05 内存模型和原子操作 | 《C++ Concurrency In Action》笔记
本系列笔记参考《C++ Concurrency in Action, 2nd Edition》及其中文翻译。
原子操作和原子类型
标准原子类型
标准原子类型定义在头文件
只有 std::atomic_flag 类型不提供 is_lock_free()。该类型是一个简单的布尔标志,并且在这种类型上的操作都是无锁的。当有一个简单无锁的布尔标志时,可以使用该类型实现一个简单的锁,并且可以实现其他基础原子类型。剩下的原子类型都可以通过特化 std::atomic<> 得到,并且拥有更多的功能,但不可能都是无锁的。主流平台上,原子变量都是无锁的内置类型(例如 std::atomic
标准原子类型的备选名和与其相关的 std::atomic<> 特化类:
| 原子类型 | 相关特化类 |
|---|---|
| atomic_bool | std::atomic<bool> |
| atomic_char | std::atomic<char> |
| atomic_schar | std::atomic<signed char> |
| atomic_uchar | std::atomic<unsigned char> |
| atomic_int | std::atomic<int> |
| atomic_uint | std::atomic<unsigned> |
| atomic_short | std::atomic<short> |
| atomic_ushort | std::atomic<unsigned short> |
| atomic_long | std::atomic<long> |
| atomic_ulong | std::atomic<unsigned long> |
| atomic_llong | std::atomic<long long> |
| atomic_ullong | std::atomic<unsigned long long> |
| atomic_char16_t | std::atomic<char16_t> |
| atomic_char32_t | std::atomic<char32_t> |
| atomic_wchar_t | std::atomic<wchar_t> |
对于 std::atomic
通常,标准原子类型不能进行拷贝和赋值,它们没有拷贝构造函数和拷贝赋值操作符。但是,可以隐式转化成对应的内置类型,所以这些类型依旧支持赋值,可以使用 load()、store()、exchange()、compare_exchange_weak() 和 compare_exchange_strong()。它们都支持复合赋值符:+=, -=, *=, |= 等等。并且使用整型和指针的特化类型还支持 ++ 和 – 操作。当然,这些操作也有功能相同的成员函数所对应:fetch_add()、fetch_or() 等等。
++
每种函数类型的操作都有一个内存序参数,这个参数可以用来指定存储的顺序,操作分为三类:
- store 操作,可选如下内存序:memory_order_relaxed、memory_order_release、memory_order_seq_cst
- load 操作,可选如下内存序:memory_order_relaxed、memory_order_consume、memory_order_acquire、memory_order_seq_cst
- read-modify-write(读-改-写)操作,可选如下内存序:memory_order_relaxed、memory_order_consume、memory_order_acquire、memory_order_release、memory_order_acq_rel、memory_order_seq_cst
std::atomic_flag
std::atomic_flag 是最简单的原子类型,这个类型的对象可以在两个状态间切换:设置和清除。就是这么简单,只作为构建块存在。正因如此,它将作为讨论其他原子类型的起点,因为它会展示原子类型可使用的策略。
std::atomic_flag 类型的对象必须被 ATOMIC_FLAG_INIT 初始化。初始化标志位是“清除”状态。这里没得选择,这个标志总是初始化为“清除”。这适用于任何对象的声明,是唯一需要以如此特殊的方式初始化的原子类型,但也是唯一保证无锁的类型。首次使用时,需要初始化。
当 std::atomic_flag 对象已初始化,只能做三件事情:销毁、清除、查询并设置。这些操作对应的函数分别是:clear() 成员函数和 test_and_set()成员函数(设置新值并返回旧值)。
不能拷贝构造 std::atomic_flag 对象,不能将一个对象赋予另一个 std::atomic_flag 对象。这不是 std::atomic_flag 特有的属性,而是所有原子类型共有的属性。原子类型的所有操作都是原子的,而赋值和拷贝调用了两个对象,这就就破坏了操作的原子性。这样的话,拷贝构造和拷贝赋值都会将第一个对象的值进行读取,然后再写入另外一个。对于两个独立的对象,这里就有两个独立的操作了,合并这两个操作必定是不原子的。因此,操作就不被允许。
有限的特性使得 std::atomic_flag 非常适合于作自旋锁。初始化标志是“清除”,并且互斥量处于解锁状态。为了锁上互斥量,循环运行 test_and_set() 直到旧值为 false,就意味着这个线程已经被设置为 true 了。解锁互斥量是一件很简单的事情,将标志清除即可。
1 | class spinlock_mutex { |
std::atomic
std::atomic_flag 的局限性太强,没有非修改查询操作,甚至不能像普通的布尔标志那样使用。所以,实际操作中最好使用 std::atomic
最基本的原子整型类型就是 std::atomic
虽然有内存序的指定,但使用 store() 写入(true 或 false)还是好于 std::atomic_flag 中的 clear()。同样,test_and_set() 也可以替换为更加通用的 exchange(),exchange() 允许使用新选的值替换已存储的值,并且返回原始值。std::atomic
1 | std::atomic<bool> b; |
std::atomic
1 | // 以 compare_exchange_weak 为例 |
对于 compare_exchange_weak(),当原始值与预期值一致时,存储也可能会不成功。在这种情况中变量的值不会发生改变,并且 compare_exchange_weak() 的返回值是 false。这最可能发生在缺少单条 CAS 操作的机器上,当处理器不能保证这个操作能够原子的完成,称为“伪失败”(spurious failure)。
因为 compare_exchange_weak() 可以伪失败,所以通常会配合一个循环使用:
1 | bool expected = false; |
这个例子中,循环中 expected 的值始终是 false,表示 compare_exchange_weak() 会莫名的失败。
另一方面,当实际值与 expected 不符,compare_exchange_strong() 就能保证值返回 false。这就能消除对循环的需要,就可以知道是否成功的改变了一个变量,或已让另一个线程完成。
std::atomic<T*>
原子指针类型,可以使用内置类型或自定义类型 T,通过特化 std::atomic<T*> 进行定义,操作是针对于相关类型的指针。虽然既不能拷贝构造,也不能拷贝赋值,但是可以通过合适的类型指针进行构造和赋值。std::atomic<T*> 也有 load()、store()、exchange()、compare_exchange_weak() 和 compare_exchage_strong() 成员函数,获取与返回的类型都是 T*。
std::atomic<T*> 为指针运算提供新的操作。基本操作有 fetch_add() 和 fetch_sub()(它们在存储地址上做原子加法和减法),以及 +=、-=、++ 和 –。举个例子,x 是std::atomic<Foo*> 类型的数组的首地址址,x.ftech_add(3) 让 x 指向第四个元素,并且函数返回指向第一个元素的地址
这种操作也被称为“交换-相加”。正像其他操作那样,返回值是一个普通的 T* 值,而非是std::atomic<T*> 对象的引用,所以调用代码可以基于之前的值进行操作:
1 | class Foo{}; |
标准原子整型的相关操作
如同普通的操作集合一样(load()、store()、exchange()、compare_exchange_weak() 和 compare_exchange_strong()),std::atomic
std::atomic<> 类模板
模板允许用户使用自定义类型创建一个原子变量(除了标准原子类型之外),需要满足一定的标准才可以使用 std::atomic<>。为了使用 std::atomic
以上严格的限制都是依据第 3 章中的建议:不要将锁定区域内的数据以引用或指针的形式,作为参数传递给用户提供的函数。通常情况下,编译器不会为 std::atomic
注意,虽然使用 std::atomic
如果 UDT 类型的大小如同(或小于)一个 int 或 void* 类型时,大多数平台将会对 std::atomic
当使用用户定义类型 T 进行实例化时,std::atomic
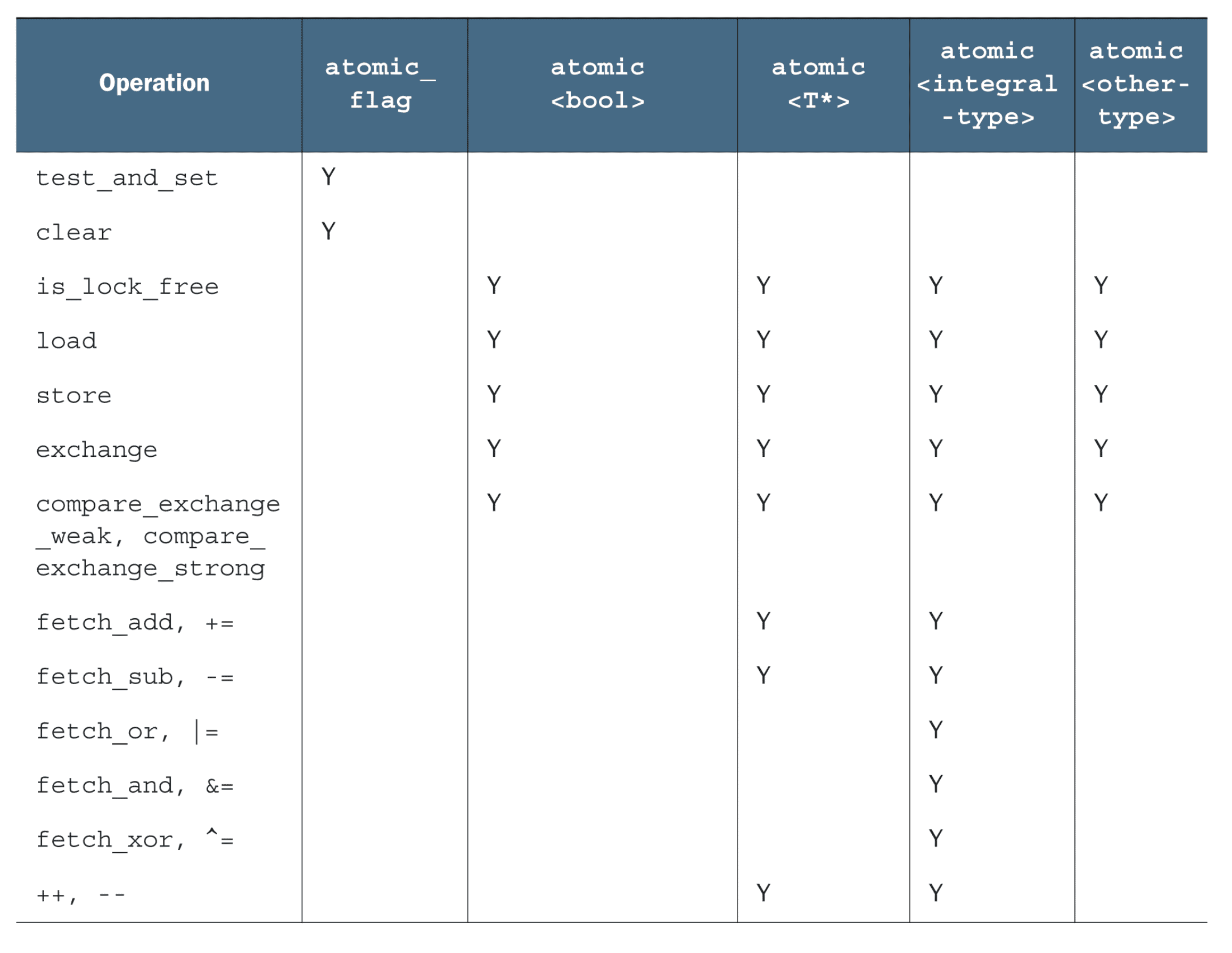
原子操作的非成员函数
除了每个类型各自的成员函数,原子操作库还提供了通用的非成员函数,只不过函数名多了一个 atomic_ 前缀,参数变为指针类型:
1 | std::atomic<int> i(42); |
每个非成员函数有一个 _explicit 后缀版本,可多接受一个 std::memory_order 参数:
1 | std::atomic<int> i(42); |
非成员函数的设计主要考虑的是 C 语言没有引用而只能使用指针,compare_exchange_weak 和 compare_exchange_strong 的第一个参数是引用,因此 std::atomic_compare_exchange_weak 和 std::atomic_compare_exchange_strong 的参数用的是指针:
1 | bool compare_exchange_weak(T& expected, T desired, |
std::atomic_flag 对应的非成员函数的前缀不是 atomic_ 而是 _atomic_flag_,但接受 std::memory_order 参数的版本一样是 _explicit 后缀:
1 | std::atomic_flag x = ATOMIC_FLAG_INIT; |
非成员函数不仅可用于原子类型,还为 std::shared_ptr 提供了特化版本:
1 | std::shared_ptr<int> p(new int(42)); |
这些特化将在 c++20 中弃用,c++20 直接允许 std::atomic 的模板参数为 std::shared_ptr:
1 | std::atomic<std::shared_ptr<int>> x; // c++20 |
原子操作的内存序
虽然内存序有六种,但是理解了四种同步的情形基本就差不多了。
relaxed ordering(memory_order_relaxed)
在这种情况下,同一线程中对于同一变量的操作还是遵从先行关系,但不同线程不需要规定顺序。唯一的要求是在访问同一线程中的单个原子变量不能重排序,当给定线程看到原子变量的值时,随后线程的读操作就不会去检索较早的那个值。
1 |
|
在上面这段代码中 assert 5 可能会触发,因为加载 x 的操作 4 可能读取到 false,即使加载 y 的操作 3 读取到 true,并且存储 x 的操作 1 先发与存储 y 的操作 2。x 和 y 是两个不同的变量,所以没有顺序去保证每个操作产生相关值的可见性。
在单个线程内,所有原子操作是顺序进行的,也就是代码顺序。这就是唯一的限制了。两个来自不同线程的原子操作的顺序是任意的,即所有线程看到的全局顺序并不是一致的。
为了了解自由序是如何工作的,可先将每一个变量想象成在一个独立房间中拿着记事本的人。他的记事本上是一组值的列表,可以通过打电话的方式让他给你一个值,或让他写下一个新值。如果告诉他写下一个新值,他会将这个新值写在表的最后。如果让他给你一个值,他会从列表中读取一个值给你。
第一次与这人交谈时,如果问他要一个值,他可能会在现有的列表中选区任意值告诉你。如果之后再问他要一个值,可能会得到与之前相同的值,或是列表下端的其他值,他不会给你列表上端的值。如果让他写一个值,并且随后再问他要一个值,他要不就给你你刚告诉他的那个值,要不就是一个列表下端的值。
试想当他的笔记本上开始有 5,10,23,3,1,2 这几个数。如果问他索要一个值,你可能获取这几个数中的任意一个。如果他给你 10,那么下次再问他要值的时候可能会再给你 10,或者 10 后面的数,但绝对不会是 5。如果那你问他要了五次,他就可能回答“10,10,1,2,2”。如果你让他写下 42,他将会把这个值添加在列表的最后。如果你再问他要值,他可能会告诉你“42”,直到有其他值写在了后面,并且他愿意将那个数告诉你。
现在,你有个朋友叫 Carl,他也有那个计数员的电话。Carl 也可以打电话给计算员,让他写下一个值或获取一个值,他对 Carl 回应的规则和你是一样的。他只有一部电话,所以一次只能处理一个人的请求,所以他记事本上的列表是一个简单的列表。但是,你让他写下一个新值的时候,不意味着他会将这个消息告诉 Carl,反之亦然。如果 Carl 从他那里获取一个值“23”,之后因为你告诉他写下 42,这不意味着下次他会将这件事告诉 Carl。他可能会告诉 Carl 任意一个值,23,3,1,2,42 亦或是 67(是 Fred 在你之后告诉他的)。他会很高兴的告诉 Carl “23,3,3,1,67”,与你告诉他的值完全不一致,
这就让自由的原子操作变得难以处理,他们必须与原子操作结合使用,这些原子操作必须有较强的排序语义。为了让内部线程同步变得更有用,强烈建议避免自由序的原子操作,除非它们是硬性要求的,并且使用时需要十二分的谨慎。要想获取额外的同步,且不使用全局排序一致,可以使用 release & acquire。
release & acquire(memory_order_release、memory_order_acquire)
来自不同线程的两个原子操作顺序不一定,为了限制一下它们的顺序,这就需要两个线程进行一下同步(synchronize-with),同步对一个变量的读写操作。线程 A 原子性地把值写入 x (release), 然后线程 B 原子性地读取 x 的值(acquire)。这样线程 B 保证读取到 x 的最新值。线程 A 中所有发生在 release x 之前的写操作,对在线程 B acquire x 之后的任何读操作都可见。本来 A、B 间读写操作顺序不定。这么一同步,在 x 这个点前后, A、B 线程之间有了个顺序关系,称作 inter-thread happens-before。
对于读操作,使用 memory_order_acquire,对于写操作,使用memory_order_release,对于读-改-写操作,使用 memory_order_acq_rel。
1 |
|
上面的示例中,assert 可能发生中断。主函数开了四个线程,其中两个写,两个读。线程 read_x_then_y 保证 x.load 一定发生在 x.store 之后(通过 while 保证的),但 y.load 是不是发生在 y.store 之后并没有保证。
为了让 release & acquire 发挥作用,需要把 x.store 和 y.store 放在一个线程中:
1 |
|
release & acquire 内存序保证同一个原子变量的 release 之前的写操作对 acquire 以后的读操作是可见的,所以说 x.load 一定发生在 x.store 之后,z 必然等于 1。
下面展示一个使用 release & acquire 传递同步的例子:
1 | std::atomic<int> data[5]; |
这个例子中,可将 sync1 和 sync2 通过在 thread_2 中使用“读-改-写”操作合并成一个独立的变量。其中会使用 compare_exchange_strong() 来保证 thread_1 对变量只进行一次更新:
1 | std::atomic<int> sync(0); |
release & consume(memory_order_release、memory_order_consume)
如果只想同步一个 x 的写操作,结果把 release 之前的所有写操作都同步了,为了避免这个额外开销可以使用 release & consume。同步还是一样的同步:在线程 B acquire x 之后的读操作中,有一些是依赖于 x 的值的读操作。同理在线程 A 里面, release x 也有一些它所依赖的其他写操作,这些写操作自然发生在 release x 之前。只有上述的读操作能看到上述的写操作。
1 | struct X { |
存储 a 在存储 p 之前,并且存储 p 的操作标记为 memory_order_release,加载 p 的操作标记为 memory_order_consume,所以存储 p 仅先行那些需要加载 p 的操作。因为对 x 变量操作的表达式对加载 p 的操作携带有依赖,所以 X 结构体中数据成员所在的断言语句 1、2 不会被触发。另一方面,对于加载变量 a 的断言 3 就不能确定是否能触发,因为这个操作标记为 memory_order_relaxed,所以这个操作并不依赖于 p 的加载操作,也无法保证已经读取数据。
memory_order_consume 很特别:完全依赖于数据。这个内存序非常特殊,即使在 C++17 中也不推荐使用。这里只为了完整的覆盖内存序而讨论,memory_order_consume 不应该出现在代码中。
sequential consistency(memory_order_seq_cst)
理解了前面的几个,顺序一致性就最好理解了。release && acquire 只同步一个 x,顺序一致则是对所有的变量的所有原子操作都同步。这样的话,所有线程的原子操作的执行顺序都是一样的,即所有线程看到的全局顺序是一致的。
1 |
|
上面的示例中,assert 永远不会造成中断,其运行情况可以分为三种:
- 对于 read_x_then_y 线程来说,如果在 read_x_then_y 中加载 y 返回 false,这说明是因为存储 x 的操作发生在存储 y 的操作之前。那么线程 read_y_then_x 看到的顺序也是如此,则在 read_y_then_x 中加载 x 必定会返回 true,此时 z 会自增
- 上面情况的对称
- 不管 x.store 和 y.store 谁先发生,如果 load 都发生在 store 之后,那么 z 会自增两次
内存栅栏
内存栅栏操作会对内存序列进行约束,使其无法对任何数据进行修改,典型的做法是与使用 memory_order_relaxed 约束序的原子操作一起使用。内存栅栏属于全局操作,执行栅栏操作可以影响到在线程中的其他原子操作。这类操作就像画了一条任何代码都无法跨越的线一样。
给在不同线程上的两个原子操作中添加一个栅栏,可以让自由操作变的有序:
1 |
|
因为加载 y 的操作 4 读取 3 处存储的值,所以释放栅栏 2 与获取栅栏 5 同步。1 处存储 x 先行于 6 处加载 x,最后 x 读取出来必为 true,并且不会触发断言 7。原先不带栅栏的存储和加载 x 是无序的,并且断言是可能会触发。这两个栅栏都是必要的:需要在一个线程中进行释放,然后在另一个线程中进行获取,这样才能构建同步关系。
参考
C++ 多线程设计(二) - 无锁并发数据结构设计
如何理解 C++11 的六种 memory order?
C++11中的内存模型上篇 - 内存模型基础
05 内存模型和原子操作 | 《C++ Concurrency In Action》笔记