CUDA C++ 编程指引:内存层级 | CUDA
本系列参考自 CUDA C++ Programming Guide。
设备内存
运行时库提供了分配、释放、拷贝设备内存以及在设备和主机间传输数据的函数。这里的设备内存,指的是全局内存 + 常量内存 + 纹理内存。这张图很好地展示了内存结构:
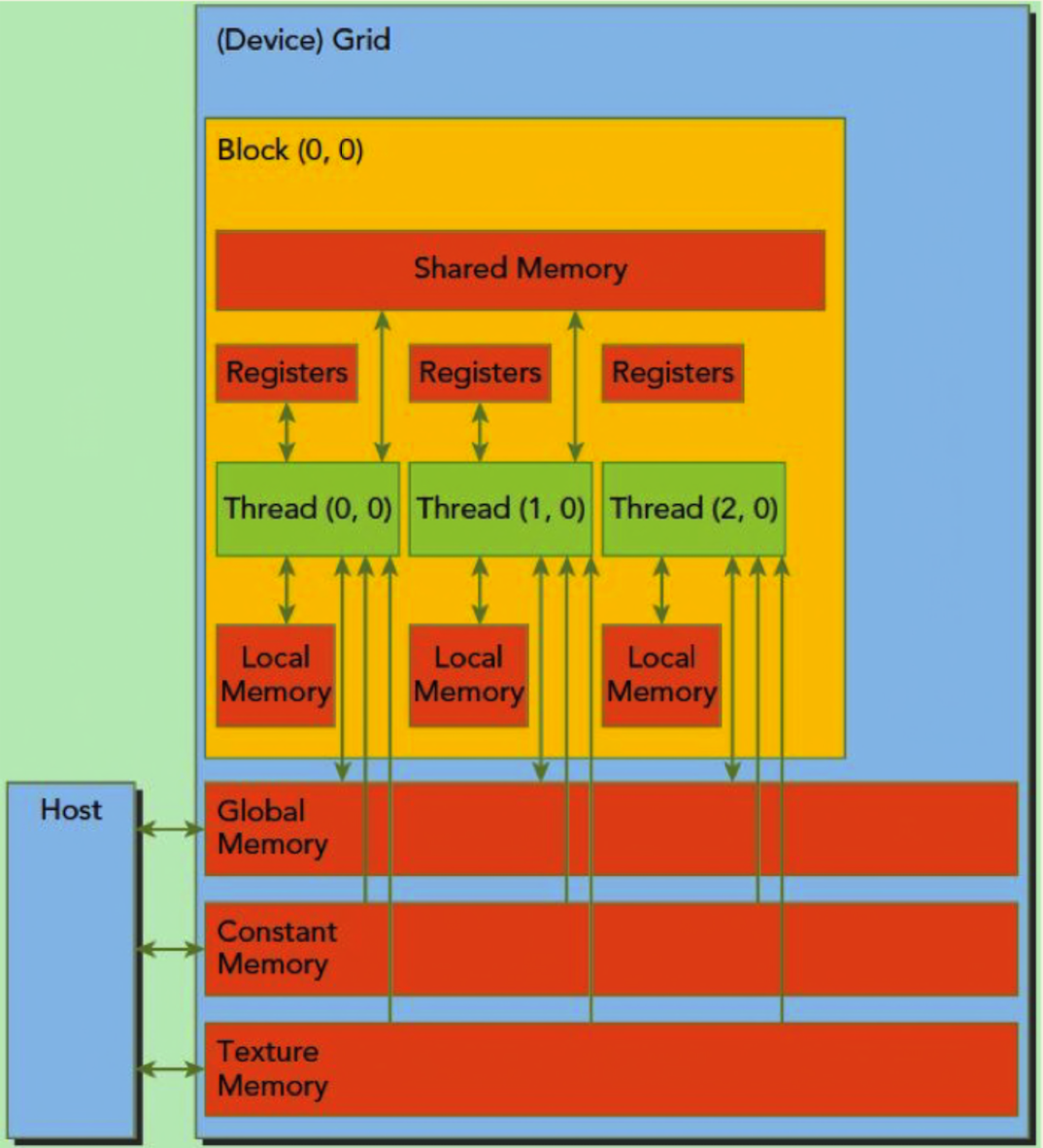
设备内存分为线性内存和 CUDA 数组。CUDA 数组是不透明的内存布局,为纹理获取做了优化。线性内存可以用 cudaMalloc() 分配内存,用 cudaFree() 释放内存,用 cudaMemcpy() 复制数据,用 cudaMemset() 赋值。在之前的向量加法代码中,向量要从主机内存复制到设备内存。
1 | // Device code |
对于二维或三维数组,可以使用 cudaMallocPitch() 和 cudaMalloc3D() 来分配内存。这两个函数会自动 padding 以满足内存对齐的要求。返回的步长(pitch)必须用于访问数组元素。下面的代码分配了一个尺寸为 width*height 的二维浮点数组,同时演示了怎样在设备代码中遍历数组元素。
1 | // Device code |
下面的代码分配了一个尺寸为 width*height*depth 的三维浮点数组,同时演示了怎样在设备代码中遍历数组元素。
1 | // Device code |
全局内存
全局内存是空间最大,延迟最高,GPU 最基础的内存。“全局”指明了其生命周期。任意 SM 都可以在整个程序的生命期中获取其状态。全局内存中的变量既可以是静态也可以是动态声明。全局内存的分配使用 cudaMalloc,释放使用 cudaFree。全局变量可以通过 32-byte、64-byte 或者 128-byte 三种格式传输。这些 memory transaction 必须是对齐的,也就是说首地址必须是 32、64 或者 128 的倍数。优化 memory transaction 对于性能提升至关重要。
共享内存
共享内存使用 __shared__ 限定词修饰。使用共享内存,可以获得等同于 L1 cache 的访存速度,其速度远快于全局内存。但是并不是什么时候都可以使用共享内存来获取加速的。例如内核函数计算出来结果后,如果这个结果只需要传输回主机端,而不需要再次被用到时,直接写回全局内存会比较快。如果先写回共享内存,再写回全局内存,反而会比较缓慢。一般来讲,当需要频繁读写,或是有原子操作时,使用共享内存替代全局内存,会取得比较大的增益。
注意,共享内存只能为 block 内的线程共享。如果需要整个 grid 中线程都能访问,则需要全局内存或常量内存。
常量内存
如果要在设备内存中定义全局变量,则需要使用使用 __constant__ 或 __device__ 来修饰,并使用 cudaMemcpyToSymbol() 和 cudaMemcpyFromSymbol() 来读写。当使用 __constant__ 关键字时,是申请了一块常量内存;而使用 __device__ 时,是普通的全局内存。因此 __device__ 申请的内存需要申请,而 __constant__ 不用。不管是全局内存,还是常量内存,需要用带有 Symbol 的函数拷贝。
下面的示例复制了一些主机内存中的数组到常量内存中:
1 | __constant__ float constData[256]; |
纹理内存
纹理内存使用一个只读 cache(per-SM)。纹理内存实际上也和全局内存在一块,但是它有自己专有的只读 cache。纹理内存是针对 2D 空间局部性的优化策略,所以 thread 要获取 2D 数据就可以使用纹理内存来达到很高的性能。
常量内存和纹理内存的作用可以参考《CUDA学习5 常量内存与纹理内存》。
锁页内存(Page-Locked Host Memory)
锁页内存指的是主机端上不会被换出到虚拟内存(位于硬盘)上的内存。使用 cudaHostAlloc() 分配锁页内存,使用 cudaFreeHost() 释放锁页内存,或者使用 cudaHostRegister() 来将 malloc() 分配的内存指定为锁页内存。
使用锁页内存有许多优点:
- 使用锁页内存后,锁页内存与设备内存之间的数据传输,可以使用流的方式,和内核函数并发执行;
- 使用锁页内存后,可以将锁页内存映射到设备内存上,减少了和设备间的数据拷贝;
- 对于使用前端总线的系统,使用锁页内存可以提升主机端到设备端传输的带宽;如果将锁页内存指定为合并写(write-combining),则可以进一步提高带宽。
可移植内存(Portable Memory)
一块锁页内存可被系统中的所有设备使用,但是默认的情况下,上面说的使用锁页内存的好处只有分配它时正在使用的设备可以享有。为了让所有线程可以享受锁页内存的好处,可以在使用 cudaHostAlloc() 分配时传入 cudaHostAllocPortable 标签,或者在使用 cudaHostRegister() 时传入 cudaHostRegisterPortable 标签。
合并写内存(Write-Combining Memory)
默认情况下,锁页内存是可缓存的。可以在使用 cudaHostAlloc() 分配时传入 cudaHostAllocWriteCombined 标签使其被分配合并写的。合并写内存没有 L1&L2 cache,所以应用的其它部分就有更多的缓存可用。另外合并写内存在通过 PCI-e 总线传输时不会被监视(snoop),这能够获得高达 40% 的传输加速。
因为没有缓存,所以主机读取合并写内存极慢,所以合并写内存应当只用于那些主机只写的场景。
被映射内存(Mapped Memory)
在一些设备上,在使用 cudaHostAlloc() 分配时传入 cudaHostAllocMapped 标签或者在使用 cudaHostRegister() 分配锁页内存时使用 cudaHostRegisterMapped 标签,可分配一块被映射到设备地址空间的锁页内存。这块内存有两个地址:一个在主机内存上,一个在设备内存上。主机指针是由 cudaHostAlloc() 或 malloc() 返回的,设备指针由 cudaHostGetDevicePointer() 返回,可以使用这个设备指针在内核函数中访问这块内存。唯一的例外是主机和设备使用统一地址空间时,具体参看相应的章节。
从内核中直接访问主机内存有许多优点:
- 无需在设备上分配内存,也不用显式传输数据;数据传输是在内核需要的时候隐式进行的。
- 无需使用流重叠数据传输和内核执行;数据传输和内核执行自动重叠。
由于被映射锁页内存在主机和设备间共享,应用必须使用流或事件来同步内存访问以避免任何潜在的读后写、写后读或写后写危害。
为了在给定的主机线程中能够检索到被映射锁页内存的设备指针,必须在调用任何 CUDA 运行时函数前调用 cudaSetDeviceFlags() 并传入 cudaDeviceMapHost 标签。否则,cudaHostGetDevicePointer() 将会返回错误。如果设备不支持被映射锁页,cudaHostGetDevicePointer() 将会返回错误。可以通过查看设备的 canMapHostMemory 属性来确认是否可以使用该功能,如果支持映射锁页内存,将会返回 1。注意:从主机和其它设备的角度看,操作被映射锁页内存的原子函数不是原子的。
统一虚拟地址空间
当程序是 64 位程序时,所有主机端内存,以及计算能力 ≥2.0 的设备的内存是统一编址的。所有通过 CUDA API 分配的主机内存和设备内存,都在统一编址的范围内,有自己的虚拟地址。因此:
- 可以通过
cudaPointerGetAttributes(),来确定指针所指的内存处在主机端还是设备端。 - 进行拷贝时,可以将
cudaMemcpy***()中的cudaMemcpyKind参数设置为cudaMemcpyDefault,去让函数根据指针所处的位置自行判断应该是从哪里拷到哪里。 - 使用
cudaHostAlloc()分配的锁页内存,自动是 Portable 的,所有支持统一虚拟编址的设备均可访问。cudaHostAlloc()返回的指针,无需通过cudaHostGetDevicePointer(),就可以直接被设备端使用。 - 可以通过查询
unifiedAddressing来查看设备是否支持统一虚拟编址,返回 1 则支持。
参考
CUDA C++ 编程指引:内存层级 | CUDA