课程笔记:AI 编译器后端优化 | 编译器
本文是以下教学视频的笔记:【AI编译器】系列之后端优化
概述
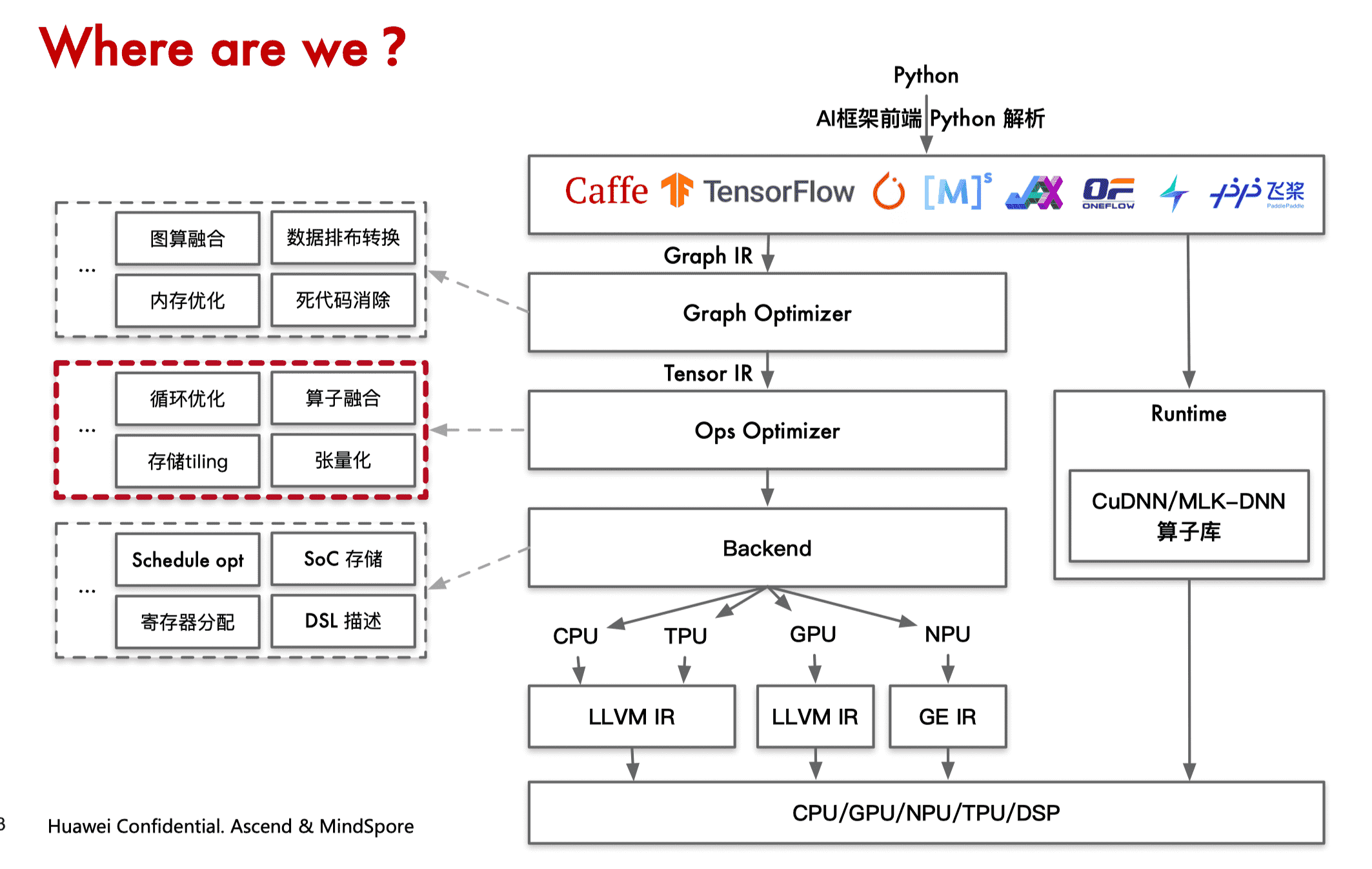
前端优化与后端优化的区别
前端优化:输入计算图,关注计算图整体拓扑结构,而不关心算子的具体实现。在 AI 编译器的前端优化,对算子节点进行融合、消除、化简等操作,使计算图的计算和存储开销最小。
后端优化:关注算子节点的内部具体实现,针对具体实现使得性能达到最优。重点关心节点的输入、输出、内存循环方式和计算的逻辑。
后端优化的流程
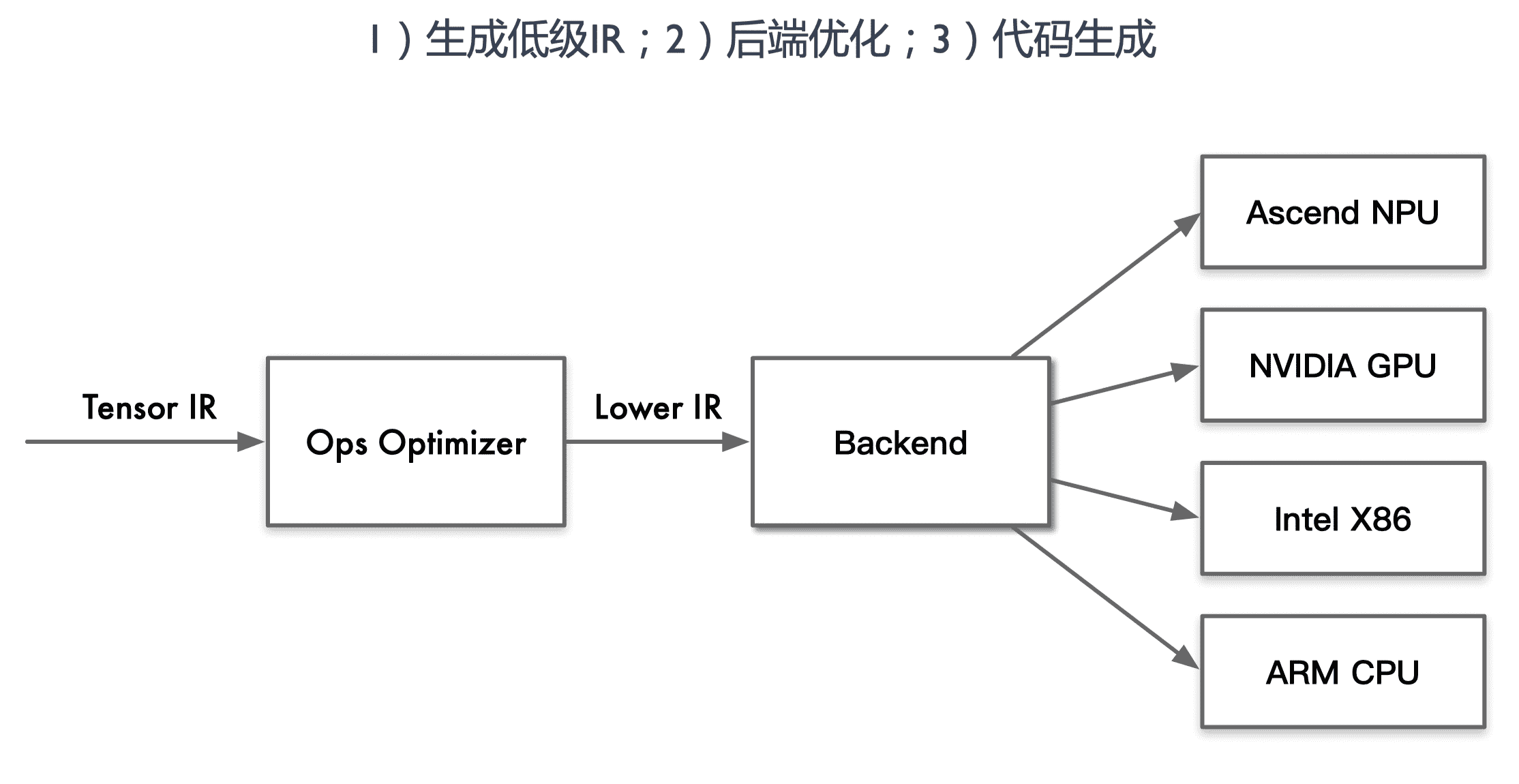
生成低级 IR:不同 AI 编译器内部低级 IR 形式和定义不同,但是对于同一算子,算法的原理 实质相同。对于每个具体的算子,需要用 AI 编译器底层的接口来定义算法,再由编译器来生成内部的低级 IR。
后端优化:针对不同的硬件架构/微架构,不同的算法实现的方式有不同的性能,目的是找到算子的最优实现方式,达到最优性能。同一算子不同形态如 Conv1x1、Conv3x3、Conv7x7 都会有不同的循环优化方法。
3)代码生成:对优化后的低级 IR 转化为机器指令执行,现阶段最广泛的借助成熟的编译工具来实现,非 AI 编译器的核心内容。如把低级 IR 转化成为 LLVM、NVCC 等成功编译工具的输入形式,然后调用其生成机器指令。
算子优化的挑战
- 优化手段多样:要在不同情况下权衡优化及其对应参数,对于优化专家来说也是相当耗费精力
- 通用性与移植性:不同类型的硬件架构差异,使得优化方法要考虑的因素也有很大不同
- 优化间相互影响:各种优化之间可能会相互制约,相互影响。这意味着找到最优的优化方法组合与序列就是一个困难的组合优化问题,甚至是 NP 问题
自动化生成 kernel
- Auto Tuning:AI 编译器中正在尝试融合机器学习方法
- Polyhedral:算子计算加速正在用编译技术来解决
算子计算与调度
计算是算子的定义,回答算子是什么,如何通过具体的算法得到正确的定义结果
调度是算子的执行策略和具体实现,回答系统具体如何执行算子的计算定义
同一算子会有不同的实现方式(即不同的调度方式),但是只会有一种计算形态(具体定义)
计算实现和计算在硬件单元上的调度是分离的
算子调度具体执行的所有可能的调度方式称为调度空间,AI 编译器优化的目的就是为算子提供一种最优的调度,使得算子在硬件上运行时间最优。
调度树
将算子的调度内容抽象成一系列具体的节点:
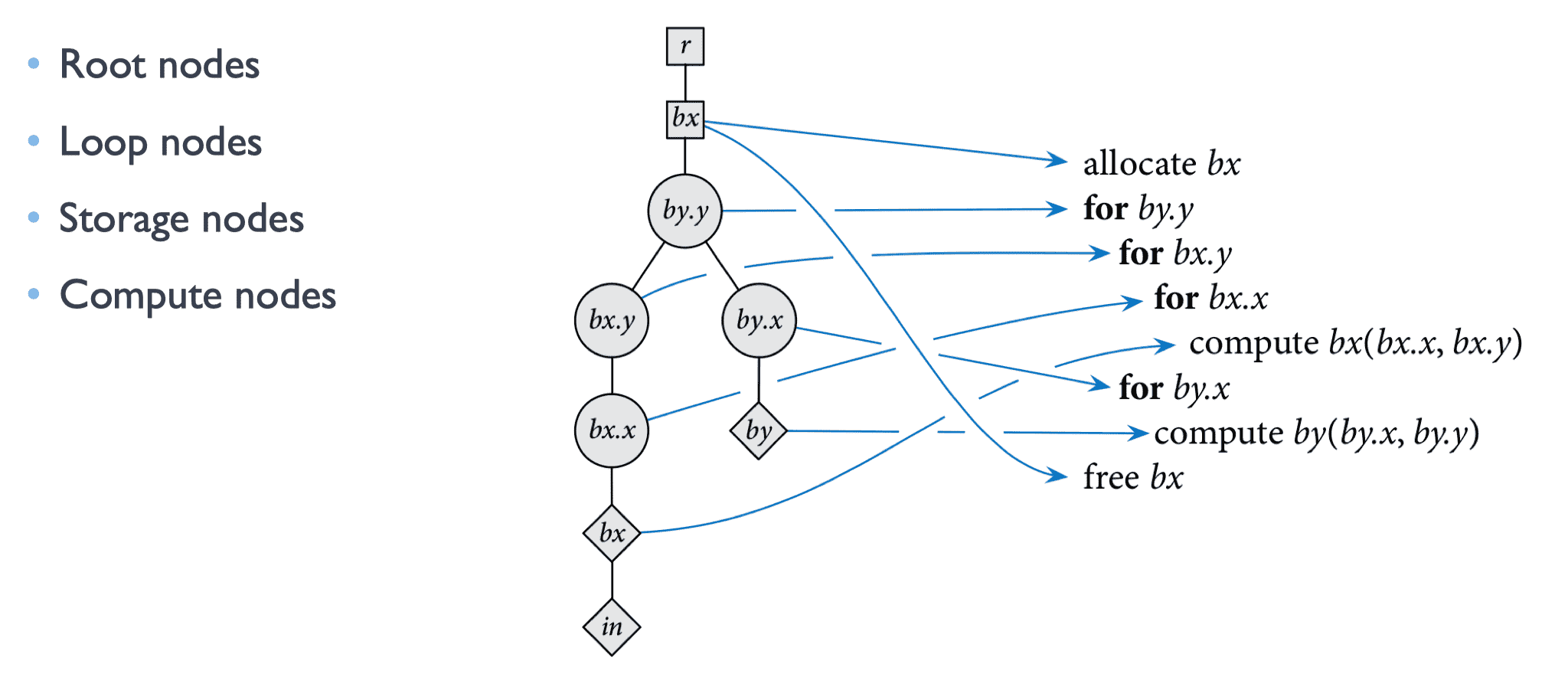
调度转换
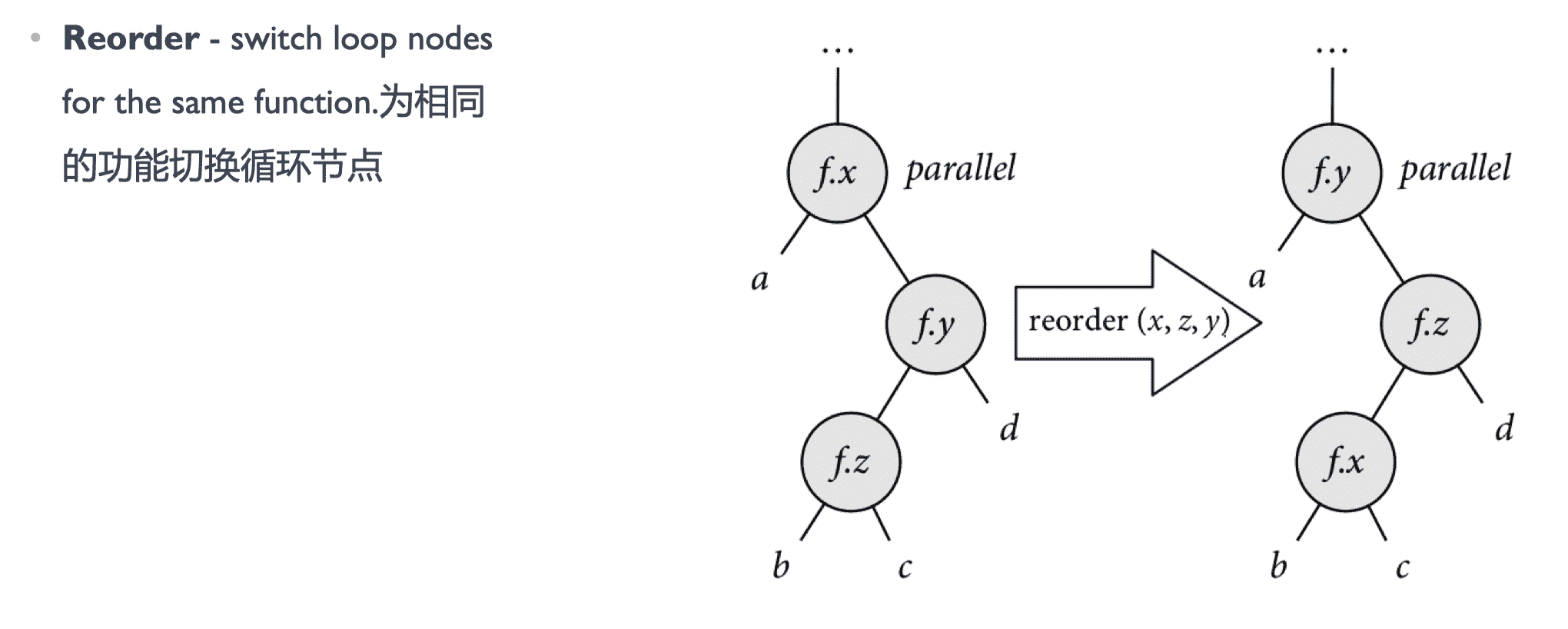
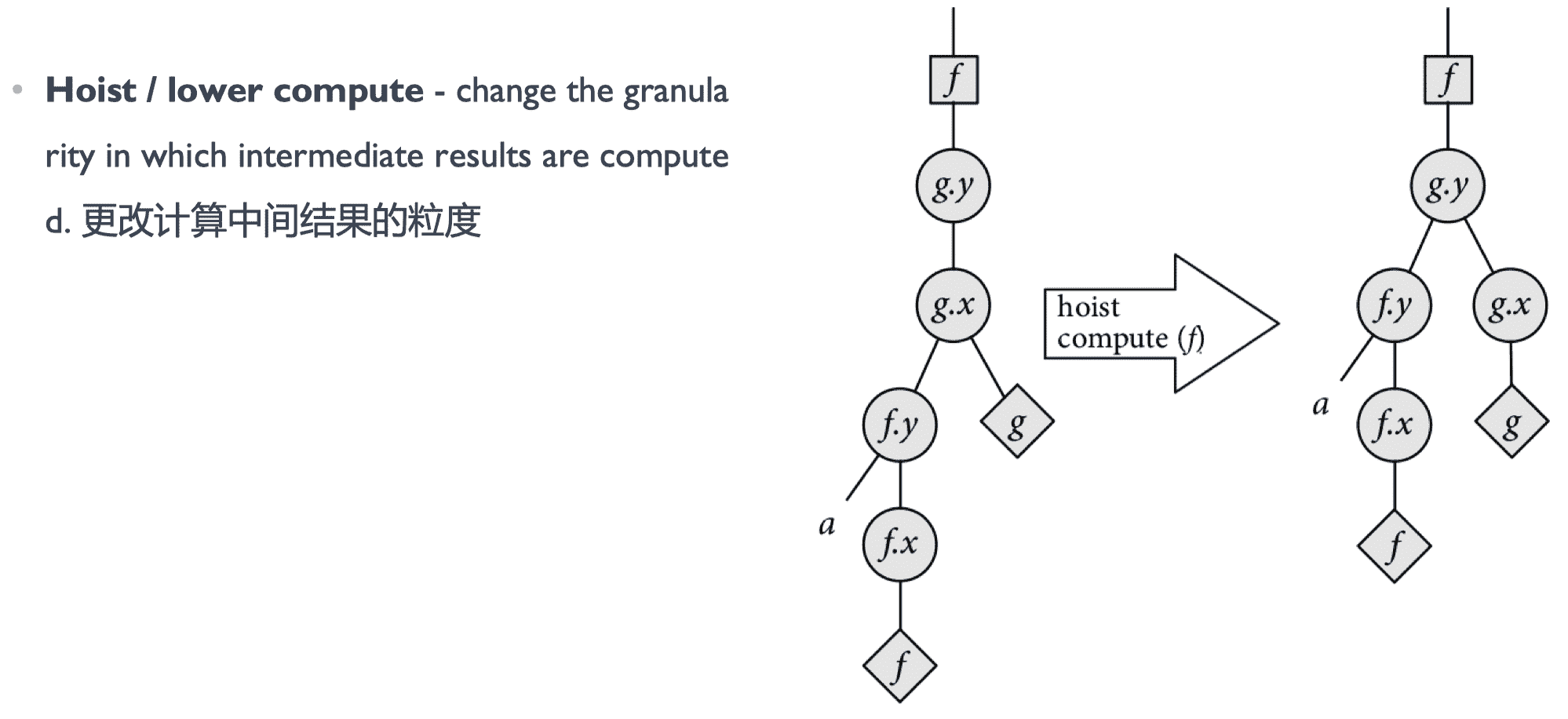
调度评估
通过建模的方式寻找一条路径或者调度树的组织方式,使得调度树满足 cost function 最优,这样就找到一种最好的调度策略了。
算子调度优化
基于源码的修改




调度优化的方法
- 循环优化(Loop Optimization)
- 循环展开(Loop Unrolling)
- 循环分块(Loop Tiling)
- 循环重排(Loop Reorder)
- 循环融合(Loop Fusion)
- 循环拆分(Loop Split)
- 指令优化(Instructions Optimization)
- 向量化(Vector)
- 张量化(Tensor)
- 存储优化(Memory Optimization)
- 延迟隐藏(Latency Hiding)
- 存储分配(Memory Allocation)
算子循环优化
循环展开
对循环进行展开,以便每次迭代多次使用加载的值,使得一个时钟周期的流水线上尽可能满负荷计算。在流水线中,会因为指令顺序安排不合理而导致计算单元等待空转,影响流水线效率。循环展开为编译器进行指令调度带来了更大的空间。

循环分块
由于内存空间有限,代码访问的数据量过大时,无法一次性将所需要的数据加载到设备内存,循环分块能有效提高 cache 的访存效率,改善数据局部性。
如果分块应用于外部循环,会增加计算的空间和时间局部性。分块应与缓存块一起作用,可以提高流水线的效率。
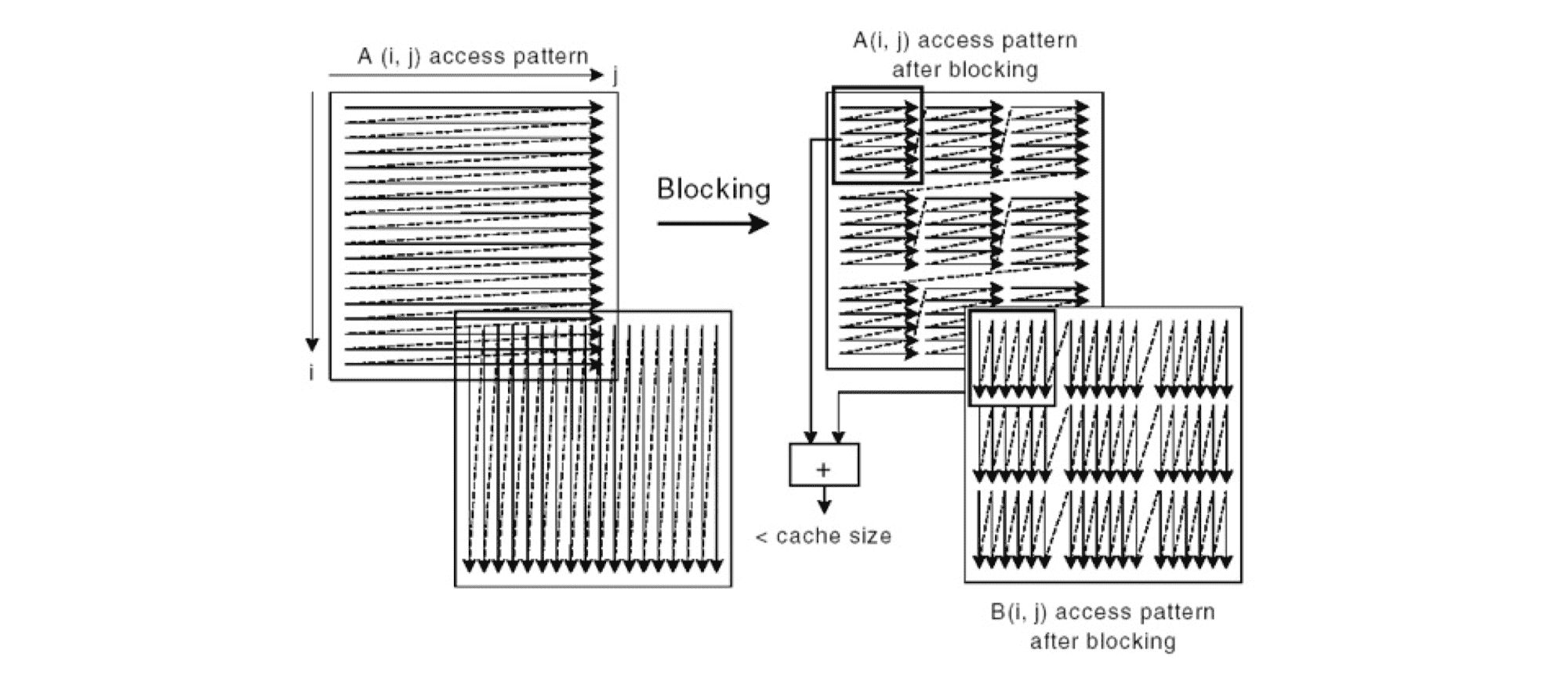

循环重排
内外层循环重排,改善空间局部性,并最大限度地利用引入缓存的数据。对循环进行重新排序,以最大程度地减少跨步访问并将访问模式与内存中的数据存储模式对齐。

循环融合
循环融合将相邻或紧密间隔的循环融合在一起,减少的循环开销和增加的计算密度可改善软件流水线,数据结构的缓存局部性增加。

循环拆分
拆分主要是将循环分成多个循环,可以在有条件的循环中使用,拆分为无条件循环和有条件循环。
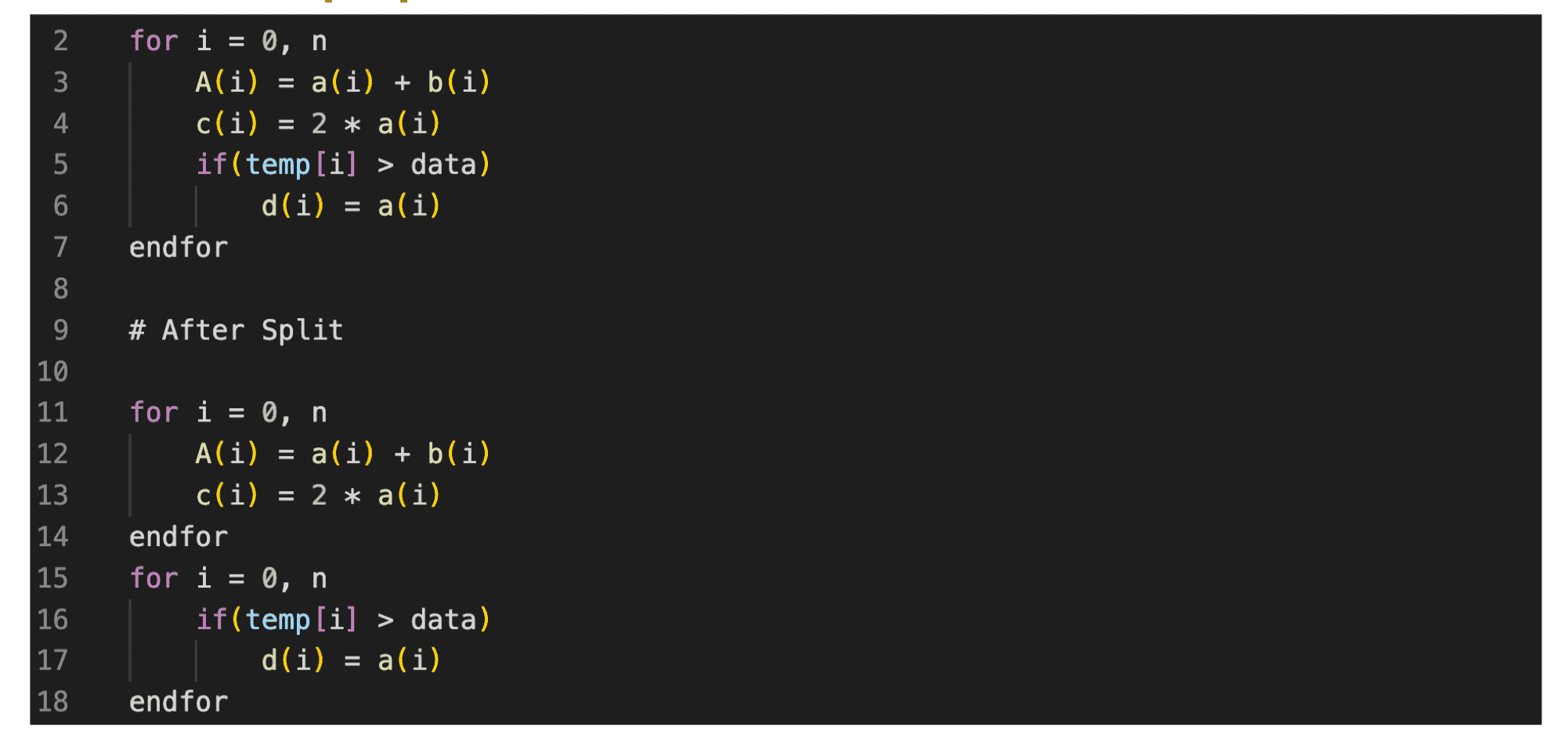
算子指令优化
向量化
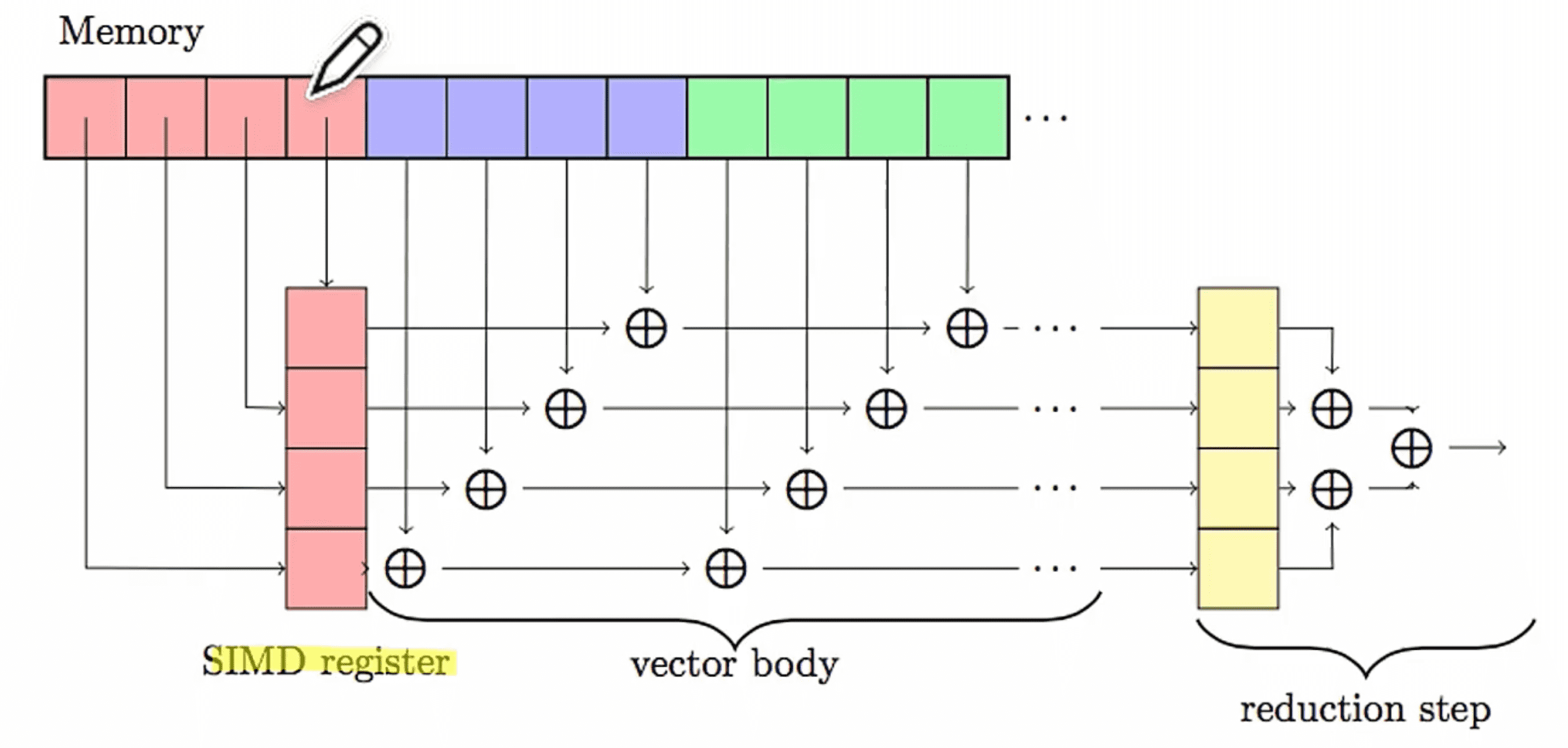

张量化
主流 CPU/GPU 硬件厂商都提供了专门角于张量化计算的张量指令,如英伟达的张量核指令、英特尔的 VN。利用张量指令的一种方法是调用硬件厂商提供的算子库,如英伟达的 cuBLAS 和 cDNN, 以及英特尔的 oneDNN 等。
然而,当模型中出现新的算子或需要进—步提高性能时,这种方法的局限性便显露无遗。
算子存储优化
延迟隐藏
延迟隐藏是指将内存操作与计算重叠,进行流水线式的排列,最大限度地提高内存和计算资源利用率的过程。
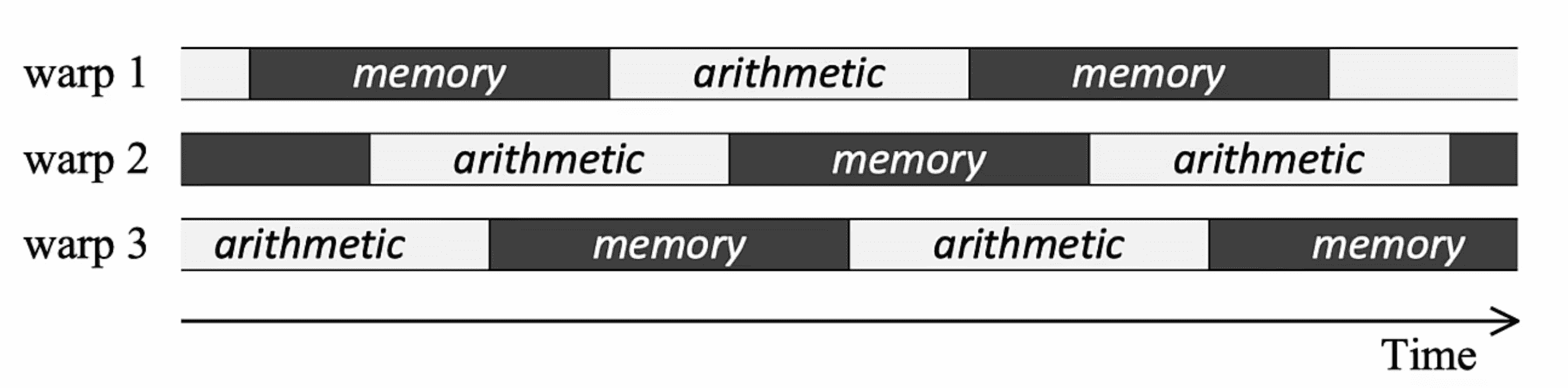
- CPU:延迟隐藏可以通过多线程,或者硬件隐式数据预取实现
- GPU:依赖于 warp schedule 对多线程的管理调度和上下文切换实现
- NPU/TPU:采用解耦访问/执行(Decoupled Access/Execute, DAE)架构
存储分配
GPU 中会有一些可编程的缓存(如 CUDA 中的 shared memory),用好这些缓存会大幅提高 kernel 性能。
Auto Tuning
对于给定的程序和目标架构,找到最优的编译优化方法。使用哪些优化方法?选择什么参数集?用什么顺序应用优化方法以达到最佳性能?
Auto Tuning in AI
- 更低实验开销
- 聚焦算子或者 kernel 级别的优化,而非整个程序
- cost model 在 CPU 上模拟 NPU 执行,训练和推理推理的模拟速度要求足够快
- 特定领域结构:针对神经网络算子或者 kernel 级别的优化
- 主要是高度循环化、张量化、并行化特点进行优化
- 大量相类似的算子计算模式
Auto Tuning 算法流程
- 参数化(parameterization):对调度优化问题进行建模,参数化优化空间一般由可参数化变换(loop)的可能参数取值组合构成,因此需要调度原语进行参数化表示。Halide 将算法和调度解耦,TVM 则提供调度模板。
- 成本模型(cost model):用来评价某一参数化下的调度性能。可以从运行时间、内存占用、编译后指令数来评价。实现方式主要有:
- 基于 NPU 硬件的黑盒模型
- 基于模拟的预定义模型
- ML-base 模型,通过机器学习模型来对调度性能进行预测(TVM 使用的方式)
- 搜索算法(search algorithm):确定初始化和搜索空间后,在搜索空间找找到达到性能最优的参数配置。常用的搜索算法有遗传算法、模拟退火算法、强化学习等。
课程笔记:AI 编译器后端优化 | 编译器