本系列笔记参考《C++ Concurrency in Action, 2nd Edition》 及其中文翻译 。
等待事件或条件 等待条件达成 C++ 标准库对条件变量有两套实现:std::condition_variable 和 std::condition_variable_any,这两个实现都包含在 condition_variable.h 头文件的声明中。两者都需要与互斥量一起才能工作,前者仅能与 std::mutex 一起工作,而后者可以和合适的互斥量一起工作,从而加上了 _any 的后缀。因为std::condition_variable_any 更加通用,不过在性能和系统资源的使用方面会有更多的开销,所以通常会将 std::condition_variable 作为首选类型。当对灵活性有要求时,才会考虑 std::condition_variable_any。
下面的代码是简单的生产者-消费者示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 std::mutex mut; std::queue<data_chunk> data_queue; std::condition_variable data_cond; void data_preparation_thread () while (more_data_to_prepare ()) { data_chunk const data = prepare_data (); std::lock_guard<std::mutex> lk (mut) ; data_queue.push (data); data_cond.notify_one (); } } void data_processing_thread () while (true ) { std::unique_lock<std::mutex> lk (mut) ; data_cond.wait (lk, []{return !data_queue.empty ();}); data_chunk data = data_queue.front (); data_queue.pop (); lk.unlock (); process (data); if (is_last_chunk (data)) { break ; } } }
首先,队列中中有两个线程,两个线程之间会对数据进行传递。数据准备好时,使用 std::lock_guard 锁定队列,将准备好的数据压入队列之后,线程会对队列中的数据上锁,并调用 std::condition_variable 的 notify_one() 成员函数,对等待的线程进行通知。另外的一个线程正在处理数据,线程首先对互斥量上锁。之后会调用 std::condition_variable 的成员函数 wait(),传递一个锁和一个 lambda 表达式。
wait() 会通过 lambda 函数去检查这些条件,当条件满足(lambda 函数返回 true)时返回并继续持有锁。如果条件不满足(lambda 函数返回 false),wait() 将解锁互斥量,并且将线程(处理数据的线程)置于阻塞或等待状态。当准备数据的线程调用 notify_one() 通知条件变量时,处理数据的线程从睡眠中苏醒,重新获取互斥锁,并且再次进行条件检查。在条件满足的情况下,从 wait() 返回并继续持有锁。当条件不满足时,线程将对互斥量解锁,并重新等待。这就是为什么用 std::unique_lock 而不使用 std::lock_guard 的原因——等待中的线程必须在等待期间解锁互斥量,并对互斥量再次上锁,而 std::lock_guard 没有这么灵活。如果互斥量在线程休眠期间保持锁住状态,准备数据的线程将无法锁住互斥量,也无法添加数据到队列中。同样,等待线程也永远不会知道条件何时满足。
虚假唤醒(spurious wakeup) 虚假唤醒的概念:多个线程同时等待同一个条件满足时,当条件变量唤醒线程时,可能会唤醒多个线程,但是如果对应的资源只有一个线程能获得,其余线程就无法获得该资源,因此其余线程的唤醒是无意义的(有时甚至是有危害的),其余线程的唤醒则被称为虚假唤醒。
上述的危害是指条件变量即使没有被 notify,它也可能被允许返回。这是由于为了给操作系统提供处理错误情况和(线程)竞争实现(更大的)灵活性。幸运的是,linux 中的 pthread 则保证这种情况不会发生(https://en.wikipedia.org/wiki/Spurious_wakeup )。
构建线程安全队列 忽略掉类的构造、赋值以及交换操作,队列还有三组操作:
对整个队列的状态进行查询:empty() 和 size()
查询在队列中的各个元素:front() 和 back()
修改队列的操作:push()、pop() 和 emplace()
和之前提到的栈一样,也会遇到接口上的条件竞争。因此,需要将 front() 和 pop()合并成一个函数调用,就像之前在栈实现时合并 top() 和 pop()一样。当队列在多个线程中传递数据时,接收线程通常需要等待数据的压入。这里提供 pop() 函数的两个变种:try_pop() 和 wait_and_pop()。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 #include <queue> #include <memory> #include <mutex> #include <condition_variable> template <typename T>class threadsafe_queue {private : mutable std::mutex mut; std::queue<T> data_queue; std::condition_variable data_cond; public : threadsafe_queue () {} threadsafe_queue (threadsafe_queue const & other) { std::lock_guard<std::mutex> lk (other.mut) ; data_queue=other.data_queue; } void push (T new_value) std::lock_guard<std::mutex> lk (mut) ; data_queue.push (new_value); data_cond.notify_one (); } void wait_and_pop (T& value) std::unique_lock<std::mutex> lk (mut) ; data_cond.wait (lk, [this ]{return !data_queue.empty ();}); value=data_queue.front (); data_queue.pop (); } std::shared_ptr<T> wait_and_pop () { std::unique_lock<std::mutex> lk (mut) ; data_cond.wait (lk, [this ]{return !data_queue.empty ();}); std::shared_ptr<T> res (std::make_shared<T>(data_queue.front())) ; data_queue.pop (); return res; } bool try_pop (T& value) std::lock_guard<std::mutex> lk (mut) ; if (data_queue.empty ()) { return false ; } value = data_queue.front (); data_queue.pop (); return true ; } std::shared_ptr<T> try_pop () { std::lock_guard<std::mutex> lk (mut) ; if (data_queue.empty ()) { return std::shared_ptr <T>(); } std::shared_ptr<T> res (std::make_shared<T>(data_queue.front())) ; data_queue.pop (); return res; } bool empty () const std::lock_guard<std::mutex> lk (mut) ; return data_queue.empty (); } };
std::future std::async 假设有一个需要长时间的运算,需要计算出一个有效值,但并不迫切需要这个值。你可以启动新线程来执行这个计算,你需要计算的结果,但是又无法获取 std::thread 执行的任务的返回值。这里就需要 std::async 函数模板。
当不着急让任务结果时,可以使用 std::async 启动一个异步任务。与 std::thread 对象等待的方式不同,std::async 会返回一个 std::future 对象,这个对象持有最终计算出来的结果。当需要这个值时,只需要调用这个对象的 get() 成员函数,就会阻塞线程直到 future 为就绪为止,并返回计算结果。
1 2 3 4 5 6 7 8 9 10 11 #include <future> #include <iostream> int find_the_answer_to_ltuae () void do_other_stuff () int main () std::future<int > the_answer = std::async (find_the_answer_to_ltuae); do_other_stuff (); std::cout << "The answer is " << the_answer.get () << std::endl; }
我们还可以在函数调用之前向 std::async 传递一个额外参数,这个参数的类型是 std::launch,是函数的启动策略,它控制 std::async 的异步行为。有三种不同的启动策略:
std::launch::async:保证异步行为,即函数必须在单独的线程中执行。
std::launch::deferred:函数调用延迟到其他线程调用 wait() 或 get() 时才同步执行。
std::launch::async | std::launch::deferred:默认行为,有了这个启动策略,它可以异步运行或不运行,这取决于系统的负载,即有可能创建一个线程运行函数,也有可能不运行直到有线程线程调用 wait() 或 get()。
使用 std::async 会将算法分割到各个任务中,这样程序就能并发了。不过,这不是让 std::future 与任务实例相关联的唯一方式,也可以将任务包装入 std::packaged_task<> 中,或通过编写代码的方式,使用 std::promise<> 模板显式设置值。与 std::promise<> 相比,std::packaged_task<> 具有更高的抽象,所以我们从“高抽象”模板说起。
std::promise 其作用是在一个线程 t1 中保存一个类型 typename T 的值,可供相绑定的 std::future 对象在另一线程 t2 中获取。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 #include <iostream> #include <future> #include <chrono> void ThreadFun1 (std::promise<int > &p) int iVal = 233 ; p.set_value (iVal); } void ThreadFun2 (std::future<int > &f) auto iVal = f.get (); std::cout << "收到数据(int):" << iVal << std::endl; } int main () std::promise<int > pr1; std::future<int > fu1 = pr1.get_future (); std::thread t1 (ThreadFun1, std::ref(pr1)) ; std::thread t2 (ThreadFun2, std::ref(fu1)) ; t1.join (); t2.join (); }
std::packaged_task 其实 std::packaged_task 和 std::promise 非常相似,简单来说 std::packaged_task 是对 std::promise<T=std::function> 中 T=std::function 这一可调对象进行了包装,简化了使用方法。并将这一可调对象的返回结果 传递给关联的 std::future 对象。
例子 1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #include <iostream> #include <future> #include <chrono> #include <functional> int TestFun (int a, int b, int &c) std::this_thread::sleep_for (std::chrono::seconds (5 )); c = a + b + 230 ; return c; } int main () std::packaged_task<int (int , int , int &) > pt1 (TestFun) ; std::future<int > fu1 = pt1.get_future (); int c = 0 ; std::thread t1 (std::move(pt1), 1 , 2 , std::ref(c)) ; int iResult = fu1.get (); return 0 ; }
例子 2
很多图形架构需要特定的线程去更新界面,所以当线程对界面更新时,需要发出一条信息给正确的线程,让相应的线程来做界面更新。std::packaged_task 提供了这种功能,且不需要发送一条自定义信息给图形界面线程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 #include <deque> #include <mutex> #include <future> #include <thread> #include <utility> std::mutex m; std::deque<std::packaged_task<void ()> > tasks; bool gui_shutdown_message_received () void get_and_process_gui_message () void gui_thread () while (!gui_shutdown_message_received ()) { get_and_process_gui_message (); std::packaged_task<void ()> task; { std::lock_guard<std::mutex> lk (m) ; if (tasks.empty ()) { continue ; } task = std::move (tasks.front ()); tasks.pop_front (); } task (); } } std::thread gui_bg_thread (gui_thread) ;template <typename Func>std::future<void > post_task_for_gui_thread (Func f) { std::packaged_task<void () > task (f) ; std::future<void > res = task.get_future (); std::lock_guard<std::mutex> lk (m) ; tasks.push_back (std::move (task)); return res; }
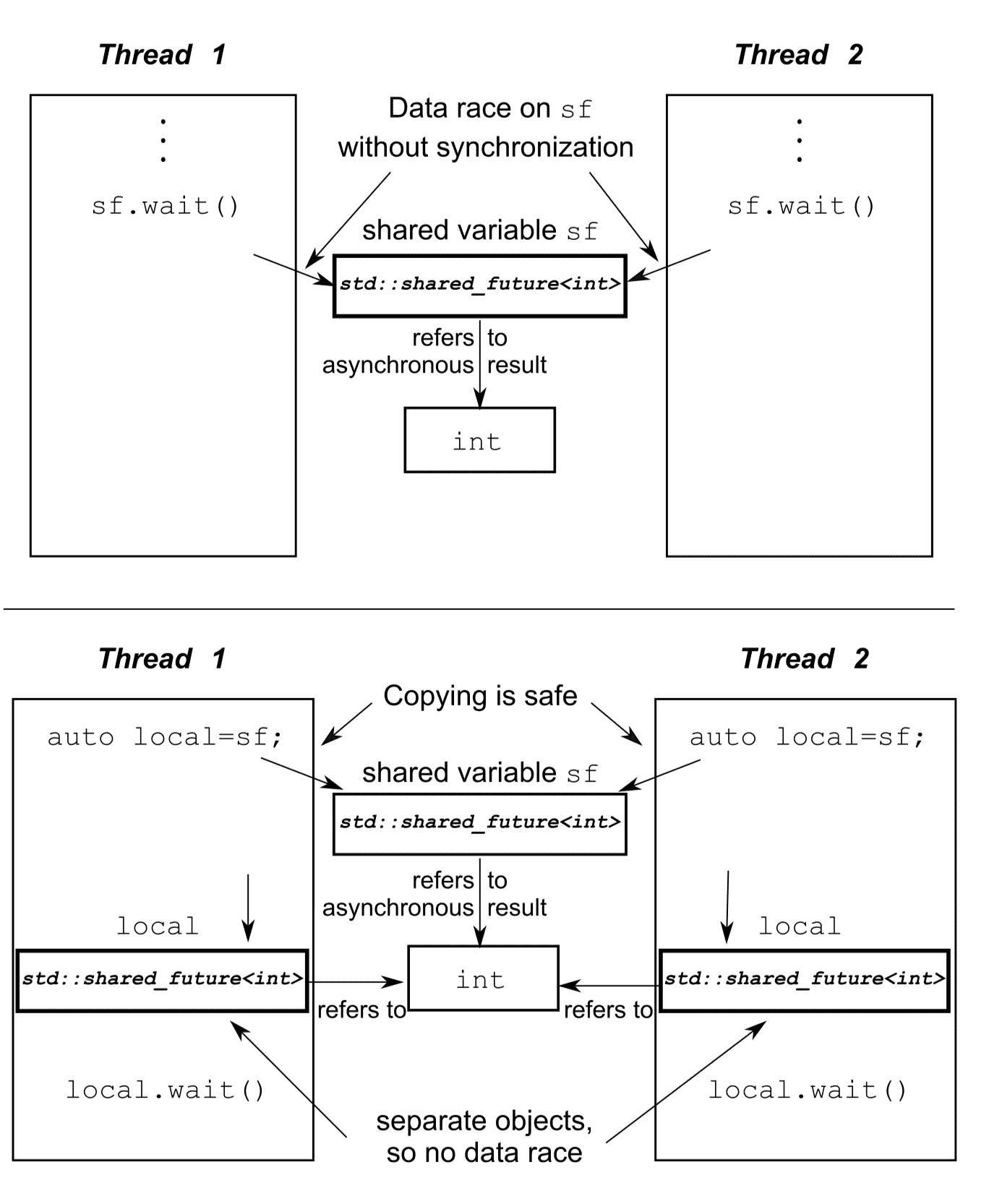
std::shared_future std::shared_future 可以让多个线程等待同一个事件。因为 std::future 是只移动的,所以其所有权可以在不同的实例中互相传递,但只有一个实例可以获得特定的同步结果,而 std::shared_future 实例是可拷贝的,所以多个对象可以引用同一关联期望值的结果。
每一个 std::shared_future 的独立对象上,成员函数调用返回的结果还是不同步的,所以为了在多个线程访问一个独立对象时避免数据竞争,必须使用锁来对访问进行保护。优先使用的办法:可以让每个线程都拥有自己对应的拷贝对象。这样,当每个线程都通过自己拥有的 std::shared_future 对象获取结果,那么多个线程访问共享同步结果就是安全的。
可能会使用 std::shared_future 的场景:复杂的电子表格的并行执行。每一个单元格有唯一终值,终值通过公式计算得到,这个终值可能依赖其他单元格的终值。可以使用 std::shared_future 对象引用上一个单元格的数据。当每个单元格内的所有公式并行执行后,任务会以期望的方式完成工作。当其中有计算需要依赖其他单元格的值时就会阻塞,直到依赖单元格的数据准备就绪。这可以让系统在最大程度上使用硬件并发。
简化代码 函数式编程 函数式编程(functional programming)是一种编程方式,函数结果只依赖于传入函数的参数。使用相同的参数调用函数,不管多少次都会获得相同的结果。C++ 标准库中与数学相关的函数都有这个特性。纯粹的函数不会改变任何外部状态,并且这种特性限制了函数的返回值。不修改共享数据,就不存在条件竞争,并且没有必要使用互斥量保护共享数据。这是对编程极大的简化,例如 Haskell 语言中所有函数默认都是“纯粹的”。
命令式编程与函数式编程
函数式编程与命令式编程最大的不同其实在于:函数式编程关心数据的映射,命令式编程关心解决问题的步骤。
以二叉树反转为例,命令式编程的代码是这样的:
1 2 3 4 5 6 def invertTree (root ): if root is None : return None root.left = invertTree(root.left) root.right = invertTree(root.right) return root
它的含义是:首先判断节点是否为空;然后翻转左树;然后翻转右树;最后左右互换。这就是命令式编程——你要做什么事情,你得把达到目的的步骤详细的描述出来,然后交给机器去运行。
函数式思维提供了另一种思维的途径——所谓“翻转二叉树”,可以看做是要得到一颗和原来二叉树对称的新二叉树,这颗新二叉树的特点是每一个节点都递归地和原树相反。
1 2 3 4 5 def invert (node ): if node is None : return None else return Tree(node.value, invert(node.right), invert(node.left))
这段代码最终达到的目的同样是翻转二叉树,但是它得到结果的方式和命令式的代码有着本质的差别:通过描述一个旧树->新树的映射,而不是描述“旧树得到新树应该怎样做”来达到目的。
快速排序:FP 模式版
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 template <typename T>std::list<T> sequential_quick_sort (std::list<T> input) { if (input.empty ()) { return input; } std::list<T> result; result.splice (result.begin (), input, input.begin ()); T const & pivot = *result.begin (); auto divide_point = std::partition (input.begin (), input.end (), [&](T const & t){ return t < pivot; }); std::list<T> lower_part; lower_part.splice (lower_part.end (), input, input.begin (), divide_point); auto new_lower = sequential_quick_sort (std::move (lower_part))); auto new_higher = sequential_quick_sort (std::move (input))); result.splice (result.end (), new_higher); result.splice (result.begin (), new_lower); return result; }
注:
void splice(iterator position, list<T> &x, iterator it); 只会把 it 的值剪接到要操作的 list 对象中void splice(iterator position, list<T> &x, iterator first, iterator last); 把 first 到 last 剪接到要操作的 list 对象中std::partition 会对列表进行重置,并返回指向首元素(中间值)的迭代器
快速排序:FP 模式并行版
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 template <typename T>std::list<T> parallel_quick_sort (std::list<T> input) { if (input.empty ()) { return input; } std::list<T> result; result.splice (result.begin (), input, input.begin ()); T const & pivot = *result.begin (); auto divide_point = std::partition (input.begin (), input.end (), [&](T const & t){ return t < pivot; }); std::list<T> lower_part; lower_part.splice (lower_part.end (), input, input.begin (), divide_point); std::future<std::list<T>> new_lower = std::async (¶llel_quick_sort<T>, std::move (lower_part)); auto new_higher = parallel_quick_sort (std::move (input)); result.splice (result.end (), new_higher); result.splice (result.begin (), new_lower.get ()); return result; }
通过递归调用 parallel_quick_sort(),可以使用硬件并发。std::async 会启动一个新线程,这样当递归三次时,就会有八个线程在运行了。当递归十次,如果硬件能处理这十次递归调用,将会创建 1024 个执行线程。当运行库认为产生了太多的任务时(也许是因为数量超过了硬件并发的最大值),为了避免任务传递的开销,这些任务会在使用 get() 获取结果的线程上运行,而不是在新线程上运行,这也符合 std::async 的行为。
函数化编程可算作是并发编程的范型,并且也是通讯顺序进程(CSP,Communicating Sequential Processer)的范型,这里的线程没有共享数据,但有通讯通道允许信息在不同线程间进行传递。这种范型被 Erlang 语言所采纳,并且常用在 MPI(Message Passing Interface)上做高性能运算。
参与者模式 在参与者模式中,系统中有很多独立的(运行在一个独立的线程上)参与者,这些参与者会互相发送信息,去执行手头上的任务,并且不会共享状态,除非是通过信息直接传入的。一个并发系统中,这种编程方式可以极大的简化任务的设计,因为每一个线程都完全被独立对待。因此,使用多线程去分离关注点时,需要明确线程之间的任务应该如何分配。
参考 [C++11]std::promise介绍及使用 [C++11]std::packaged_task介绍及使用 什么是函数式编程思维?