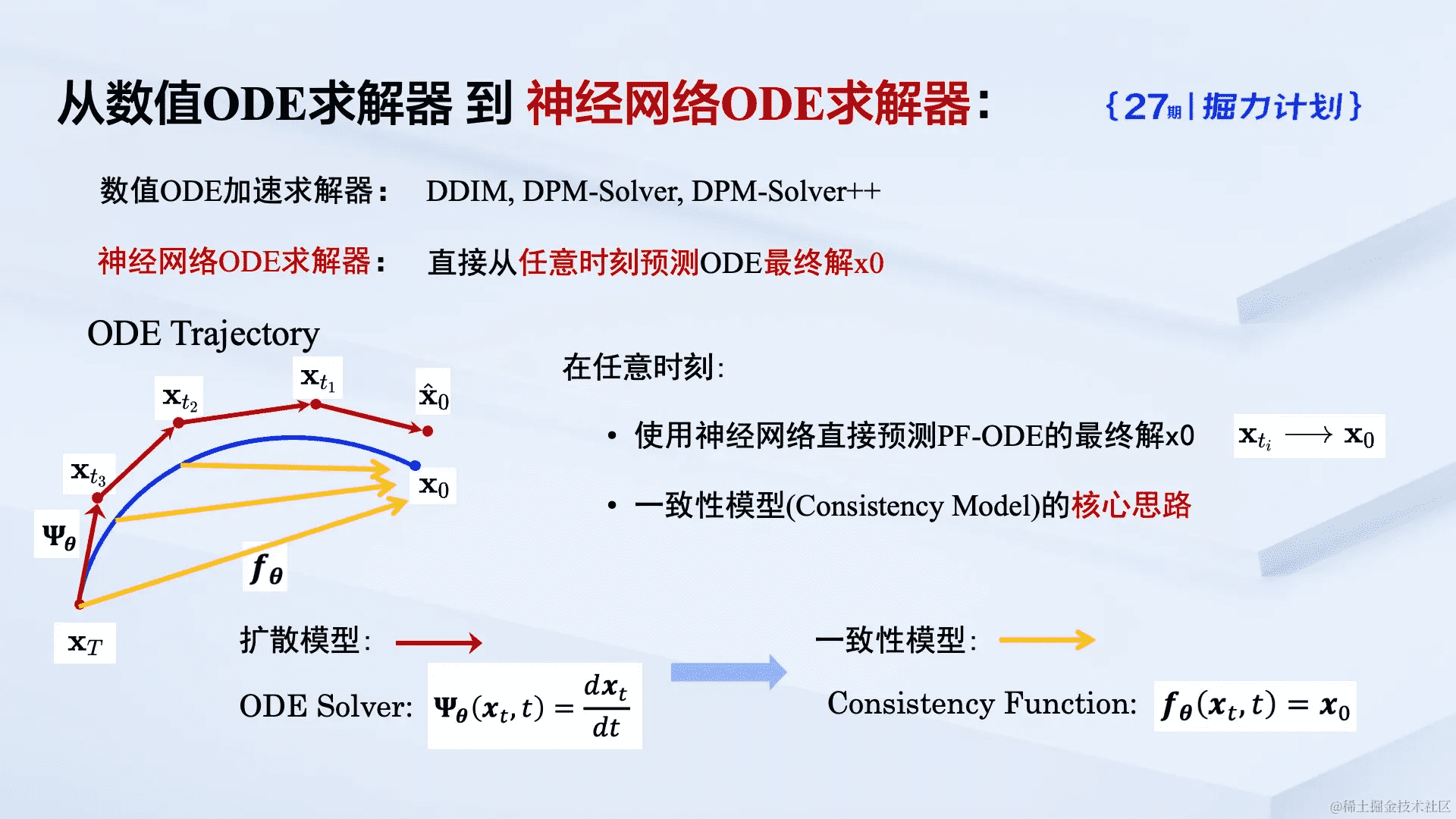
不同于迭代求解这一常微分方程,潜在一致性模型(LCM)将传统的数值求解器转化为基于神经网络的求解器直接预测方程的最终解,从而在理论上能够在单步内生成图片。
与先前的 LDM 相比,LCM 在生成图像的速度上取得了质的飞跃。传统的 LDM,如 Stable Diffusion,需要经过多步迭代来生成一张图片,而 LCM 大幅减少了这一迭代次数。实际应用中,LCM 仅需约 4 步迭代即可生成高质量图像,比传统 LDM 模型至少快五倍。
为了训练得到潜在一致性模型,可以通过对于预训练的扩散模型(例如 Stable Diffusion)进行参数微调,这一过程被称为 LCD(Latent Consistency Distillation)。
LCM-LoRA
由于潜在一致性模型的蒸馏过程可以被视作是对于原有的预训练模型的微调过程,从而可以使用 LoRA 等高效微调技术来训练潜在一致性模型。LCM 的作者团队在 LCM 的基础上,又进一步提出了 LCM-LoRA。
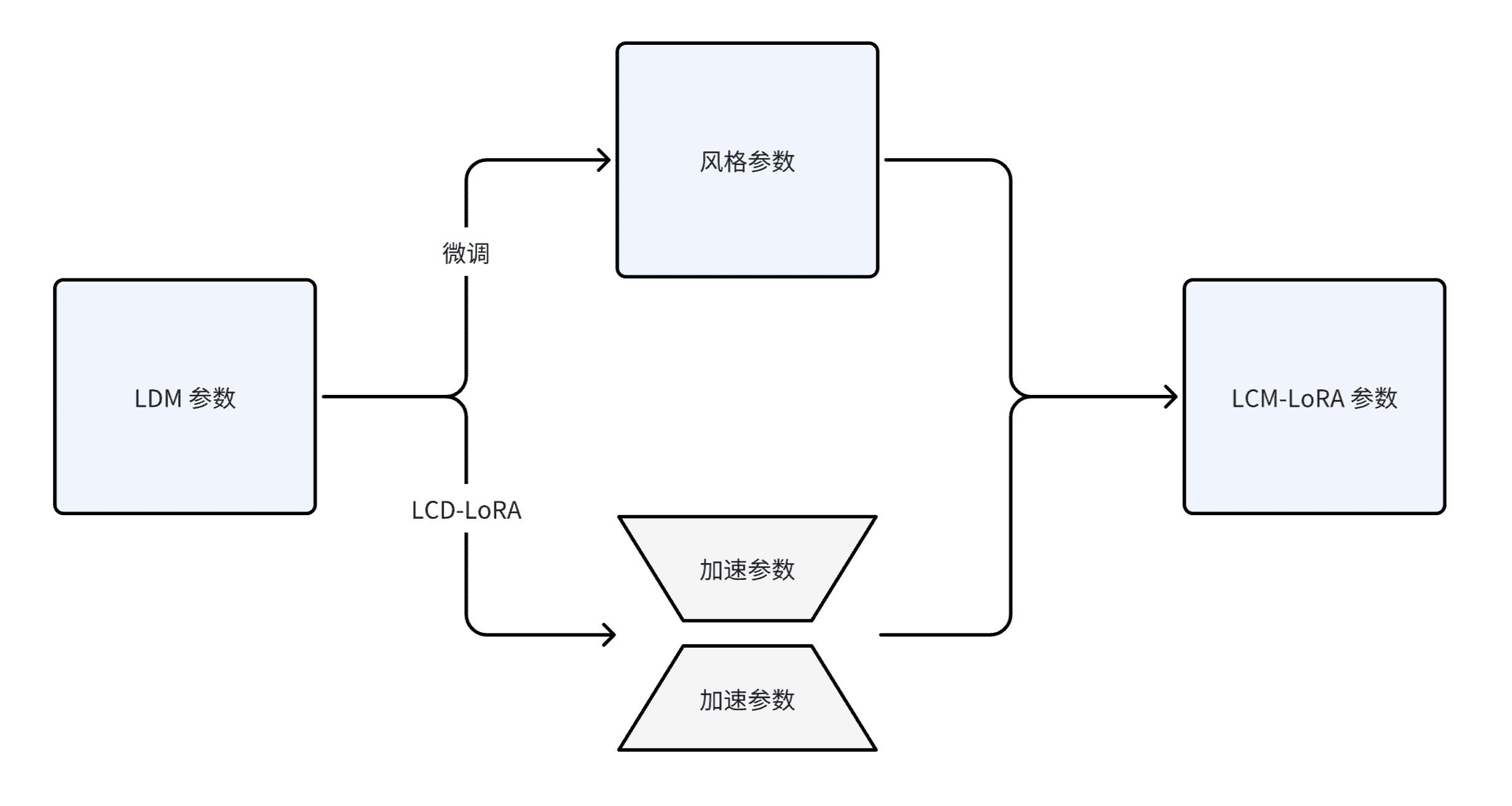
除了使用 LoRA 技术来让蒸馏过程更加高效,作者还发现了由此训练得到的 LoRA 参数可以被作为一种泛用的加速模块,直接与其他 LoRA 参数结合:只需要将在特定风格数据集上微调得到的「风格参数」与经过 LCD 得到的「加速参数」进行简单的线性组合,就可以获得兼具快速生成能力和特定风格的 LCM 模型。这一发现为现有开源社区内已存在的大量开源模型提供了极强的助力,使得这些模型甚至可以在无需任何额外训练的情况下享受潜在一致性模型带来的加速效果。
LCM-LoRA 可以起作用主要是因为两点:
- LDM 的 latent vector 在不同的 diffusion step 中是一致的,这意味着它们不会随着噪声的添加或去除而发生太大变化,也就是说 latent vector 可以重复用于多个 diffusion step,从而减少计算量和内存占用
- LDM 的 latent vector 可在不同的微调模型之间转移,这意味着它们可以为不同的任务生成图像,也就是说 latent vector 可以由多个模型共享,从而实现通用加速
参考
High-Resolution Image Synthesis with Latent Diffusion Models
The Illustrated Stable Diffusion
零基础读懂Stable Diffusion(II):怎么训练
AI绘画Stable Diffusion原理之VQGANs/隐空间/Autoencoder
详解VQGAN(一)| 结合离散化编码与Transformer的百万像素图像生成
Diffusion 和Stable Diffusion的数学和工作原理详细解释
深入浅出完整解析Stable Diffusion XL(SDXL)核心基础知识
Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference
LCM-LoRA: A Universal Stable-Diffusion Acceleration Module
Stable Diffusion 原理 | 深度学习算法