Stable Diffusion 推理优化 | 深度学习算法
本文简单介绍了在 Stable Diffusion 推理中常用的优化手段。
在 Stable Diffusion 推理中,UNet 的计算量占了 95% 以上:
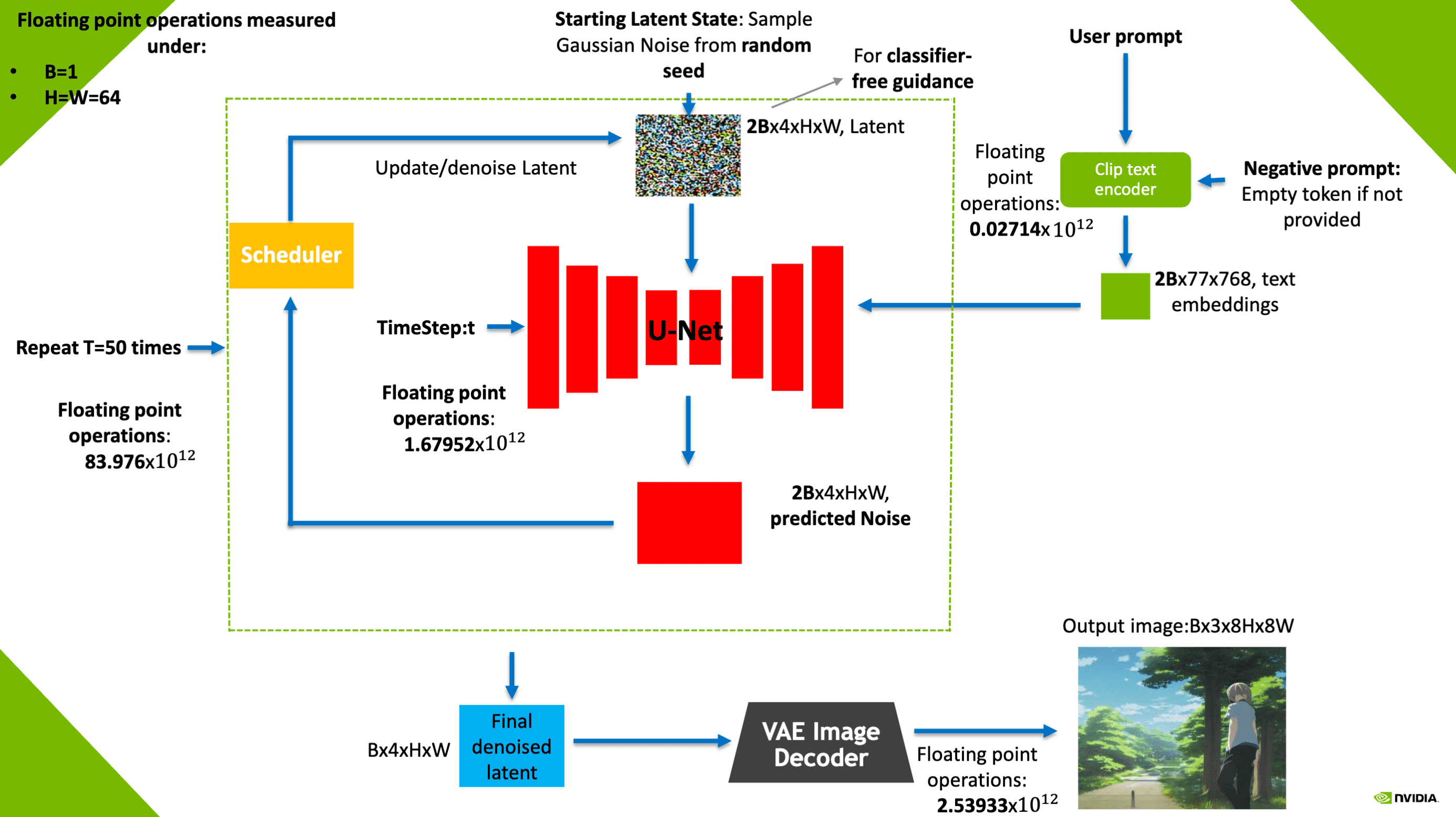
TensorRT 带来的优化
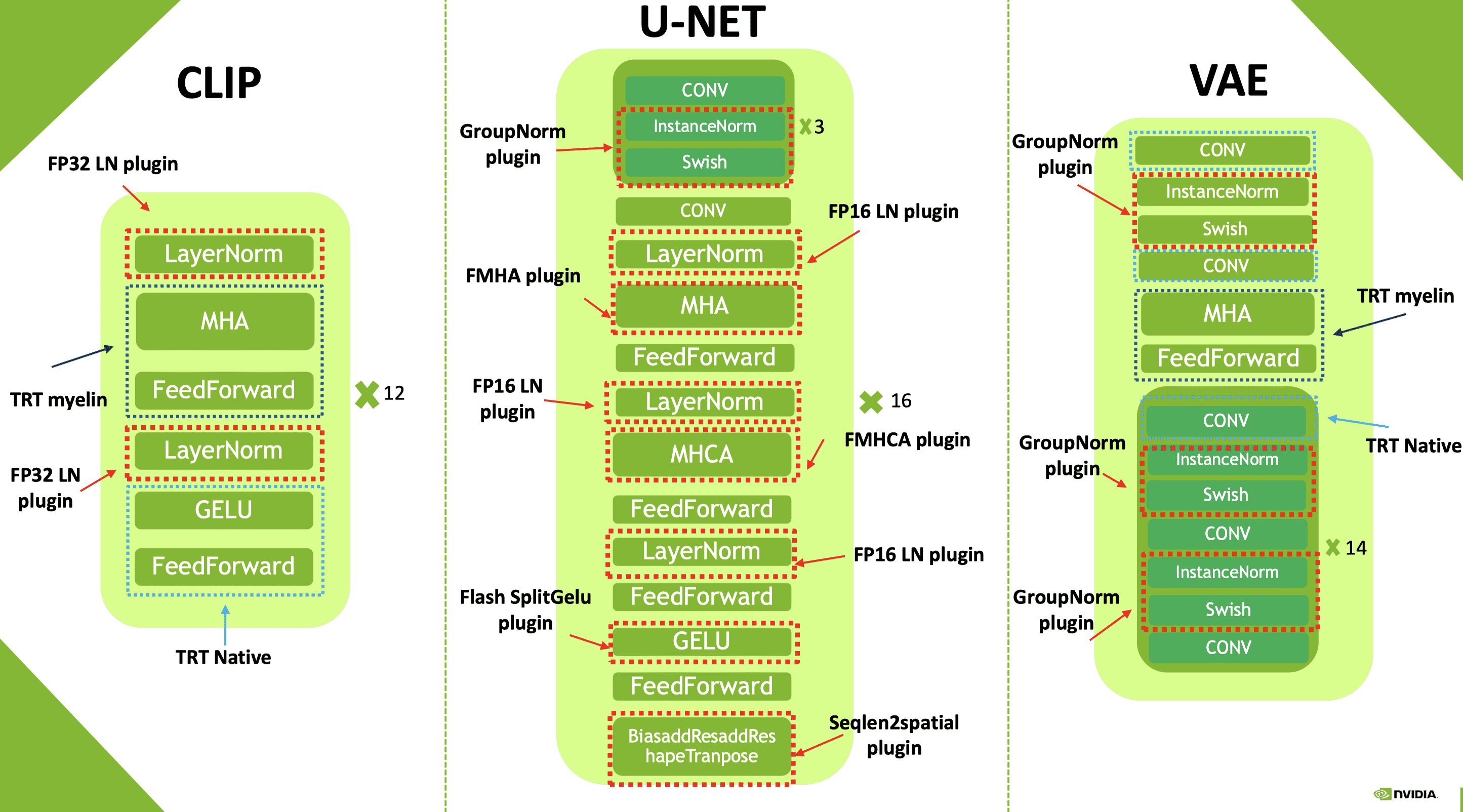
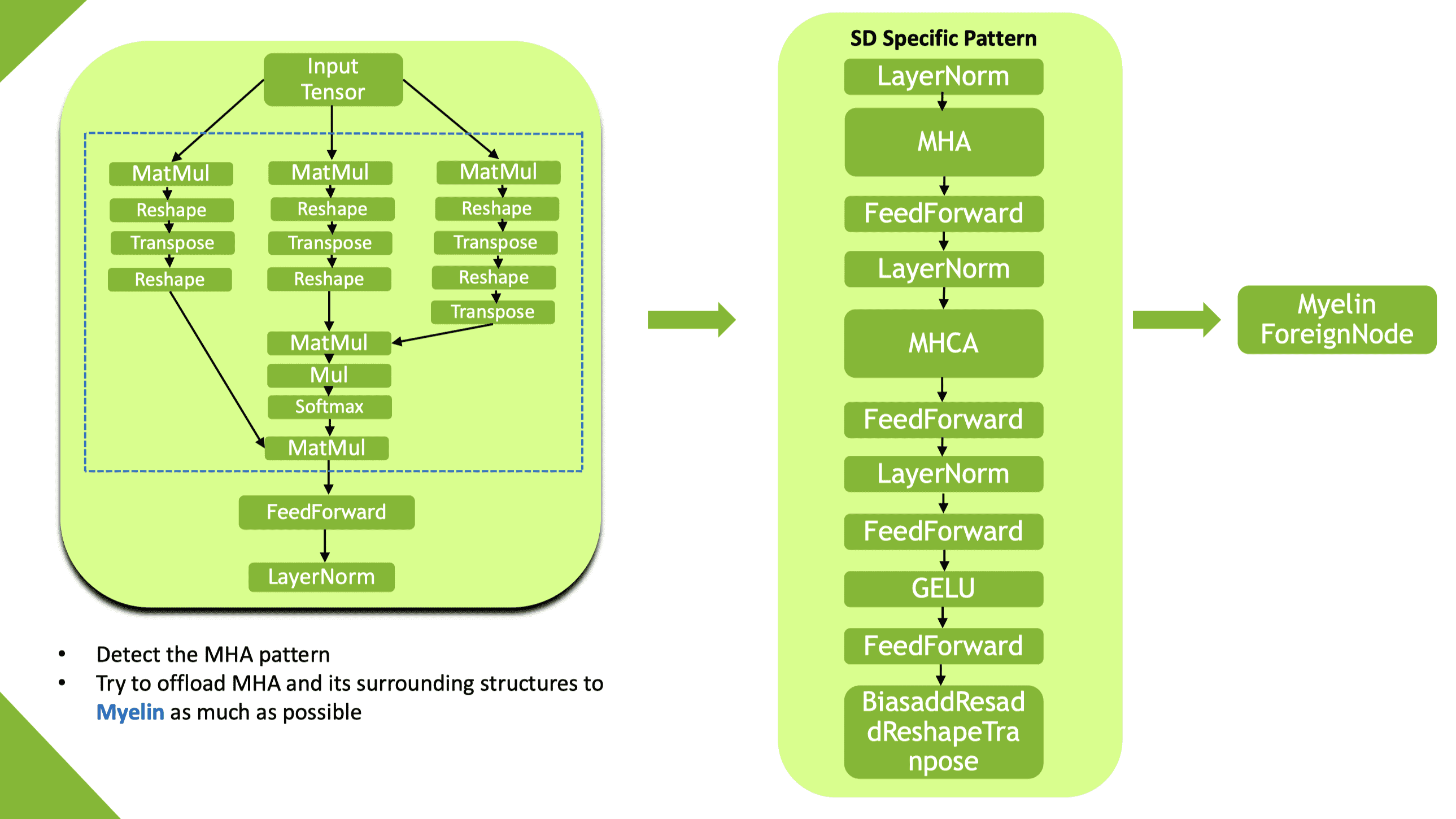
Myelin
Myelin 是集成到 TensorRT 中的图编译和执行后端的名称,为 TensorRT 提供了进行激进的算子融合能力:
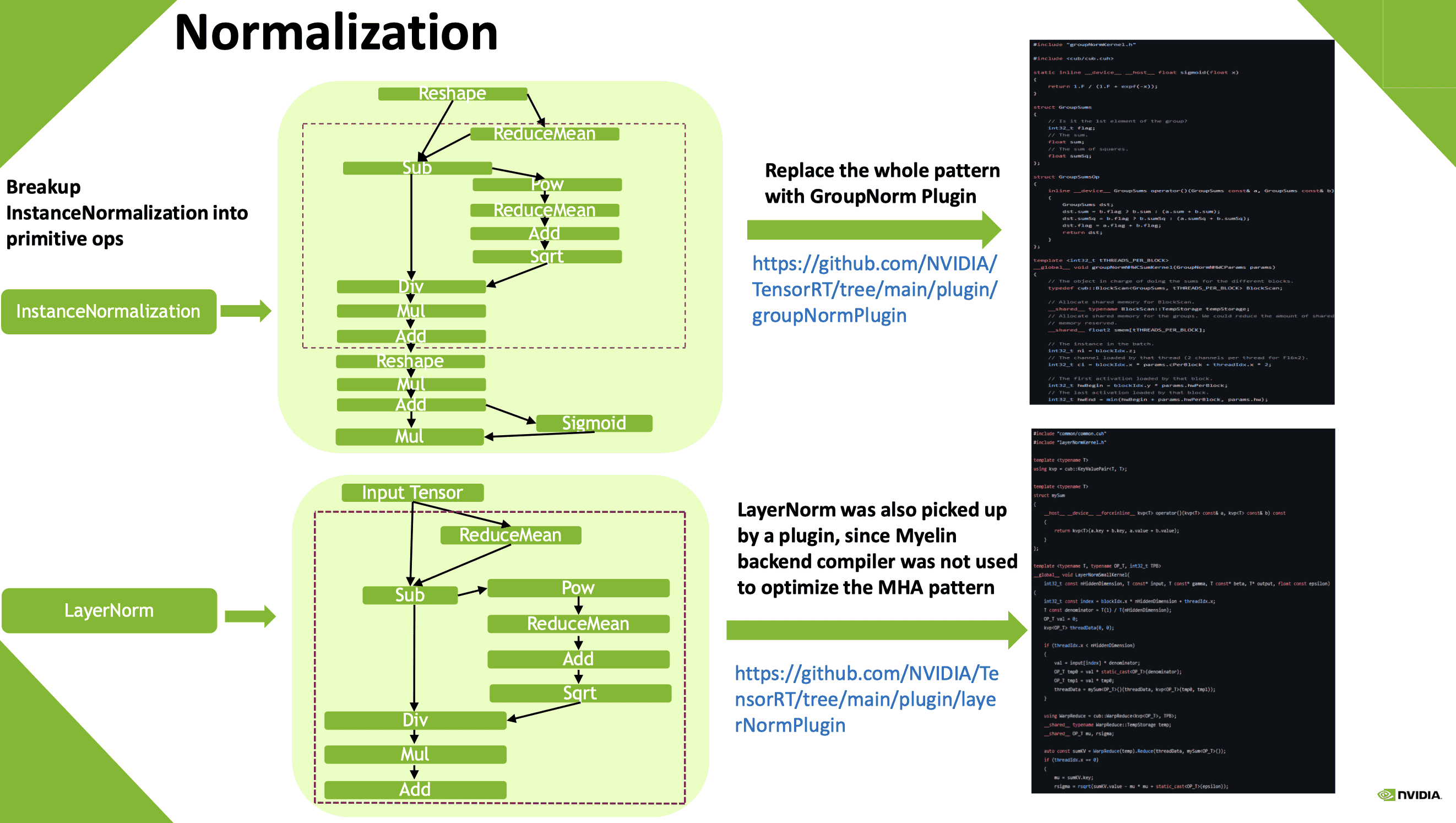
其他算子融合插件
- fMHA (fused multi-head attention) & fMHCA (fused multi-head cross attention)
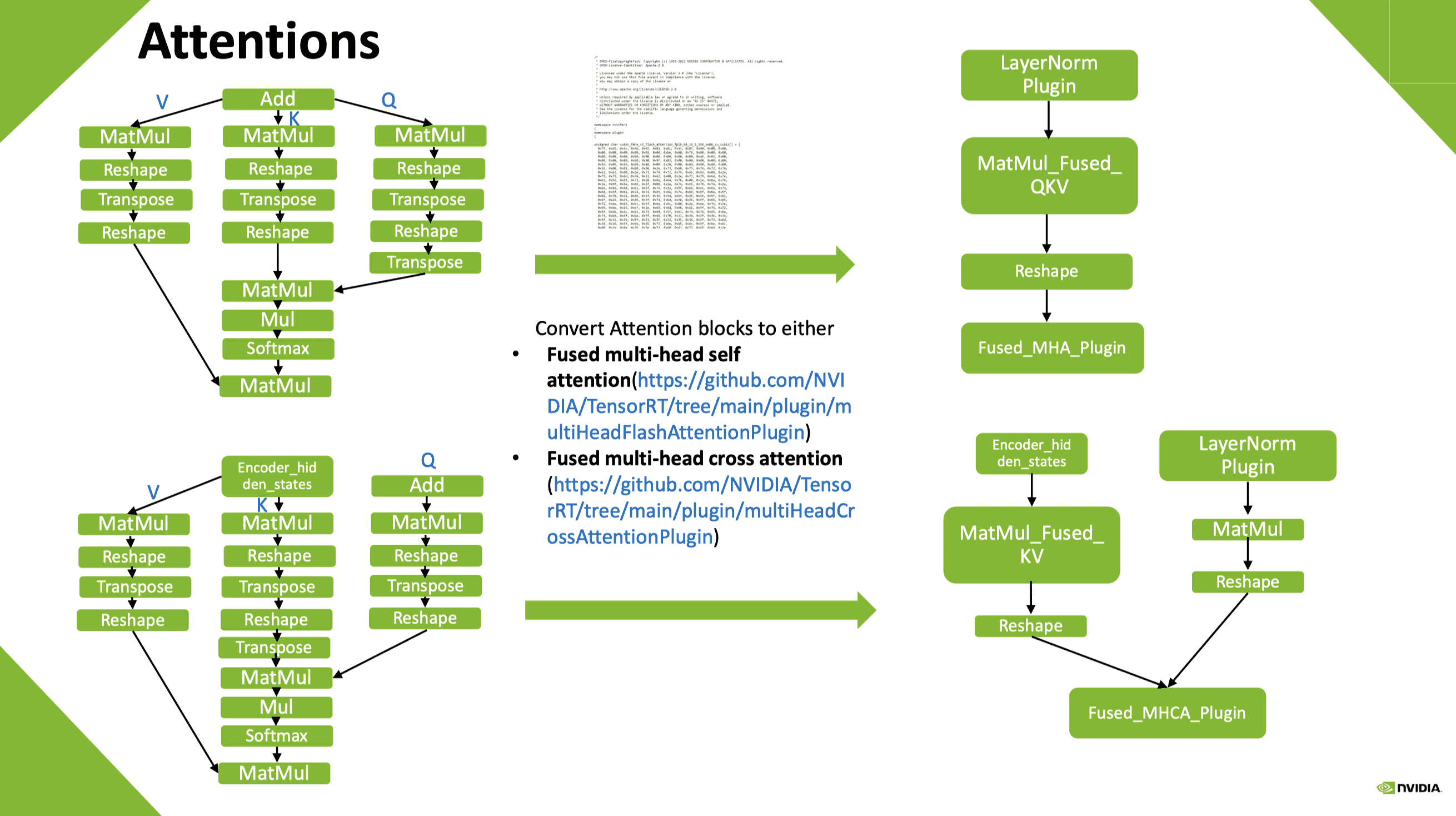
- LayerNorm & GroupNorm
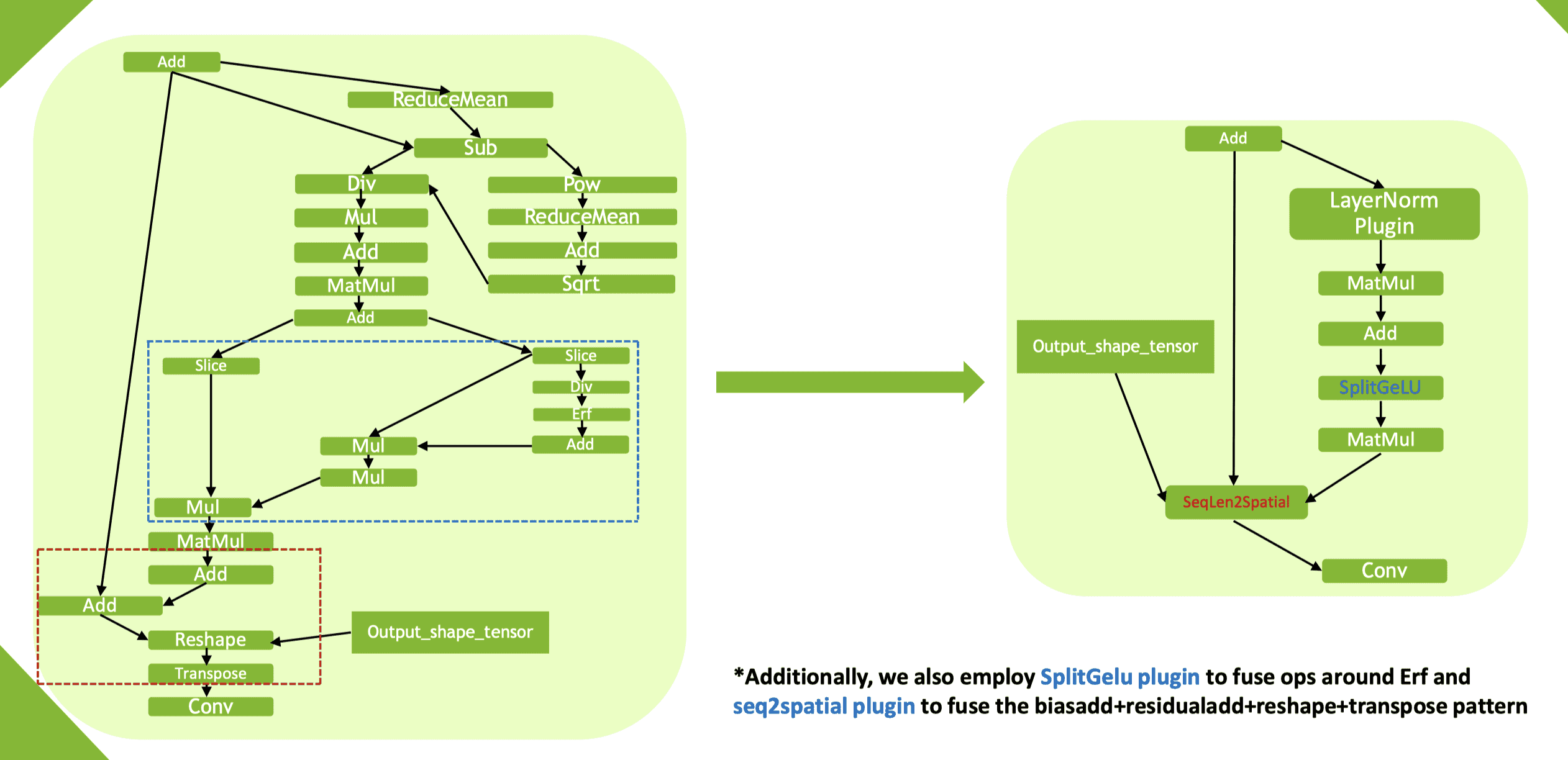
- SplitGeLU + Seq2Spatial
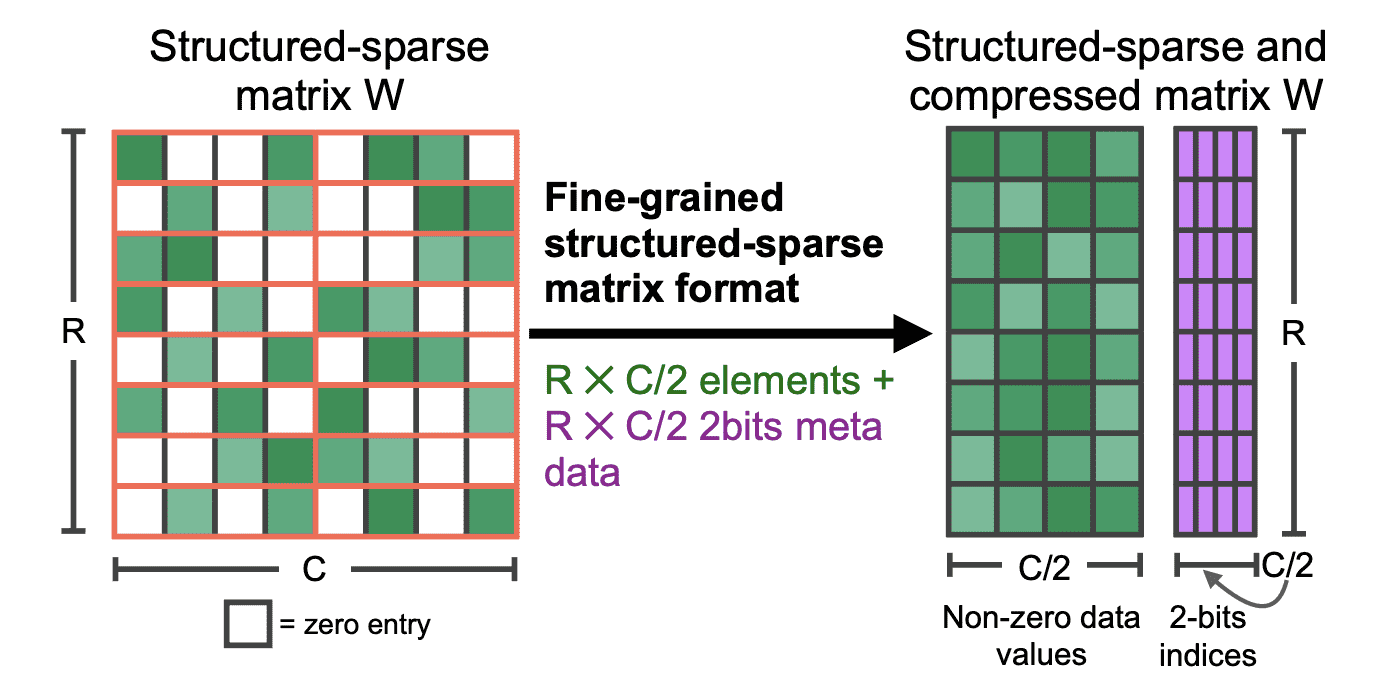
稀疏化
原理
主要采用 2:4 模式(50% 的稀疏度,每个连续 4 个块中的 2 个值为 0):
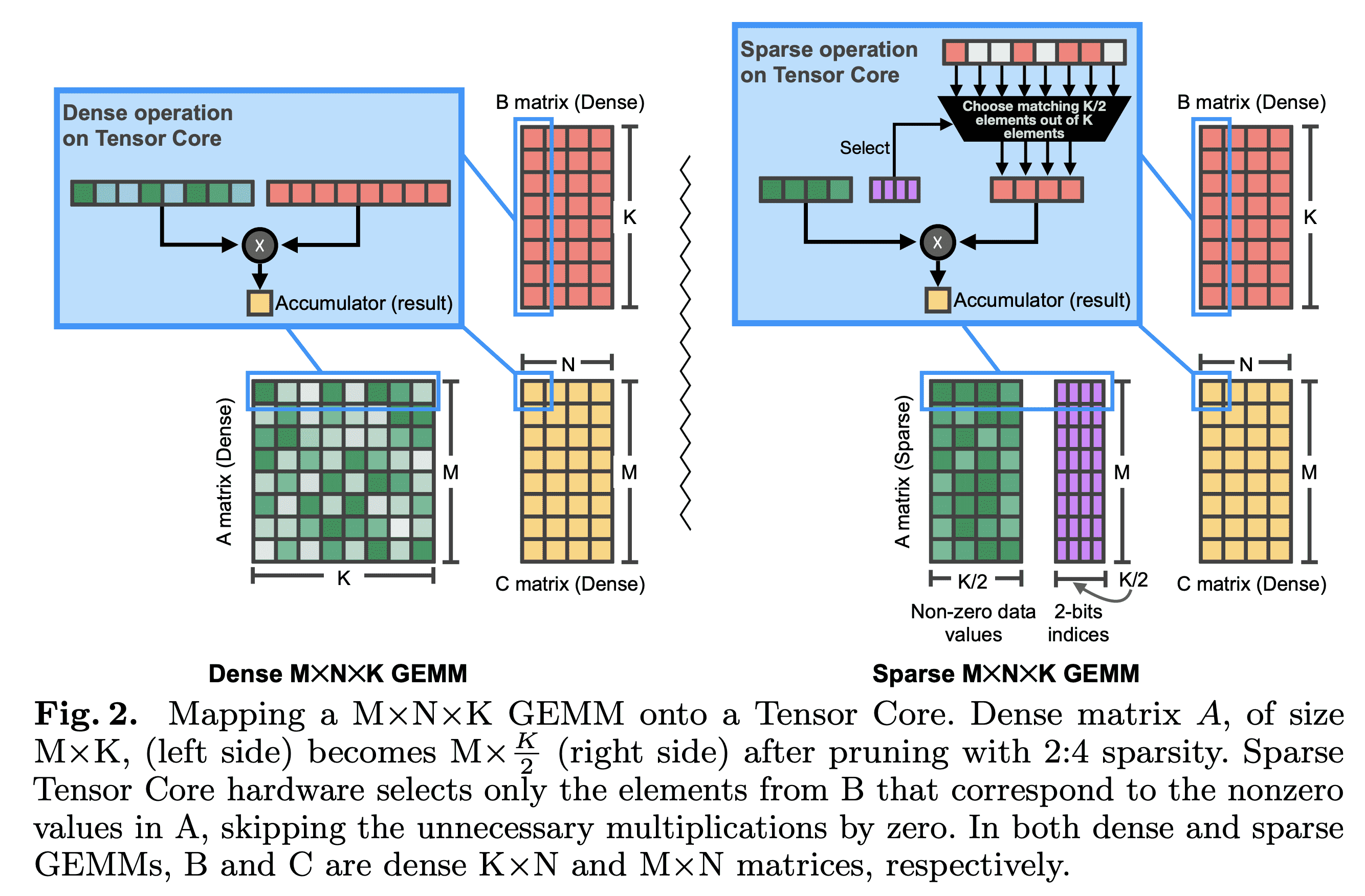
在实现上,Ampere 架构硬件层面支持稀疏计算(有专门针对稀疏计算的 Tensor Core):
使用
适用于卷积层、线性层(卷积网络、Transformer、MLP 等):
- 输入:sparse 权重、dense 激活值
- 输出:dense 激活值
训练侧:NVIDIA APEX 库
推理侧:trtexec --onnx=model.onnx --saveEngine=engine.trt --explicitBatch --sparsity=enable --fp16
推理时,batch size = 2 时比较合适:
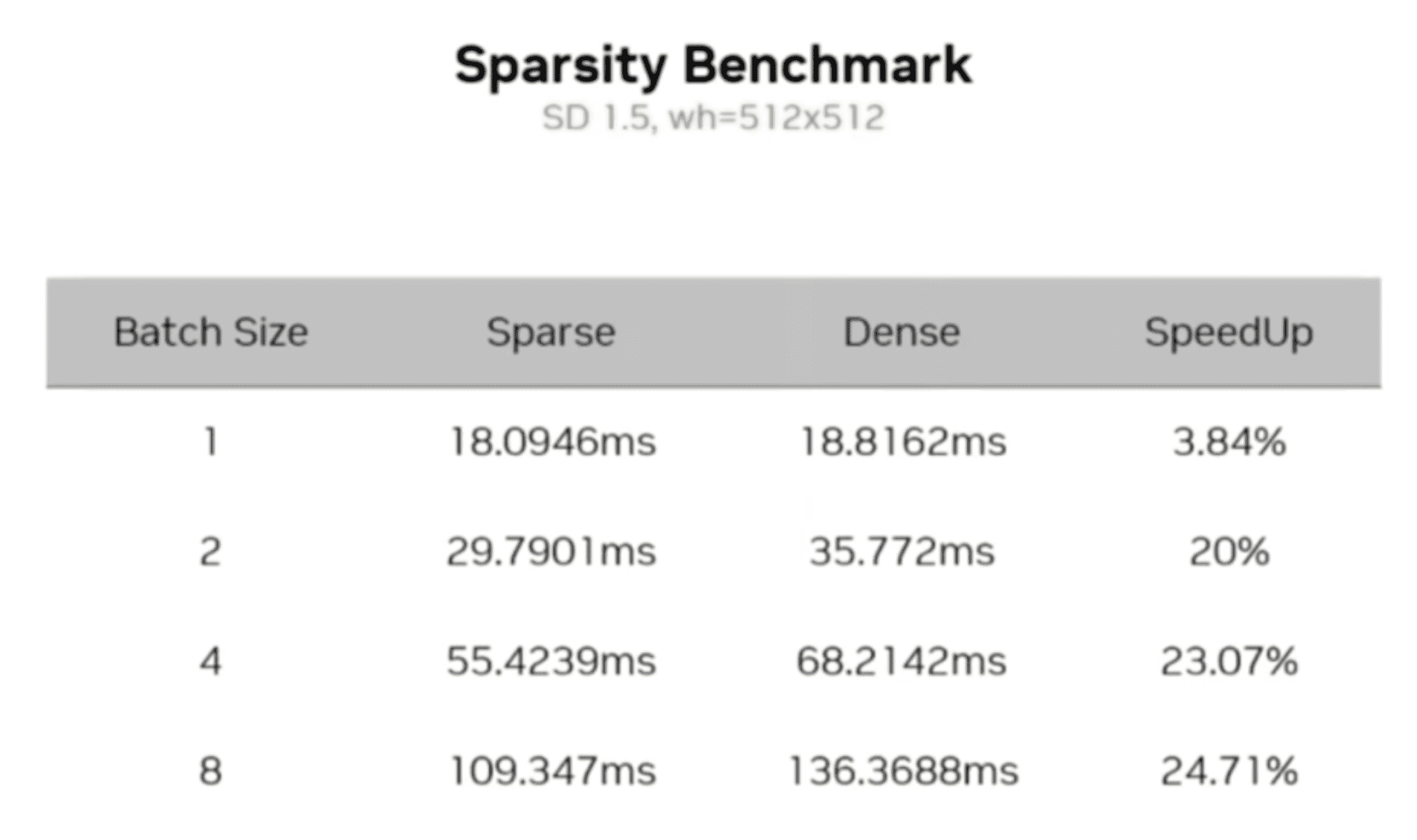
效果
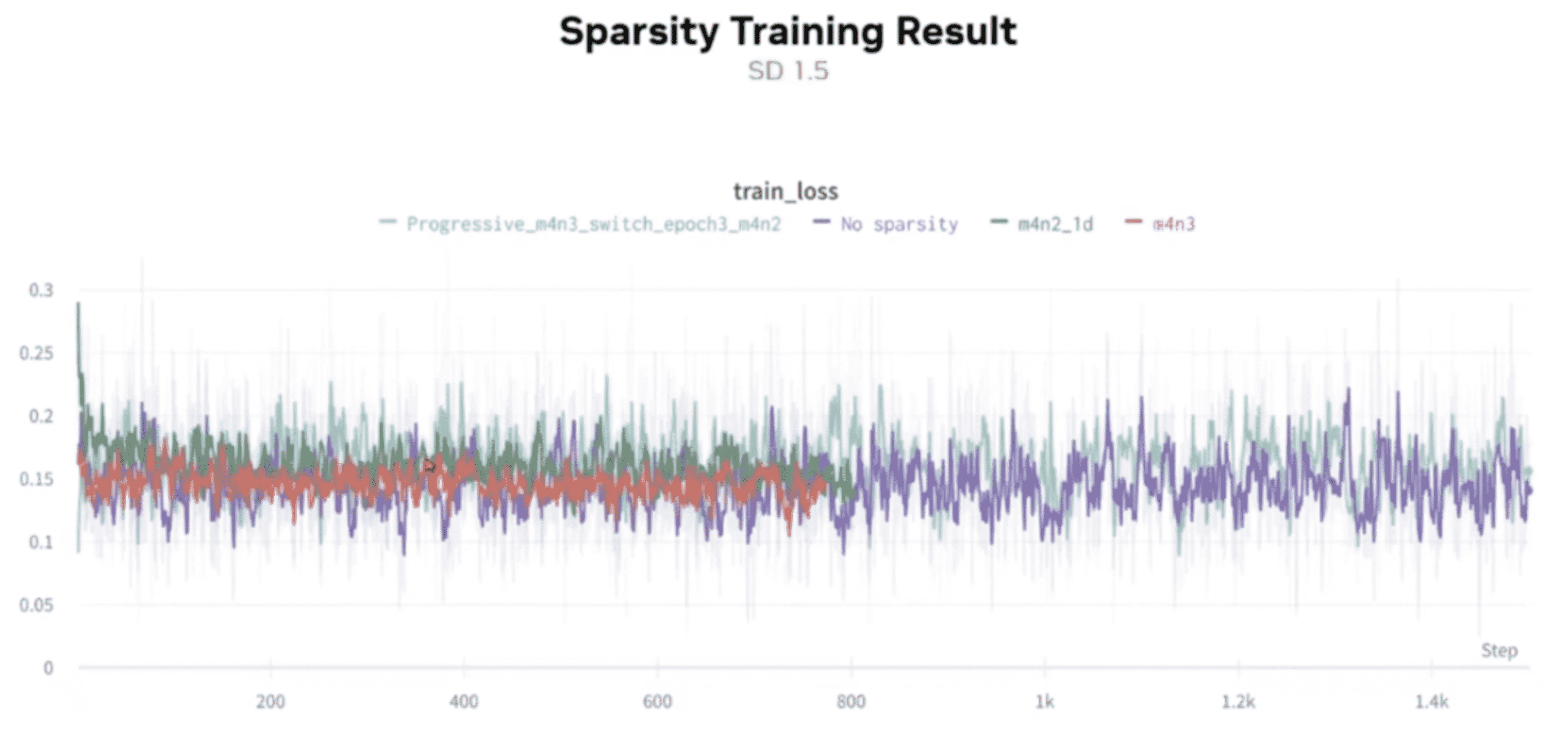
- no sparsity:不做稀疏化
- m4n2:50% 的稀疏化
- m4n3:25% 的稀疏化
- progressive_m4n3_switch_epoch3_m4n2:渐进稀疏化,先是 25% 稀疏化,然后过渡到 50% 稀疏化
在 SD 1.5 中,稀疏化对最终效果没有影响:

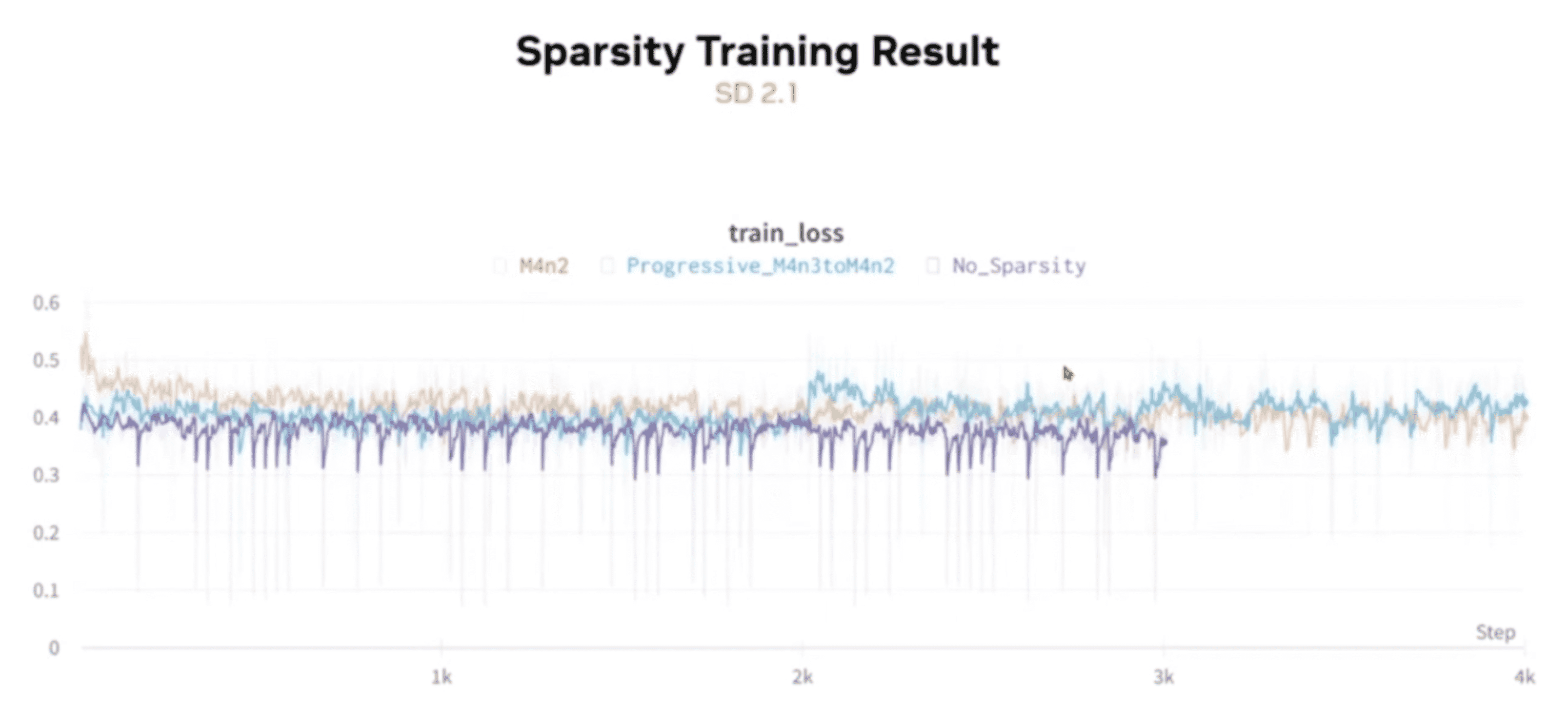
在 SD 2.1 中,稀疏化对最终效果 有影响:

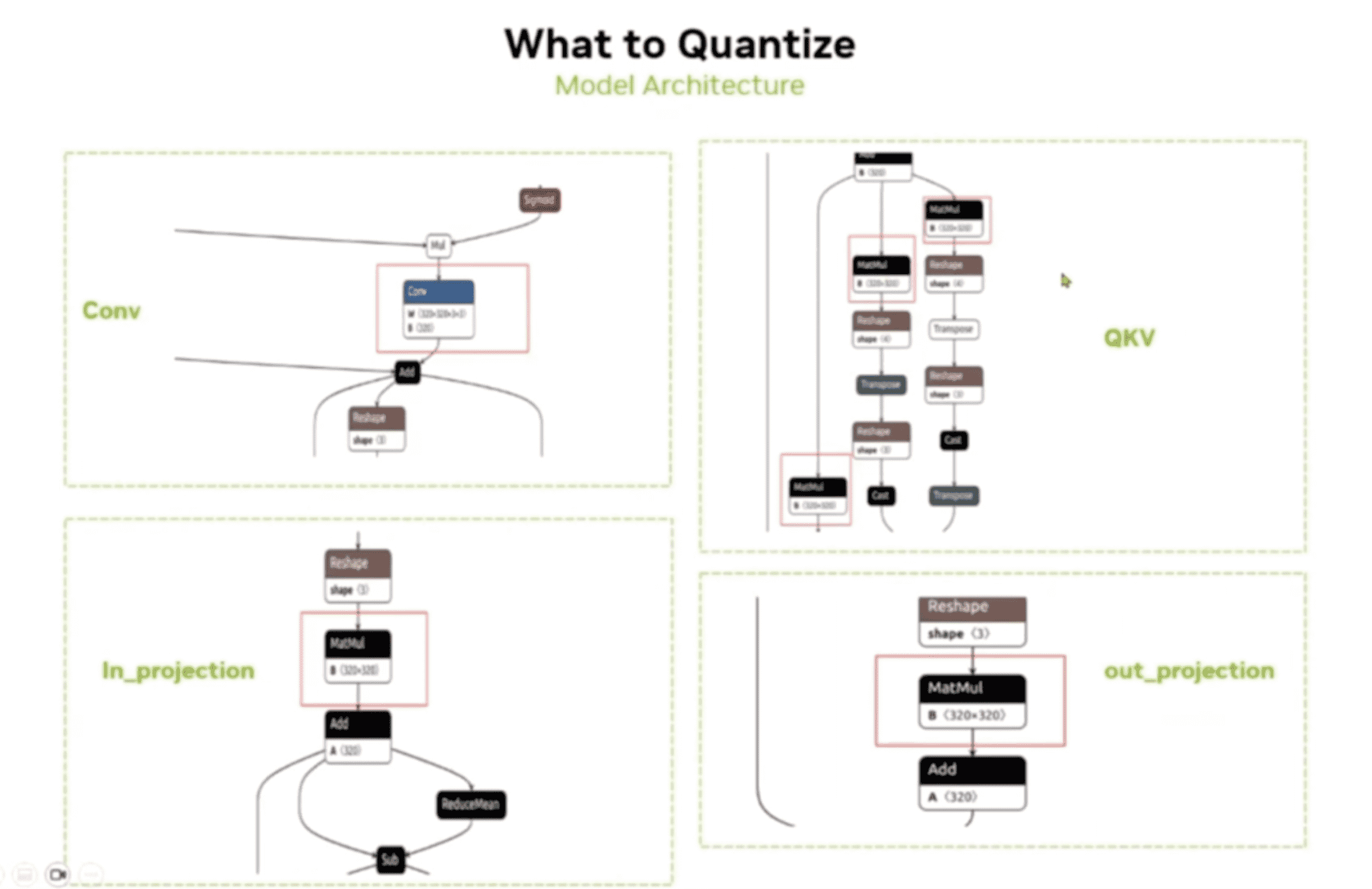
量化
PTQ

QAT

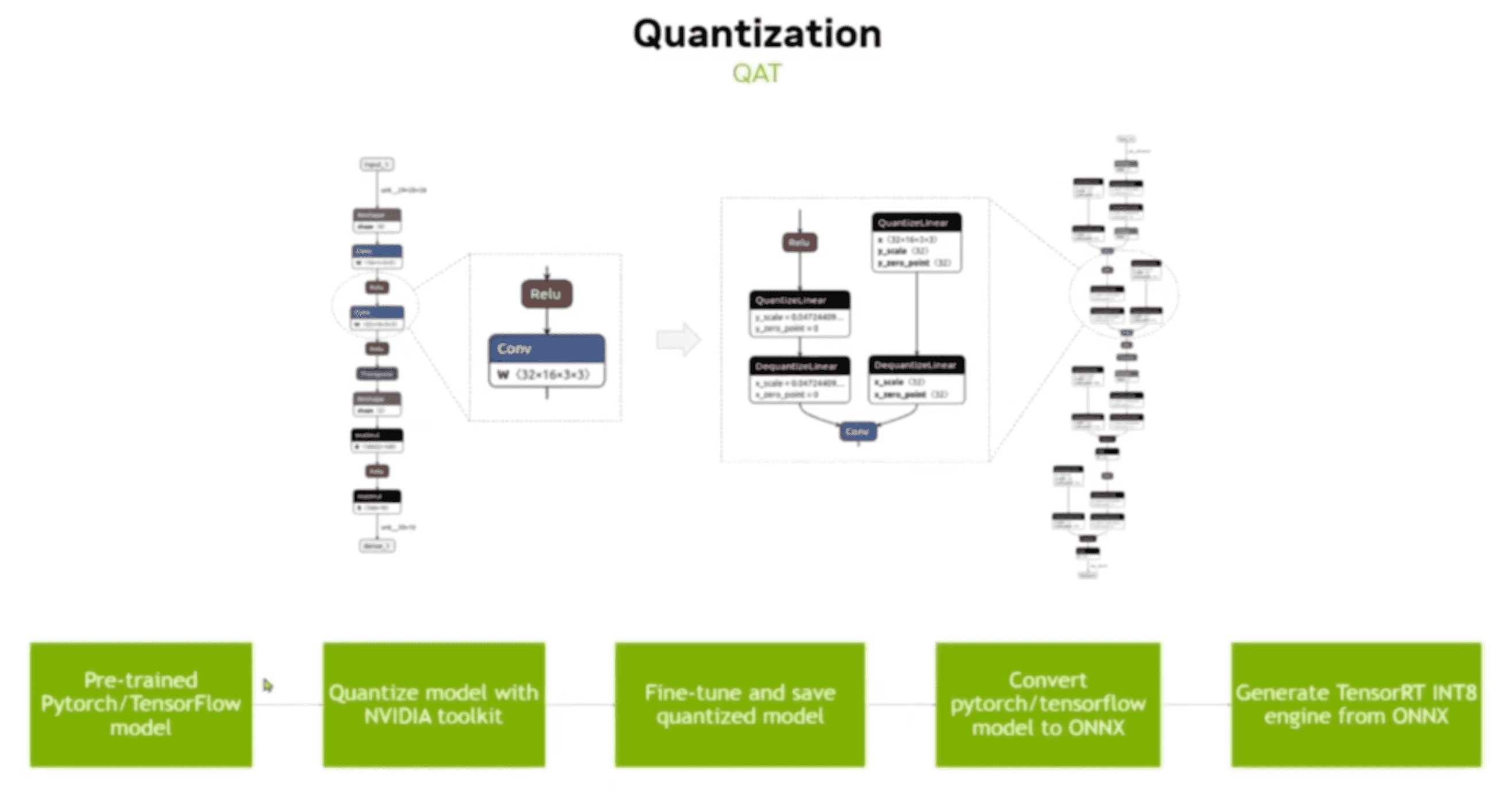
如下图所示,对 relu 层和 conv 层都插入了 Q(uant)DQ(DeQuant) 节点,然后进行训练:
参考
Stable Diffusion Inference Optimization
Detail when Myelin is used and why
MHA/FMHA vs FlashAttention profile
Accelerating Inference with Sparsity Using the NVIDIA Ampere Architecture and NVIDIA TensorRT
Stable Diffusion 推理优化 | 深度学习算法