课程笔记:核函数执行流程 | Taichi
本文是 Taichi 官方教学视频的笔记:
Overview
下面是一个简单的 Taichi 程序的示例:
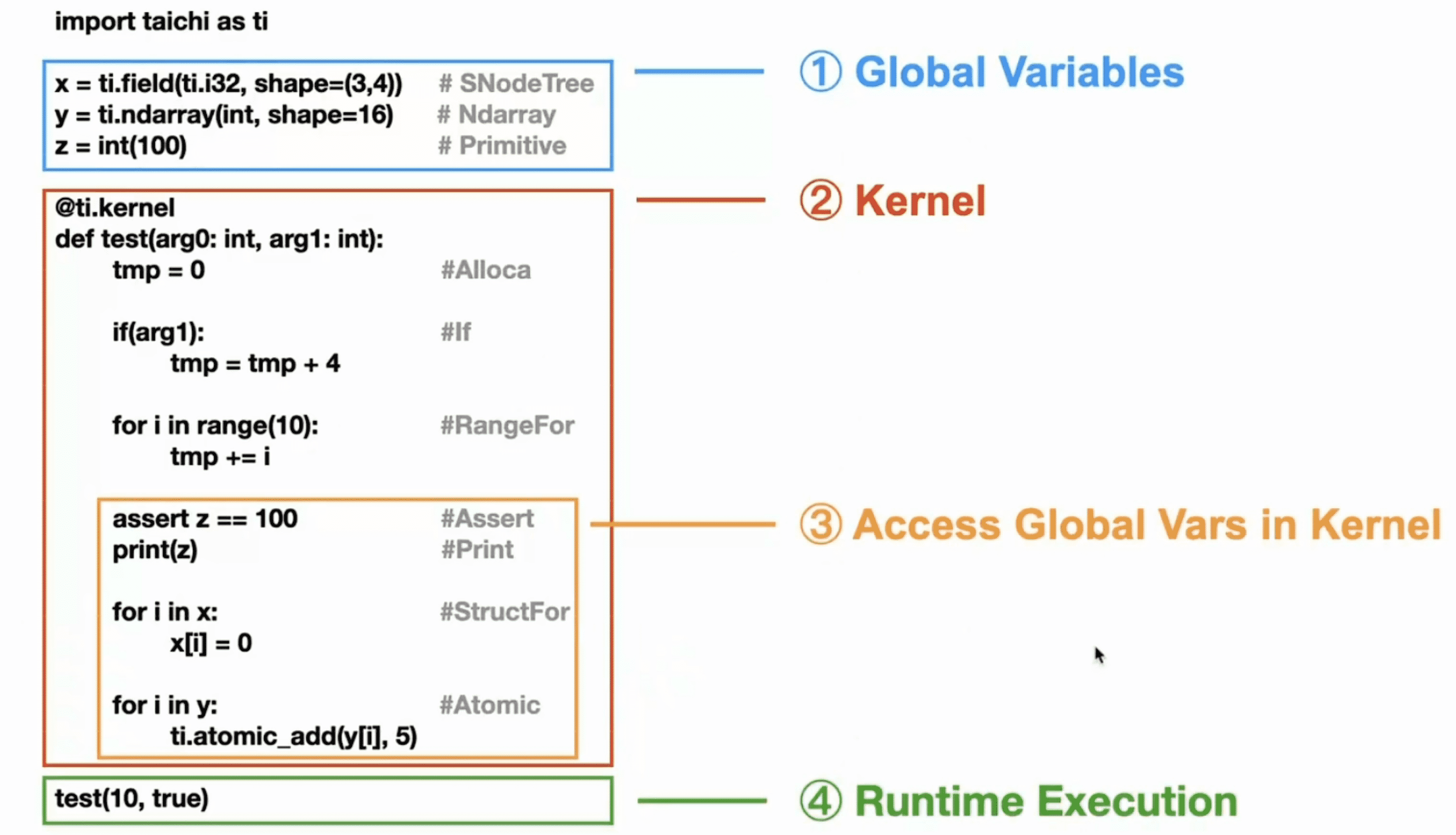
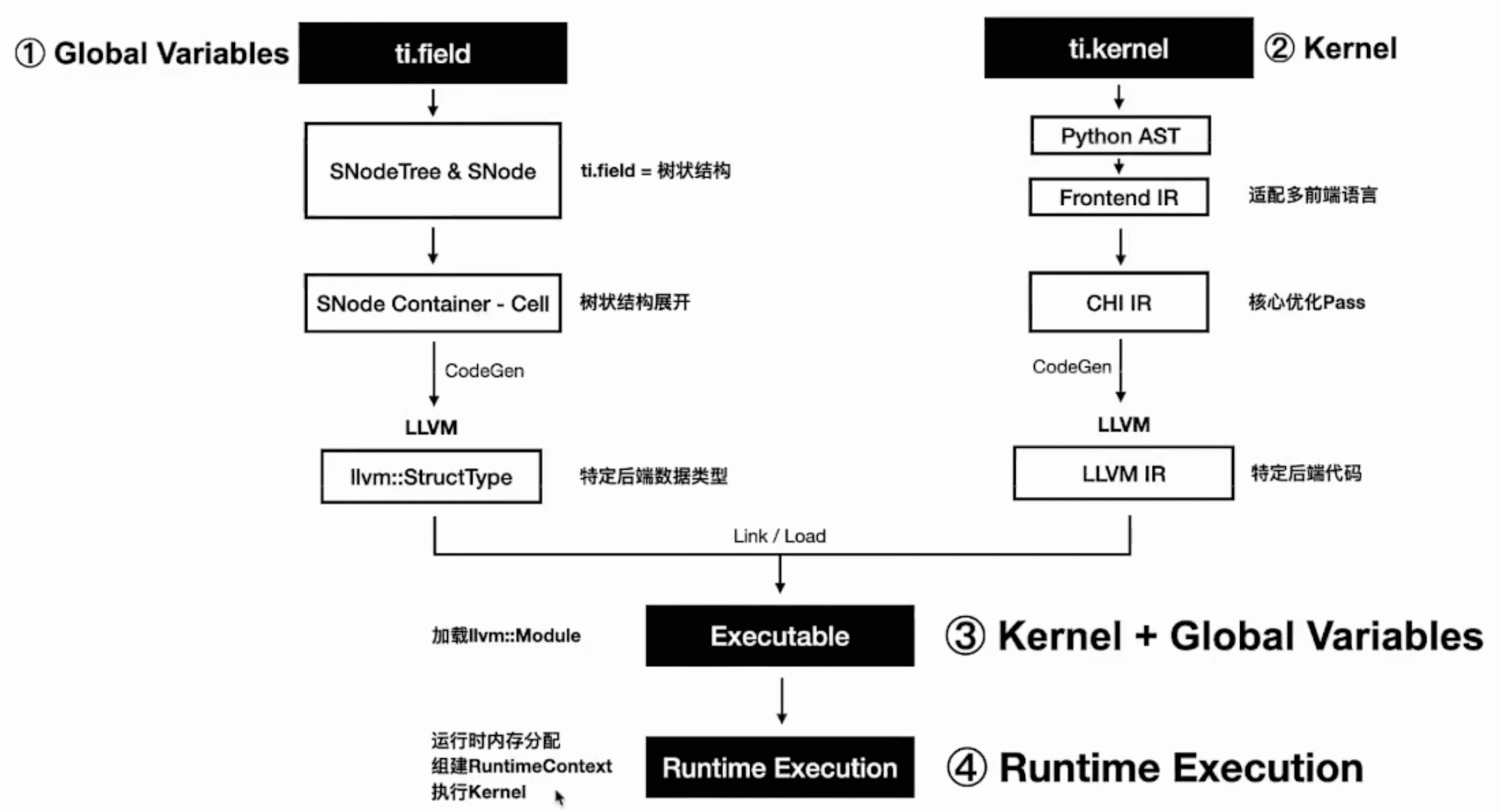
数据容器的编译和指令的编译是分开的:
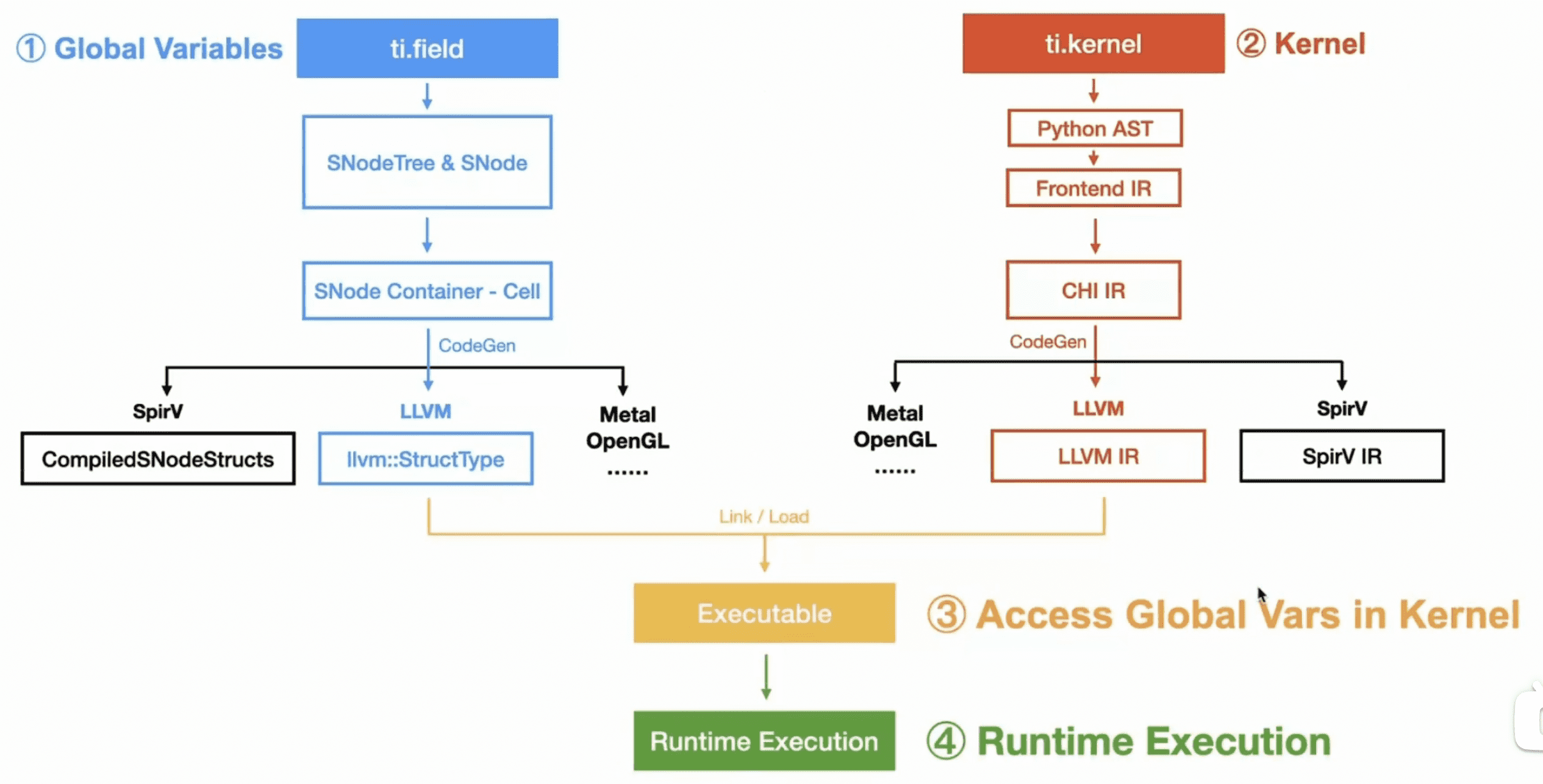
Kernel Compilation
在编译 kernel 时,经历了以下步骤:
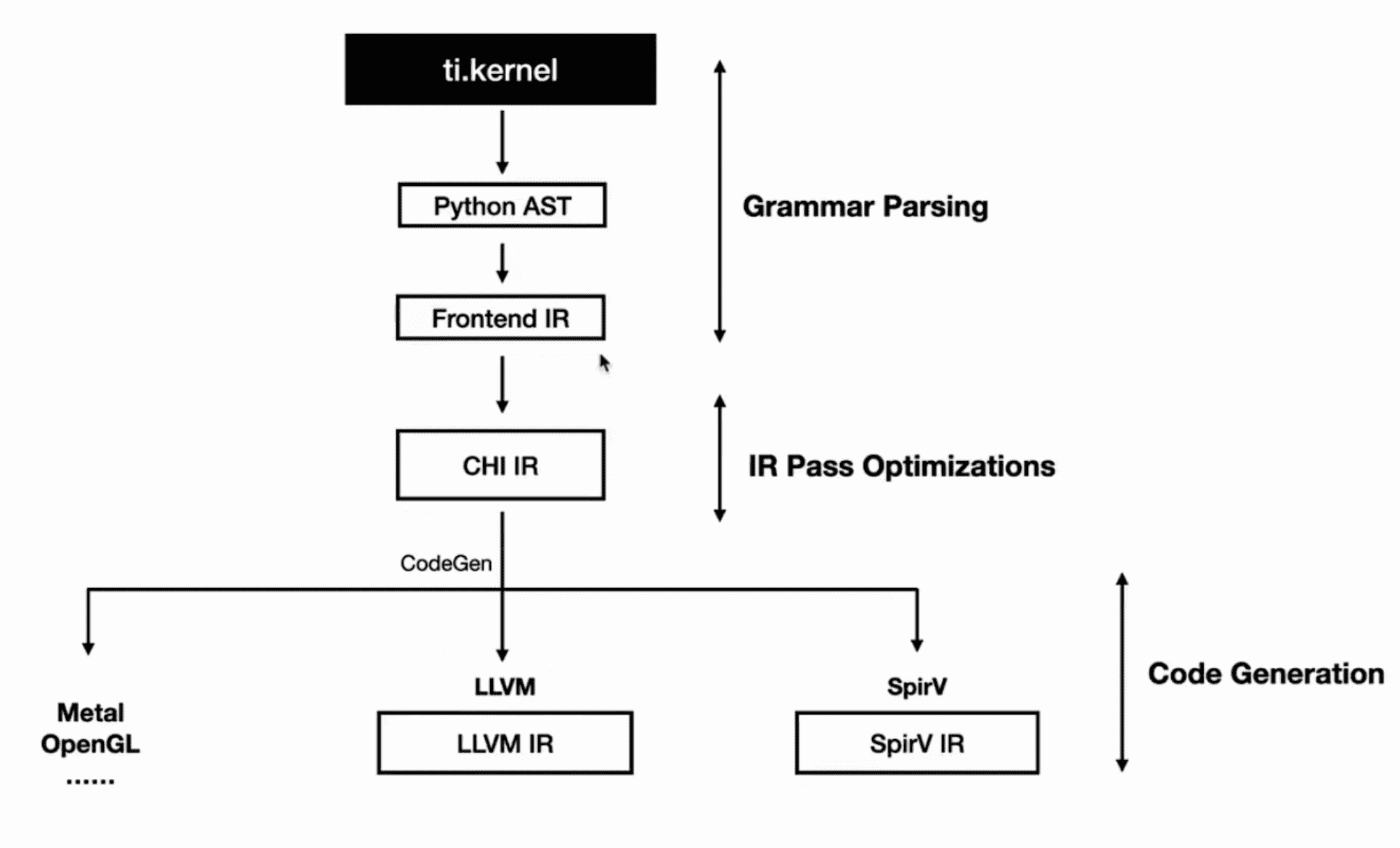
这个过程和其他的一些使用 Python 作为前端的 JIT/AOT DSL 差不多,都是将 Python AST 转换为自己的 IR 然后进行编译器后端优化。
接下来以这样一个简化的 Taichi kernel 为例看一下 kernel 具体是如何完成编译的:
1 |
|
在进行 kernel 函数调用的时候,就开始了编译:
1 | class Kernel: |
Python AST -> Frontend IR
python/taichi/lang/ast/ast_transformer.py
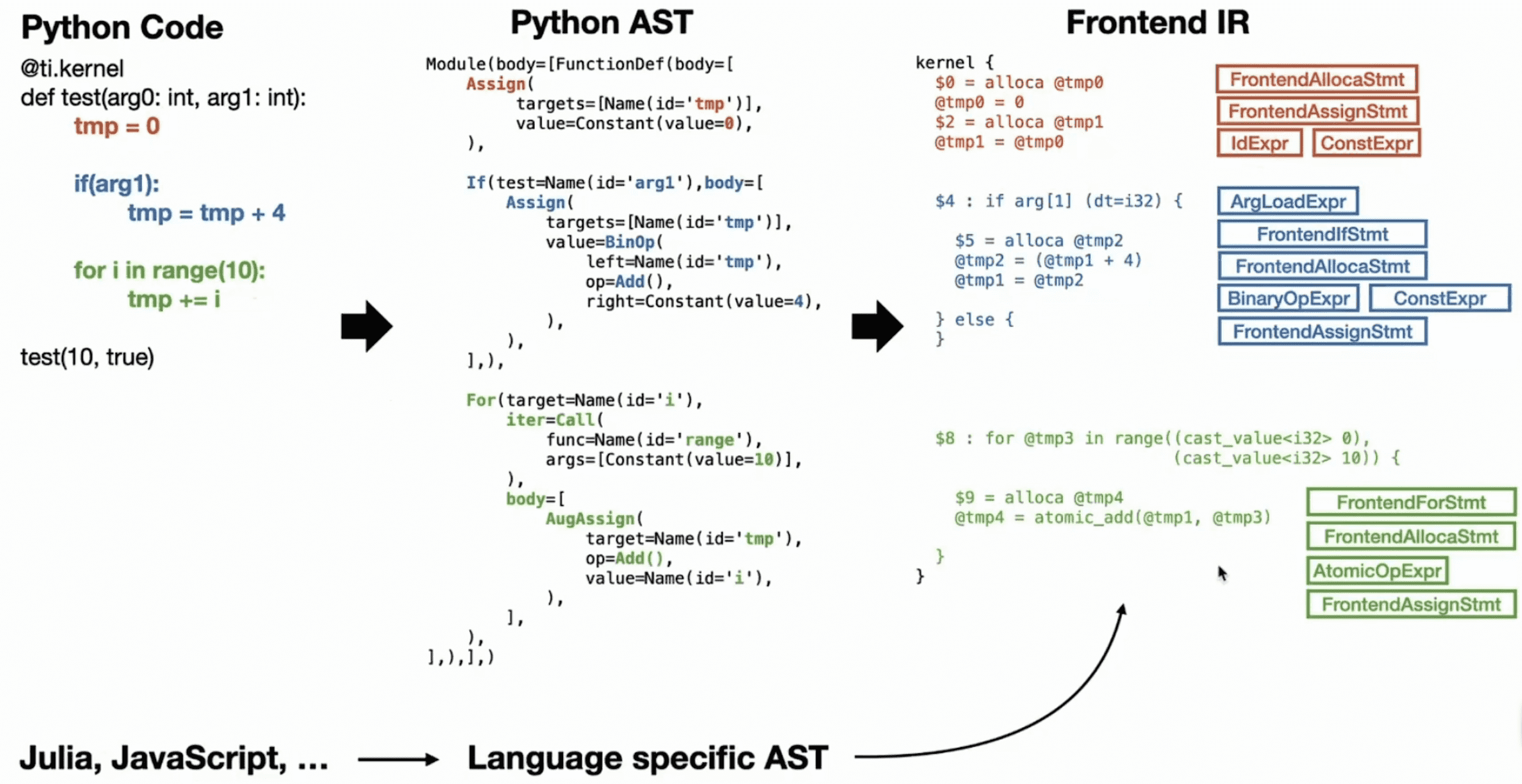
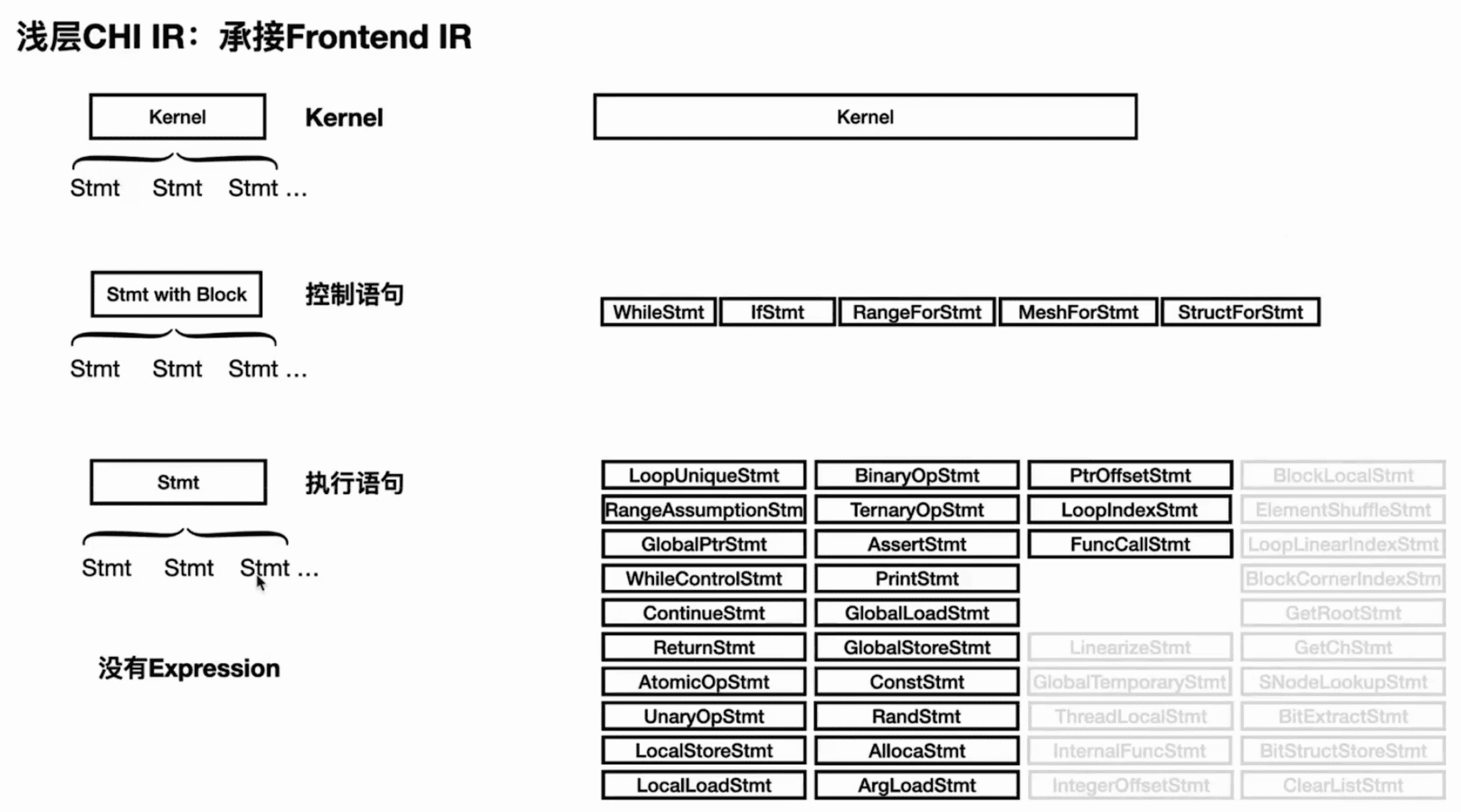
Frontend IR 的层级结构如下:
taichi/ir/frontendir.h

Frontend IR -> 浅层 CHI IR
Frontend IR 基本上只承担了一个承接的作用,接下来需要 lowering 成 CHI IR 才能做进一步的优化。逻辑上可以将 CHI IR 分为浅层和深层。对于到浅层 CHI IR 的转换,只是做了语义上的对等转换:
taichi/transforms/lower_ast.cpp
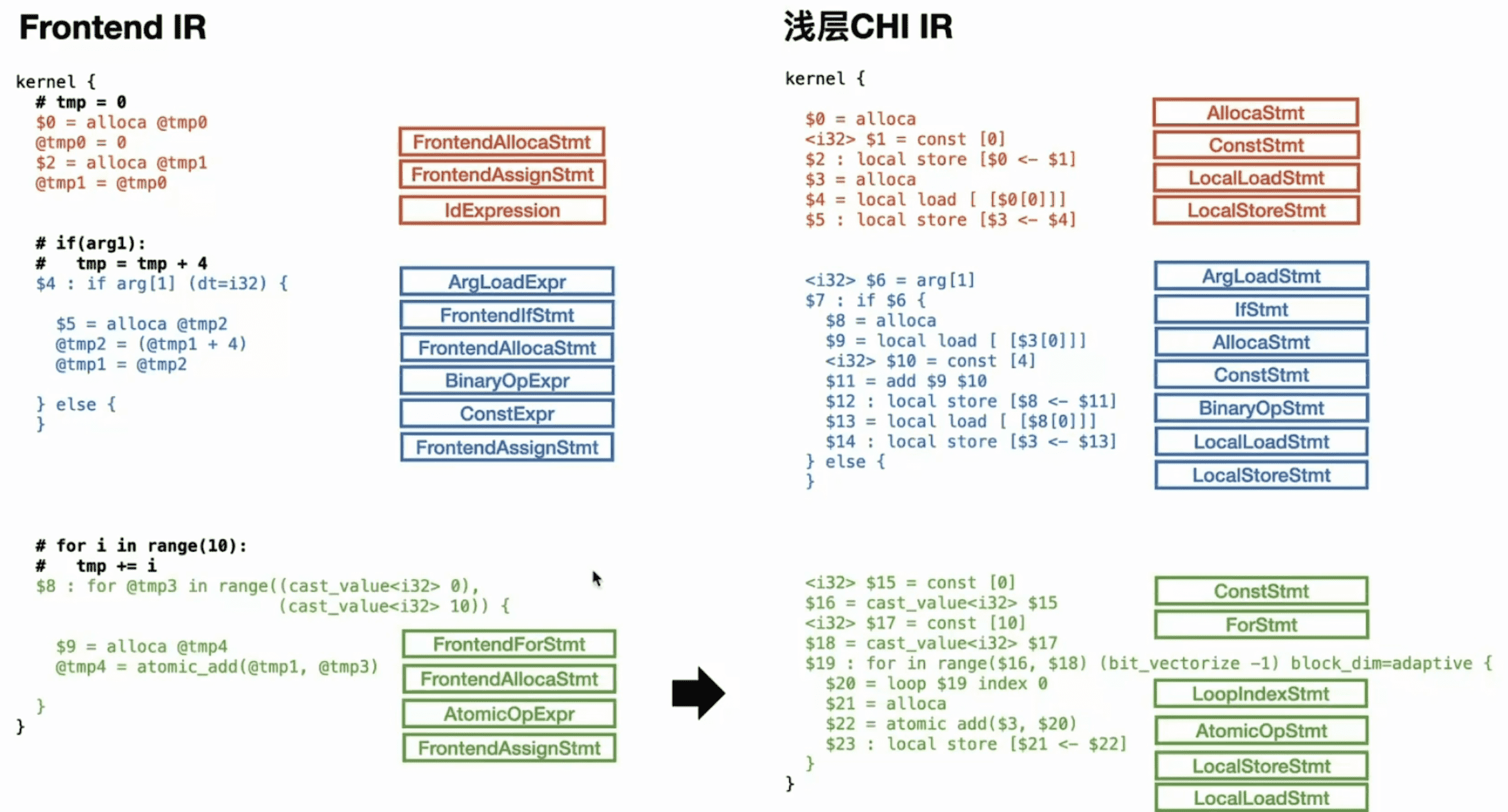
taichi/ir/statements.h
taichi/transforms/compile_to_offloads.cpp
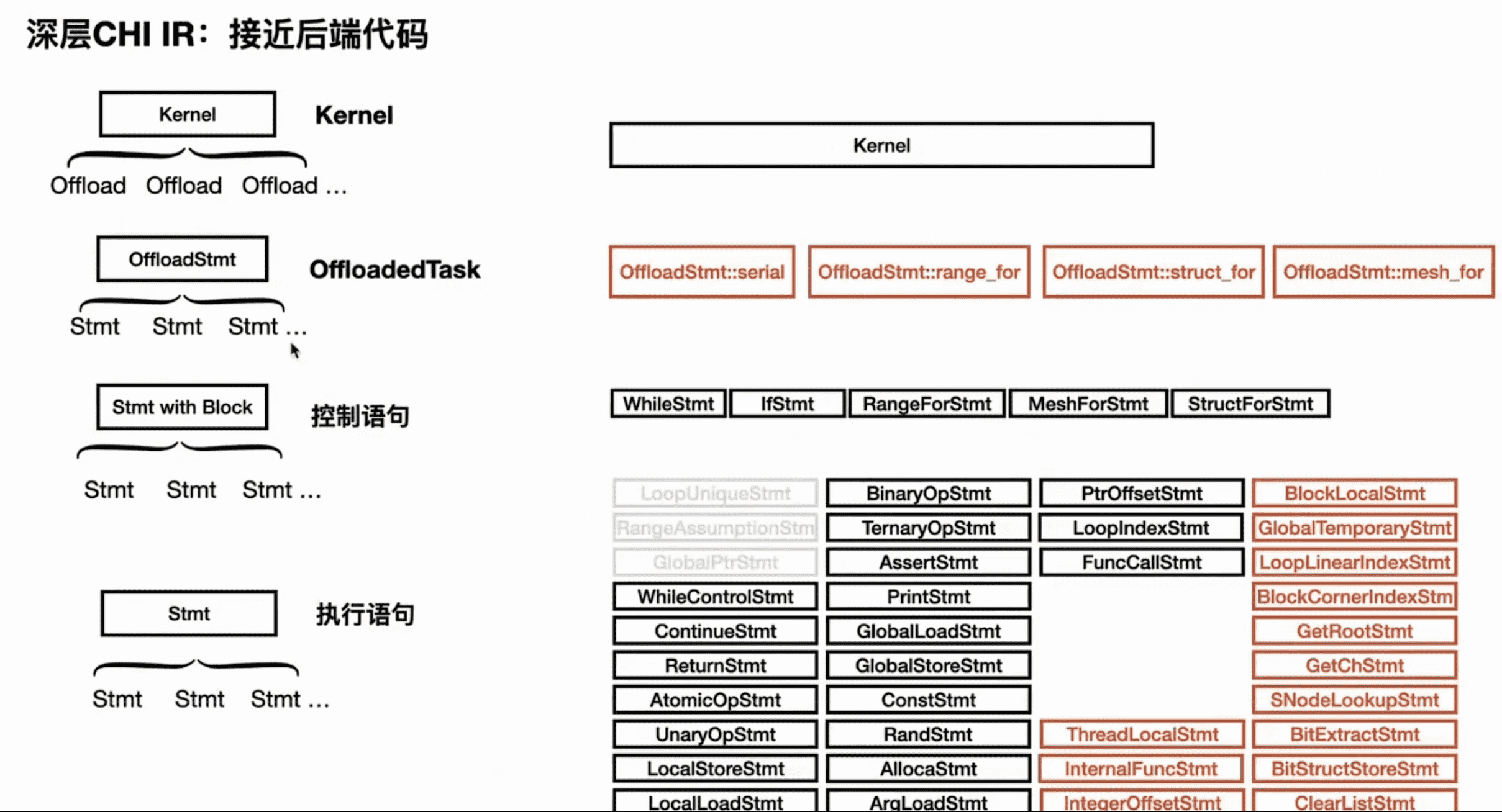
上图提到的 offload 是 CHI IR 浅层和深层的分界线。
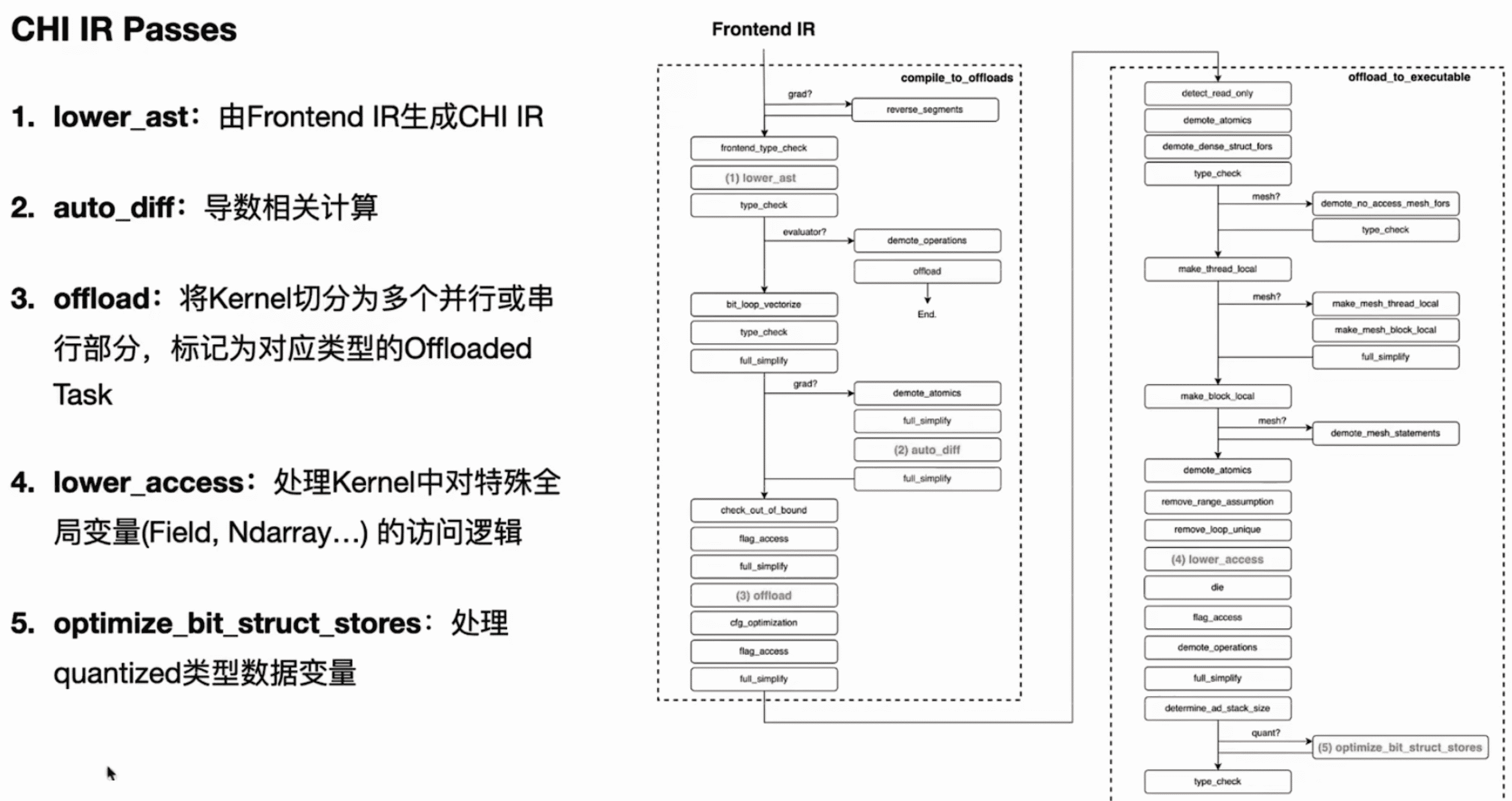
浅层 CHI IR -> 深层 CHI IR
taichi/transforms/offload.cpp
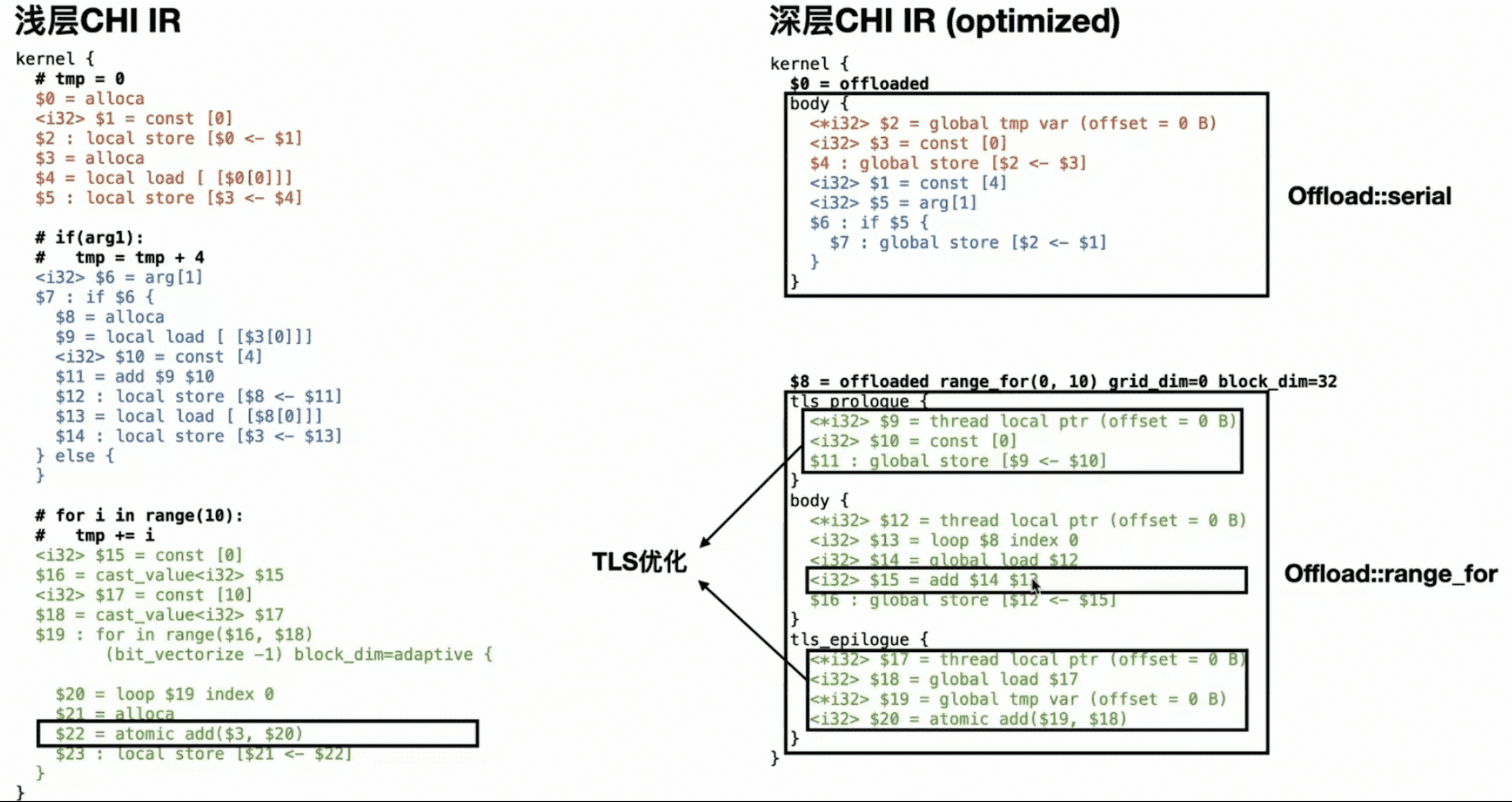
offload 主要是对 kernel 做了进一步的划分。以上图为例,图中红色蓝色需要相互依赖,是串行结构,被 offload 成 serial。绿色部分是循环结构,的通常情况下是可以展开的,被 offload 成 serial range_for,表示是可以进行并行的。
offload 之后,把 IR 结构做了一些调整,kernel 层级下面不再是 stmt,而是 offload,offload 下面才是 stmt:
taichi/ir/statements.h
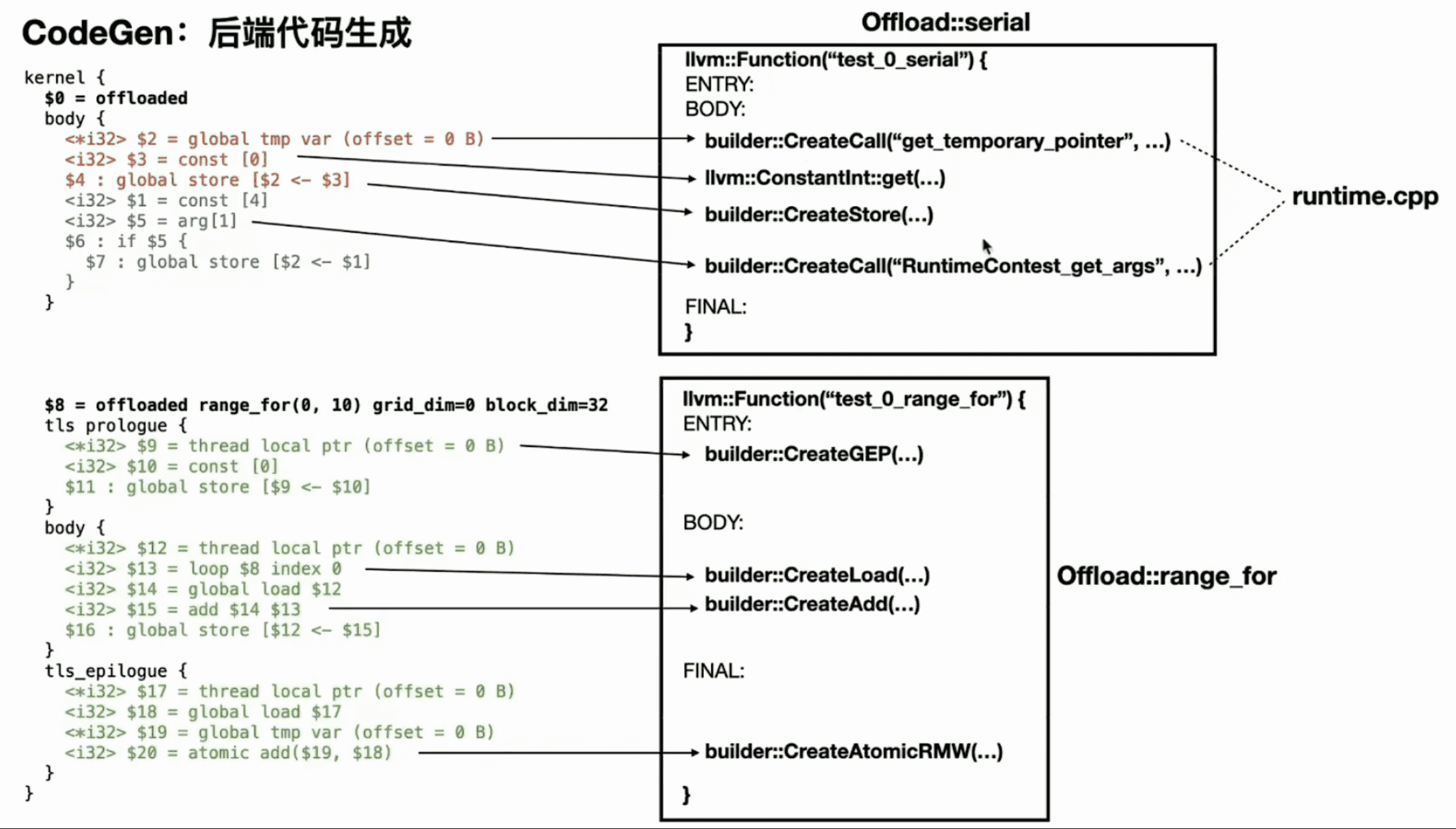
CHI IR -> CodeGen
在进行 codegen 时,CHI IR 会被翻译成功能对等的 LLVM IR Builder API,从而完成代码生成:
taichi/codegen/llvm/codegen_lvm.h
Field Compilation
ti.field 的编译和 ti.kernel 编译的过程类似,每个阶段可以大概对应起来:

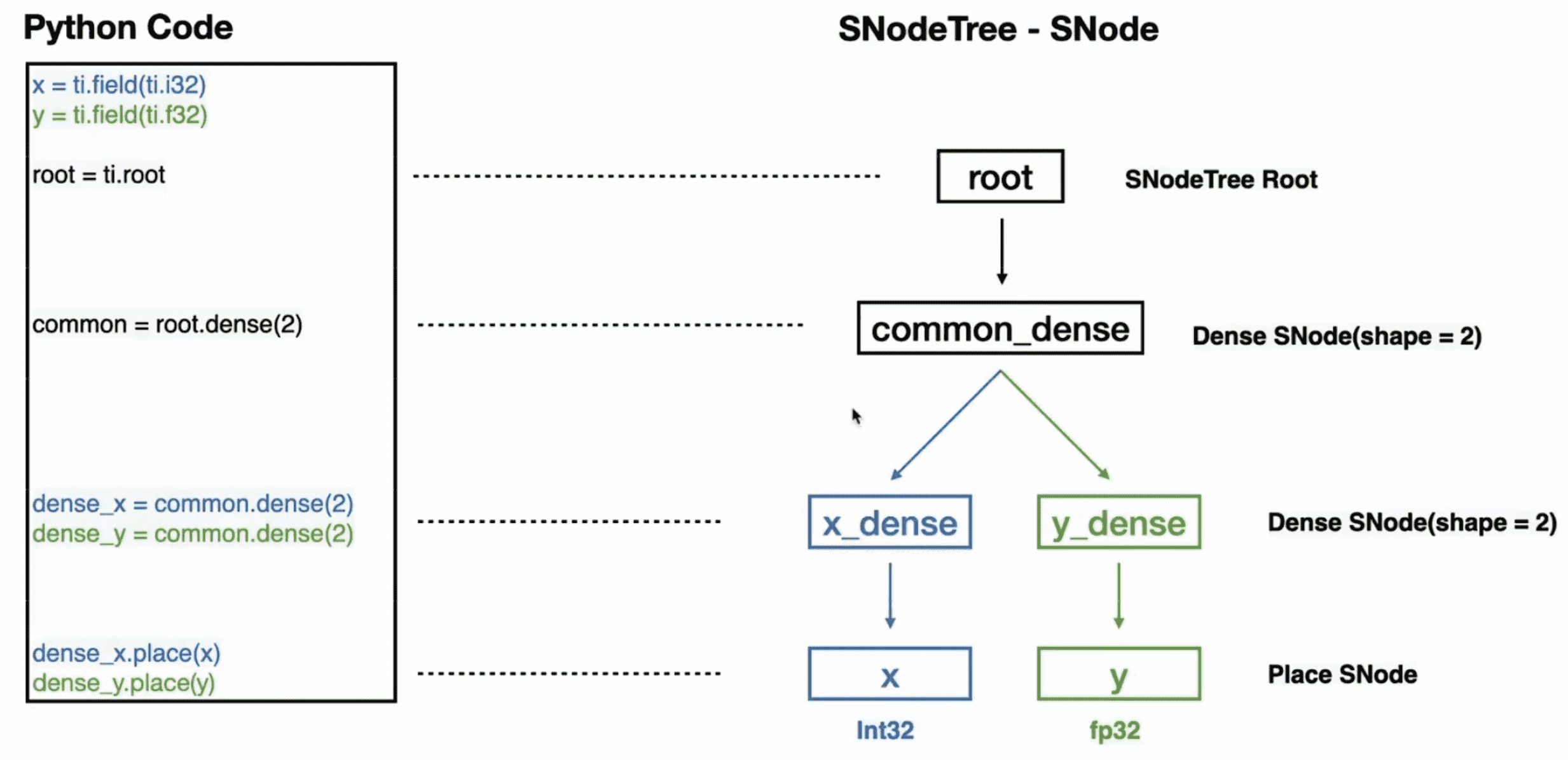
这里插入介绍下 SNode。SNode 是 Taichi 提供的通用的数据容器,可以方便地构造或稠密或稀疏的多维 field,并形成清晰的层级。注意区分三个概念:SNode container、SNode cell 和 SNode component。
- 一个 SNode container 可以包含多个 SNode cell。cell 的数量推荐设为 2 的幂次。举个例子,
S = ti.root.dense(ti.i, 128)创建了一个 SNodeS,每个Scontainer 包含 128 个Scell。 - 一个 SNode cell 可以包含多个 SNode components。举个例子,
P = S.dense(ti.i, 4); Q = S.dense(ti.i, 4)插入两个 components(一个Pcontainer 和一个Qcontainer)到每个Scell。 - 请注意,每个 SNode component 都是较低级别 SNode 的 SNode container。
Taichi 中的分层数据结构,无论是稠密的还是稀疏的,本质上都是一棵具有交错的 container 和 cell 级别的树。更加详细的内容可以参考官方文档。
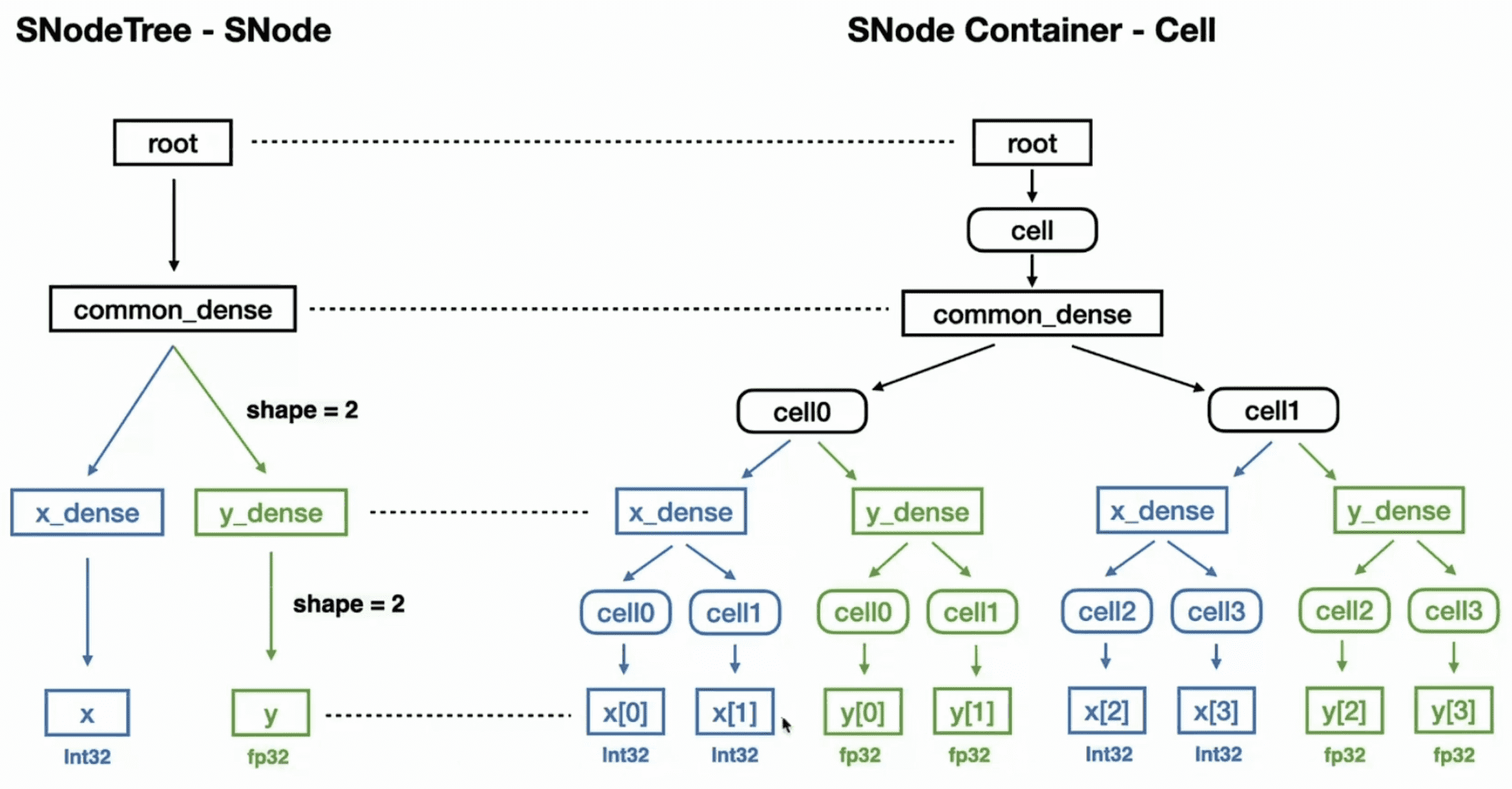
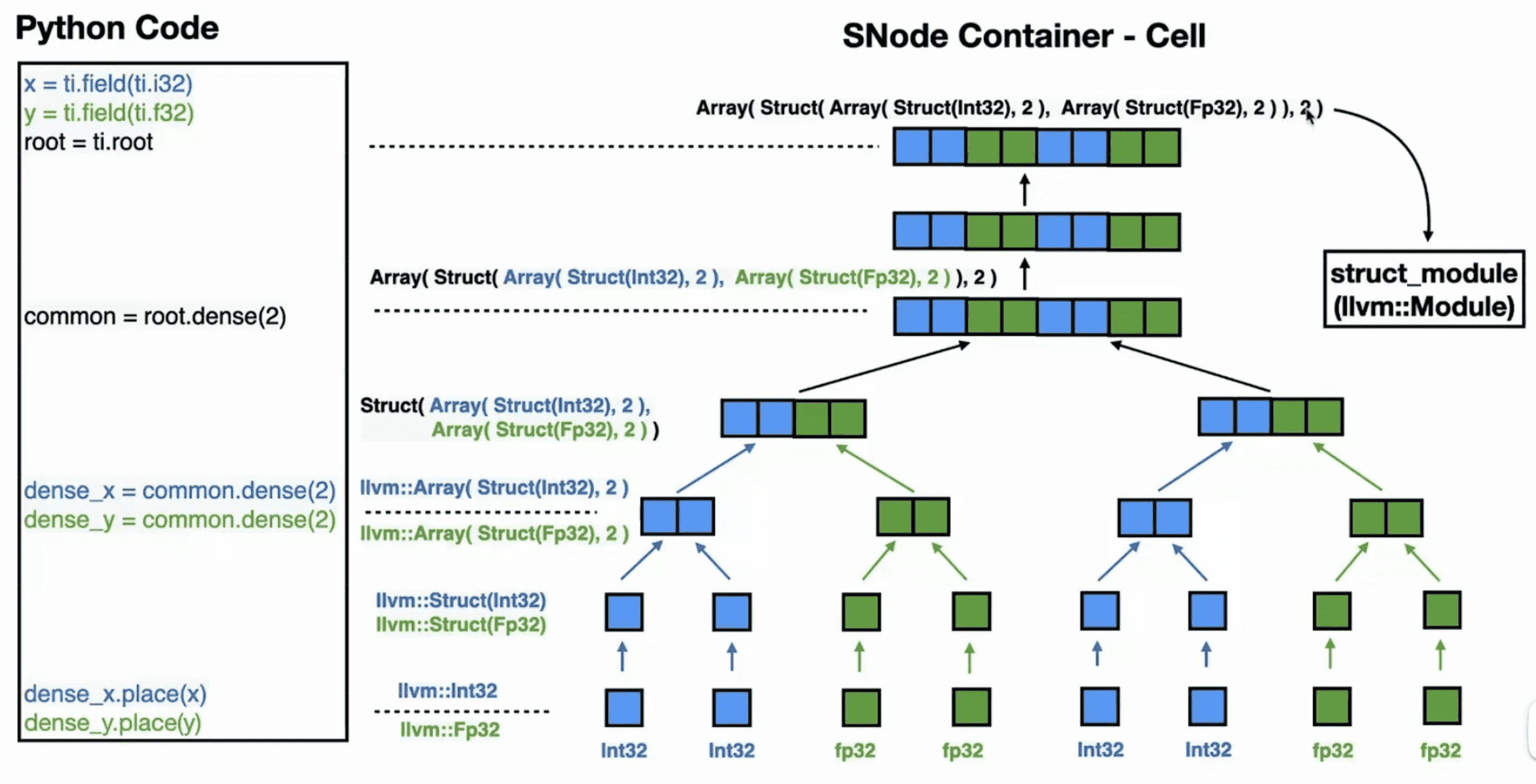
这样 Python 中的 ti.field 就转换成了 C++ 中浅层的数据结构。
Access Fields in Kernel
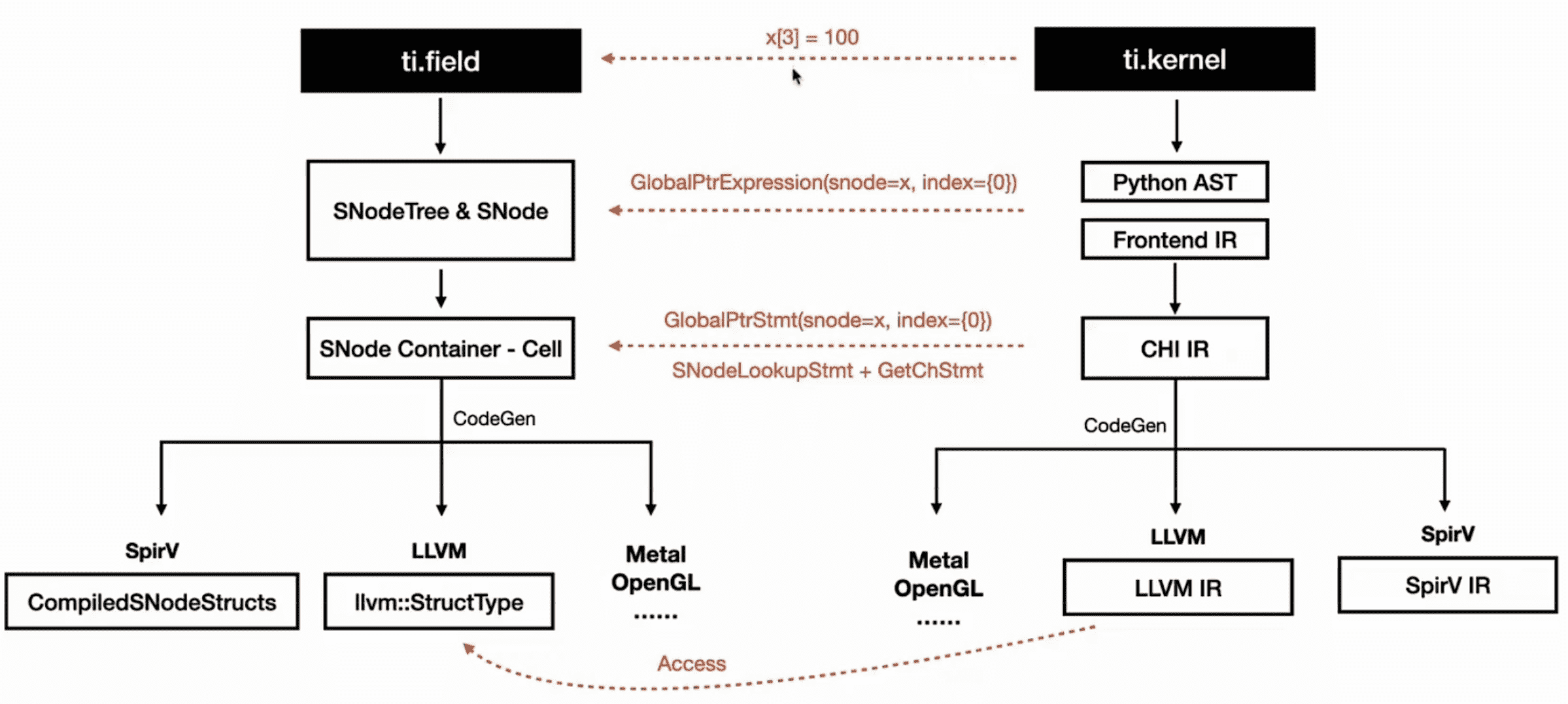
上图将前面提到的两个编译步骤对应了起来。接下来以一段代码为例,看一下示例中的 x[3] = 100 是怎么转换下去的:
1 | x = ti.field(ti.i32) |
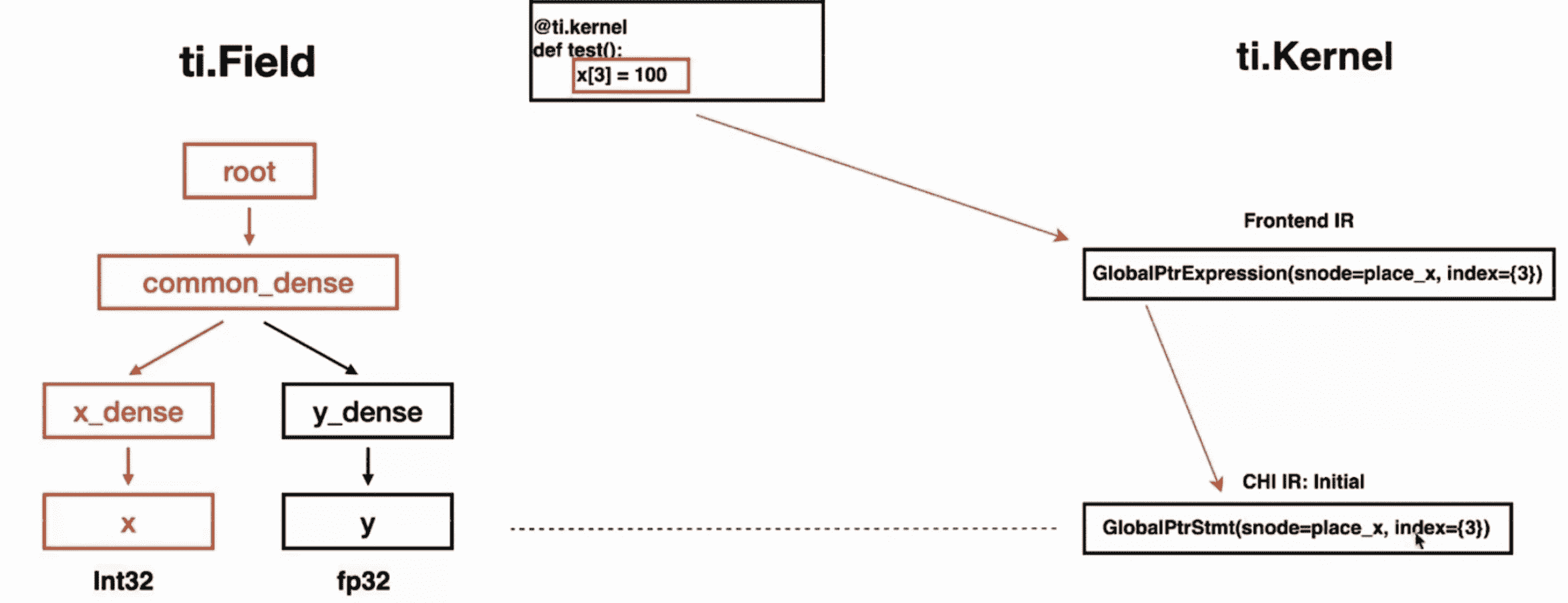
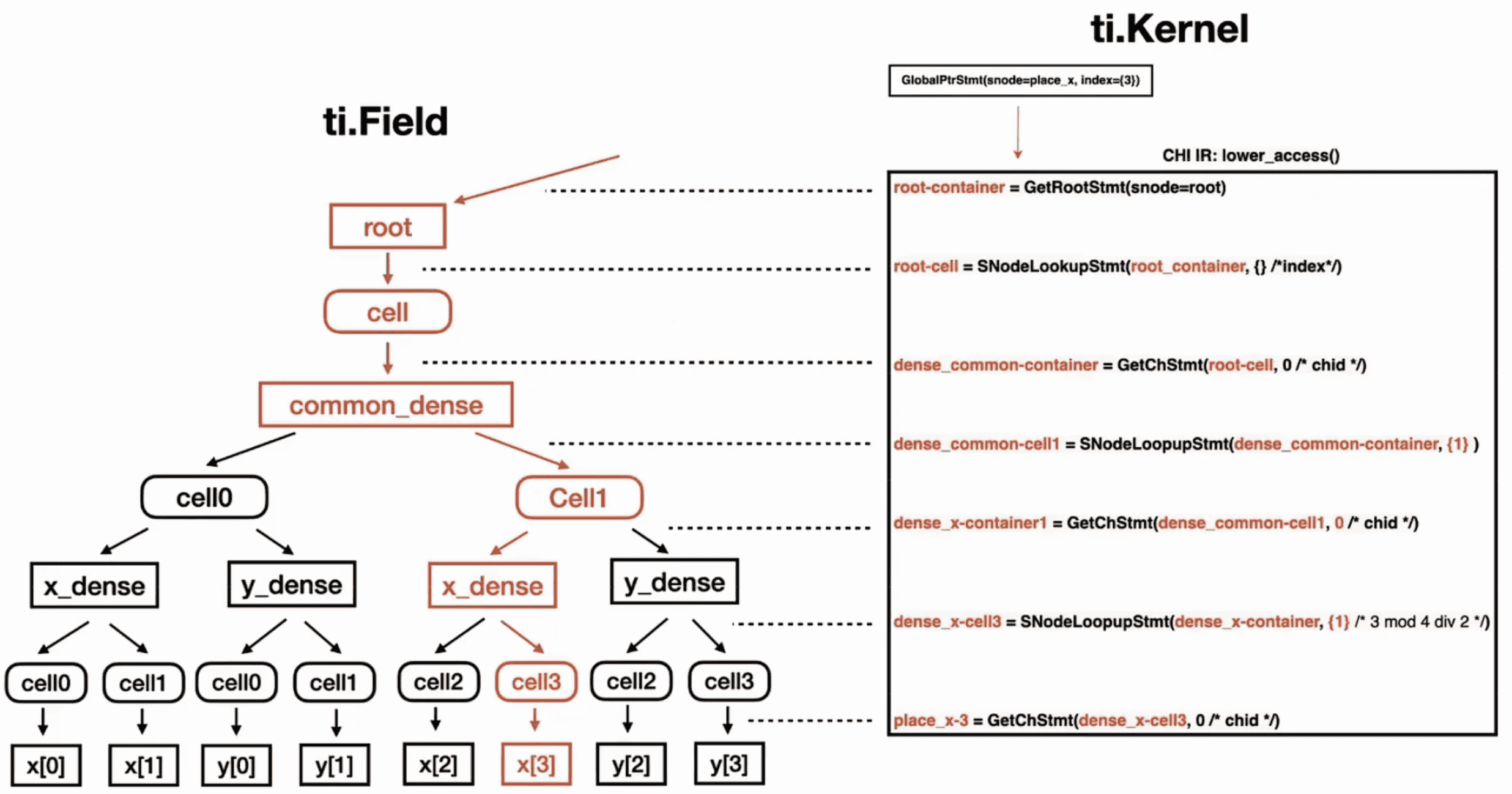

Runtime Execution
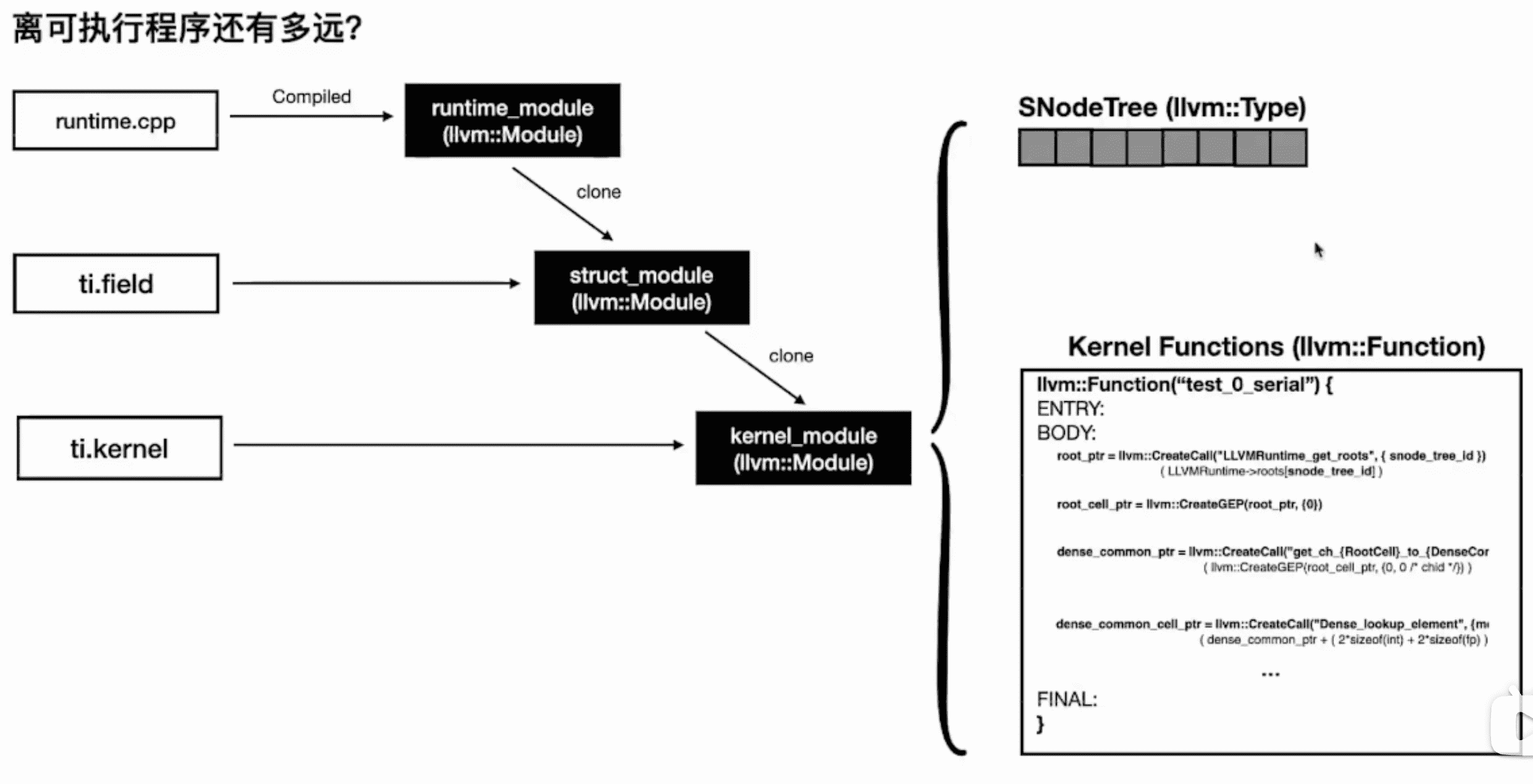
运行时的内存控制
SNodeTreeBufferManager 是运行时内存管理的数据结构。
局部变量返回后会被销毁,需要在申请一块 result_buffer 用于存放:

kernel 运行时预分配内存,其中 LLVM Runtime 那部分用于 track 内存的使用地址范围:

SNodeTreeBufferManager 向 LLVM Runtime 申请内存:

SNodeTreeBufferManager 管理申请到的内存,记录 page 中剩余的内存大小:

SNodeTreeBufferManager 可以复用申请到的内存:
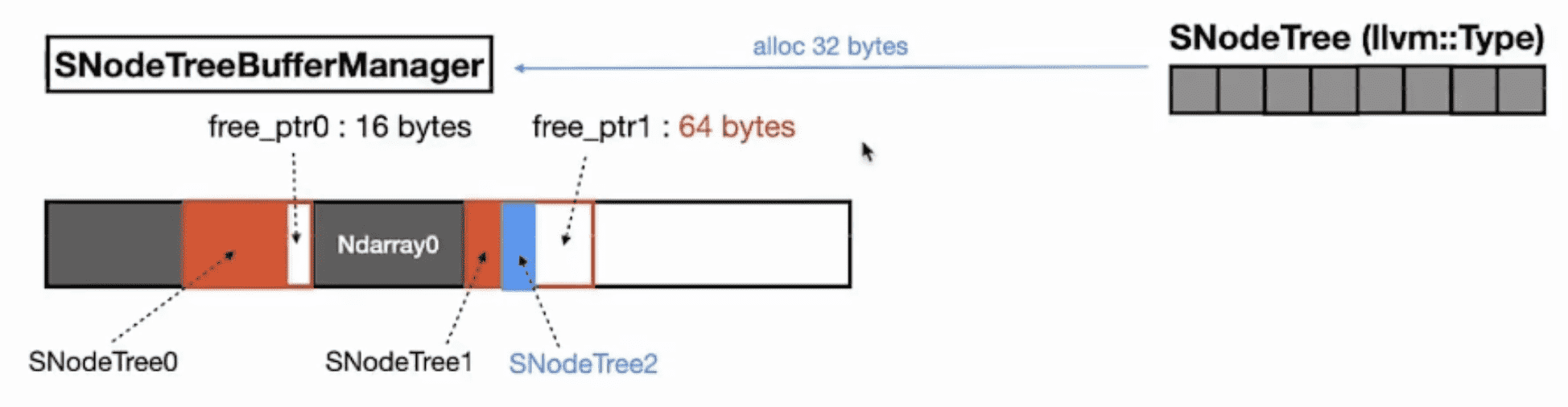
SNodeTreeBufferManager 也会做垃圾回收:

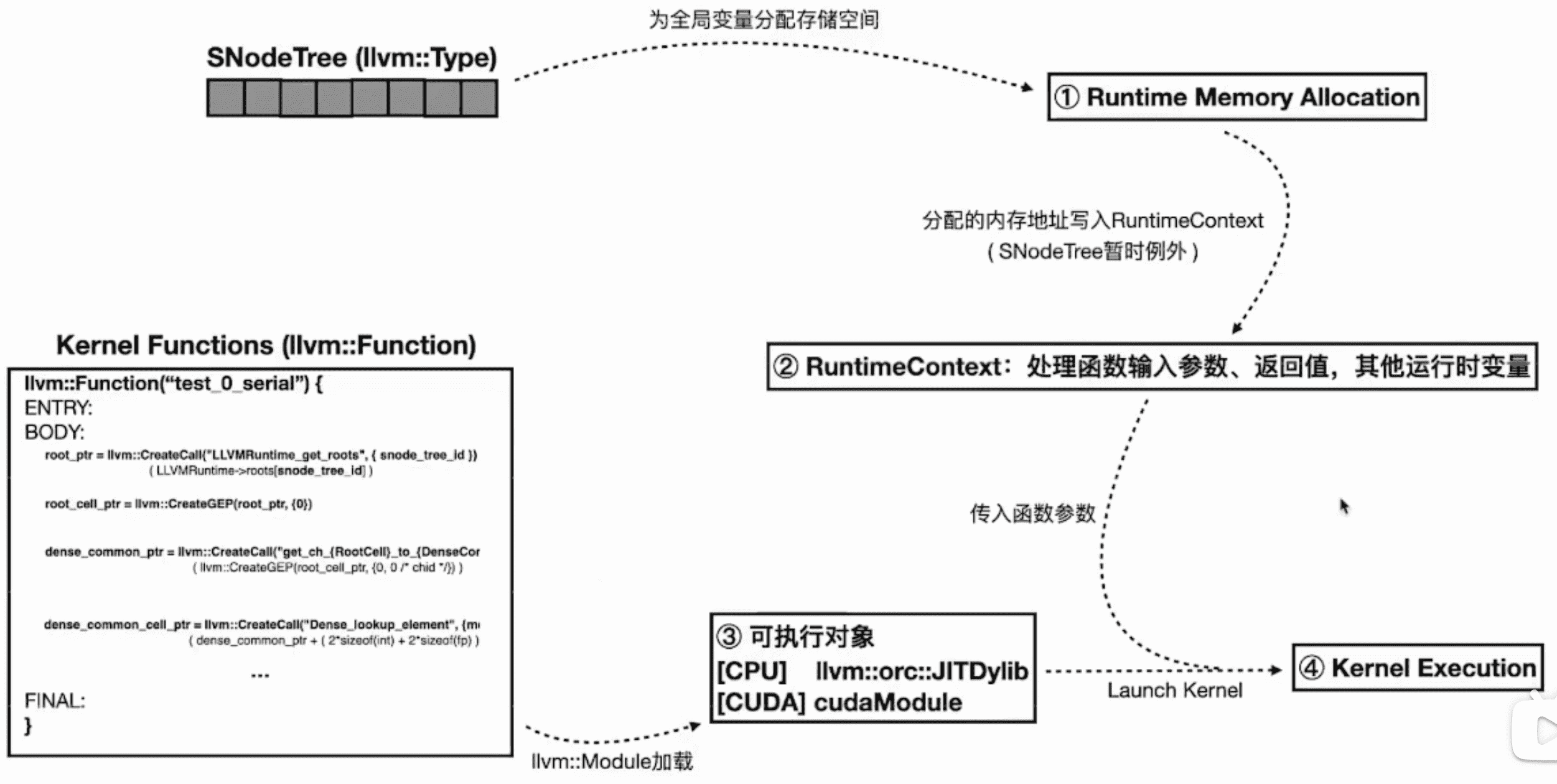
组建 RuntimeContext
会包一个 LLVM Runtime:

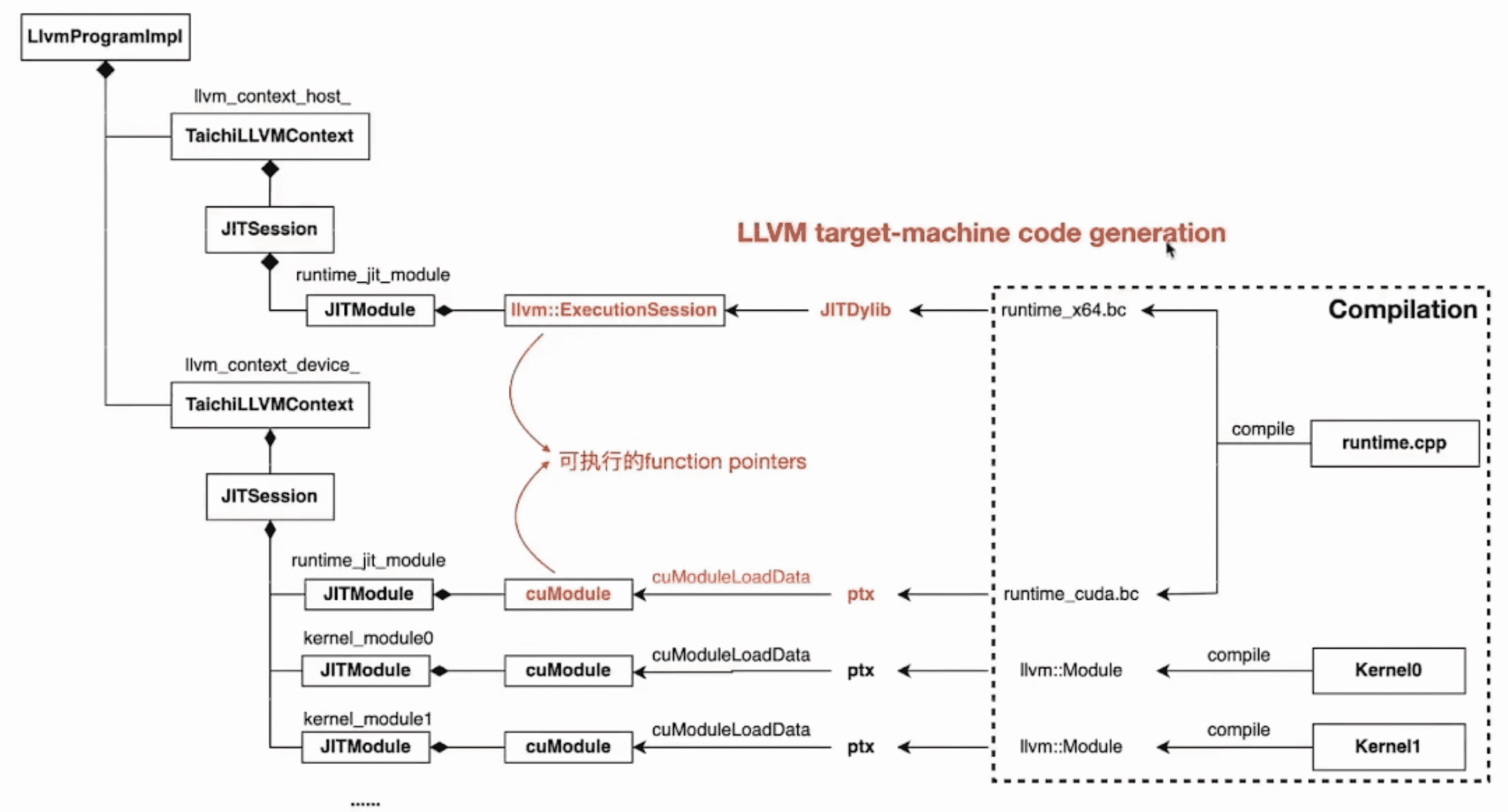
llvm::Module 加载
如果是 CPU,runtime 会被编译成 LLVM JITDylib,如果是 CUDA,则会被编译成 PTX,然后通过 cuModuleLoadData 加载到 CUDA runtime 中:
kernel 执行
kernel 执行的入口对应到 Python 就是在这里(标红色的):


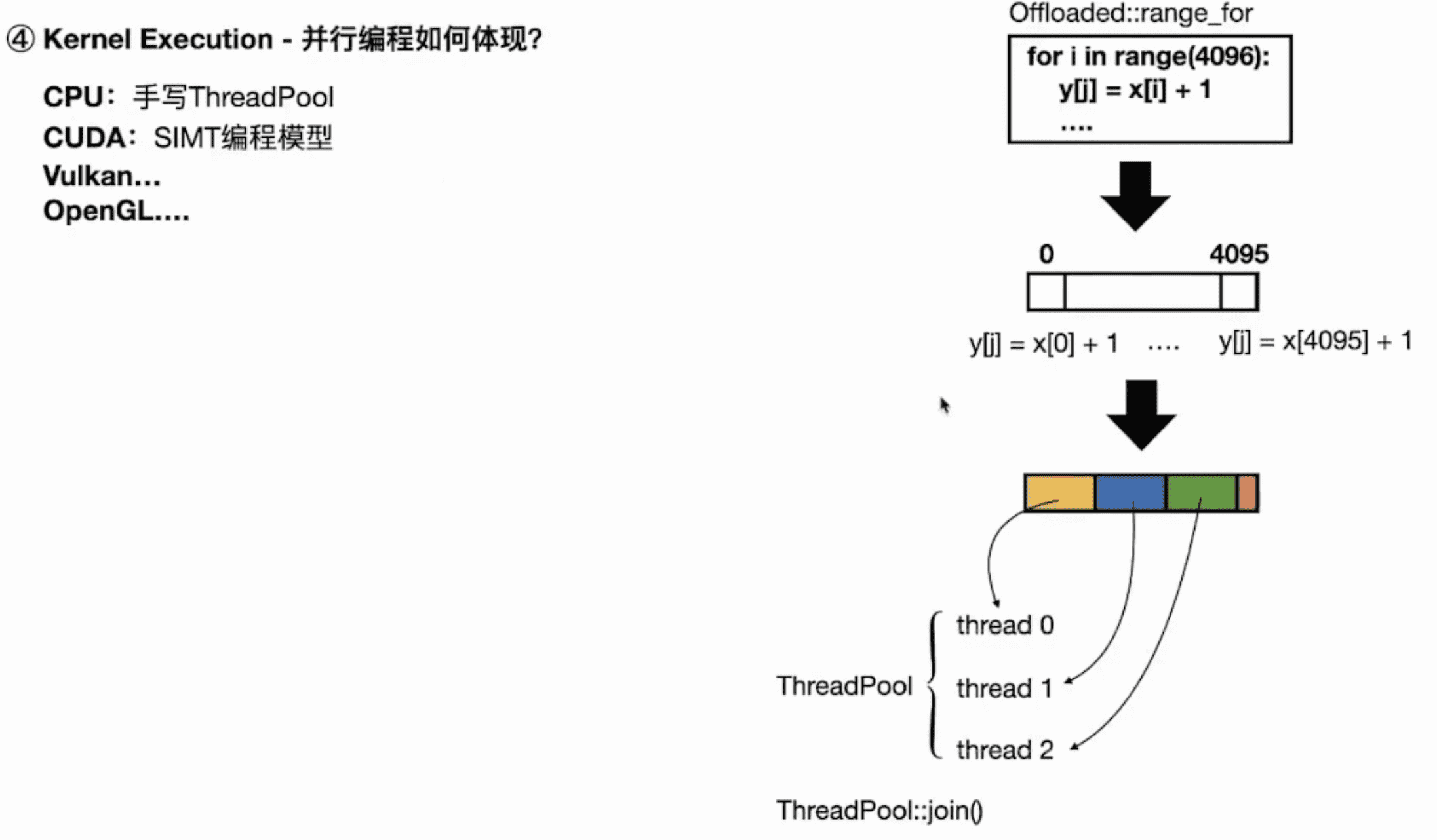
并行编程如何体现
不同后端实现的方式不一样:
小结
课程笔记:核函数执行流程 | Taichi