李沐:基于系统和算法的协同设计的大规模分布式机器学习 | 系统开发
李沐的基于系统和算法的协同设计的大规模分布式机器学习课程的笔记。
大规模机器学习问题
内容
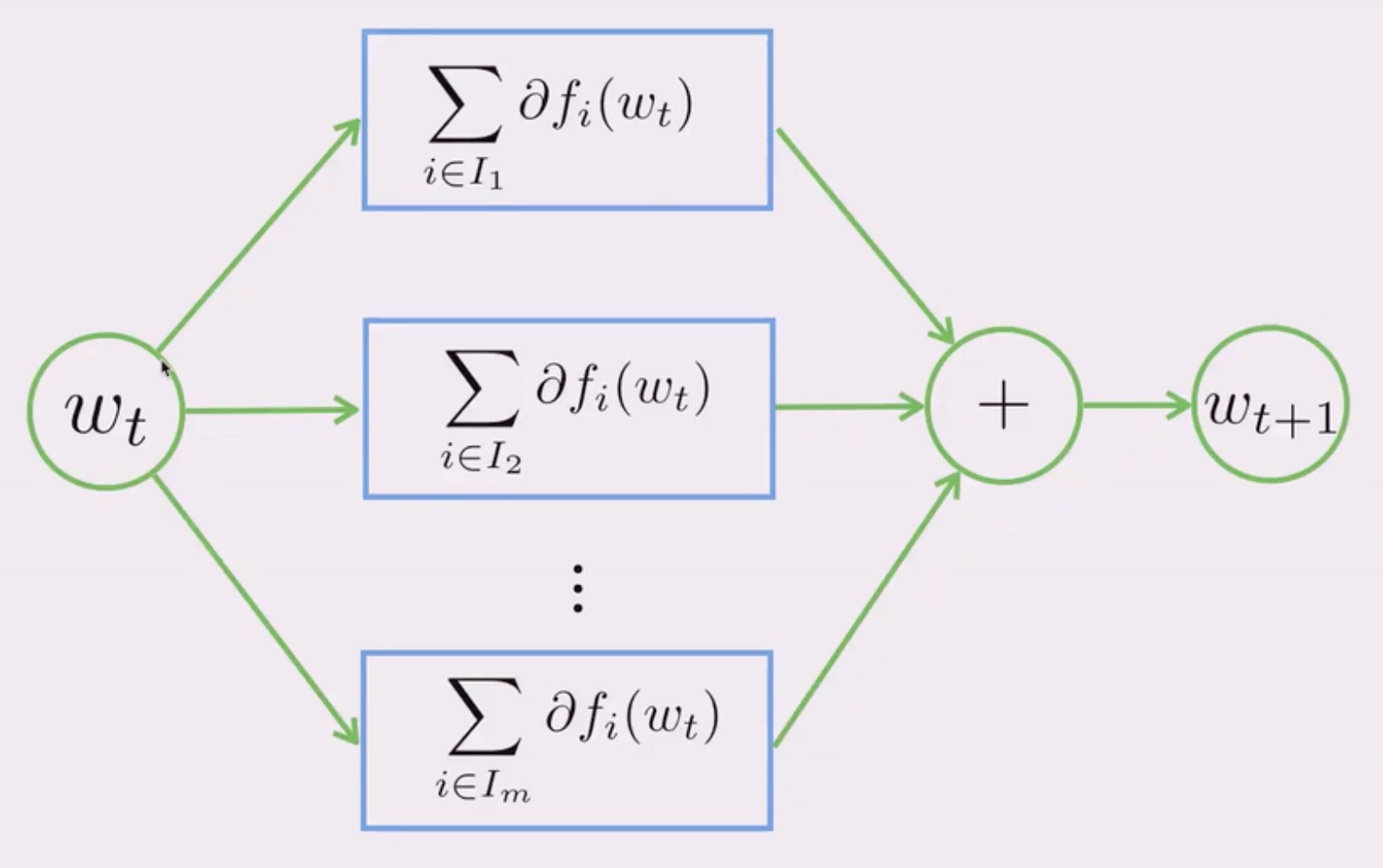
挑战
- 有限的通信带宽(远小于内存带宽)
- 巨大的同步开销
- 任务失败问题:任务跑得越久,被更优先级的任务抢占资源的概率就越大
需要解决的问题
- 分布式系统
- 处理大数据、复杂的模型
- 容灾
- 易用
- 大规模优化方法
- 高效的通信
- 保证好的收敛性
本文主要内容
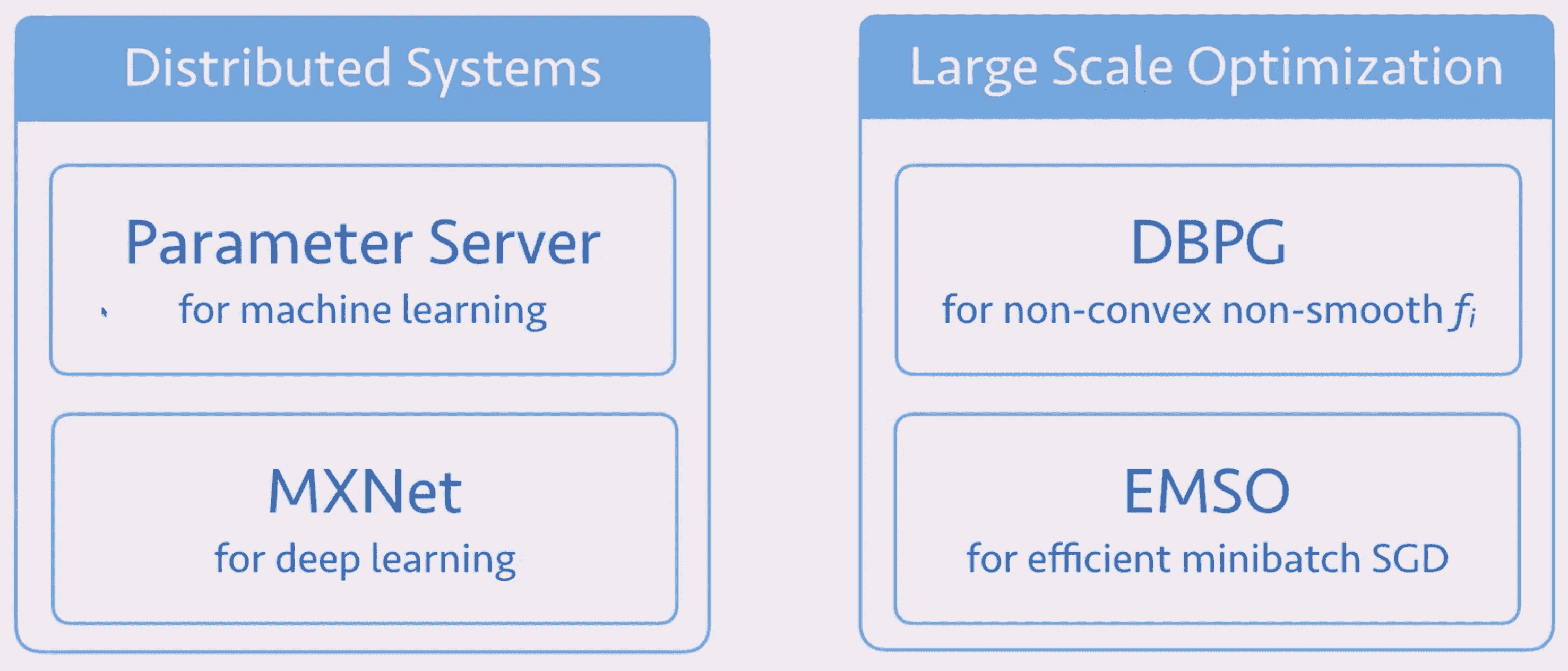
分布式系统
参数服务器架构
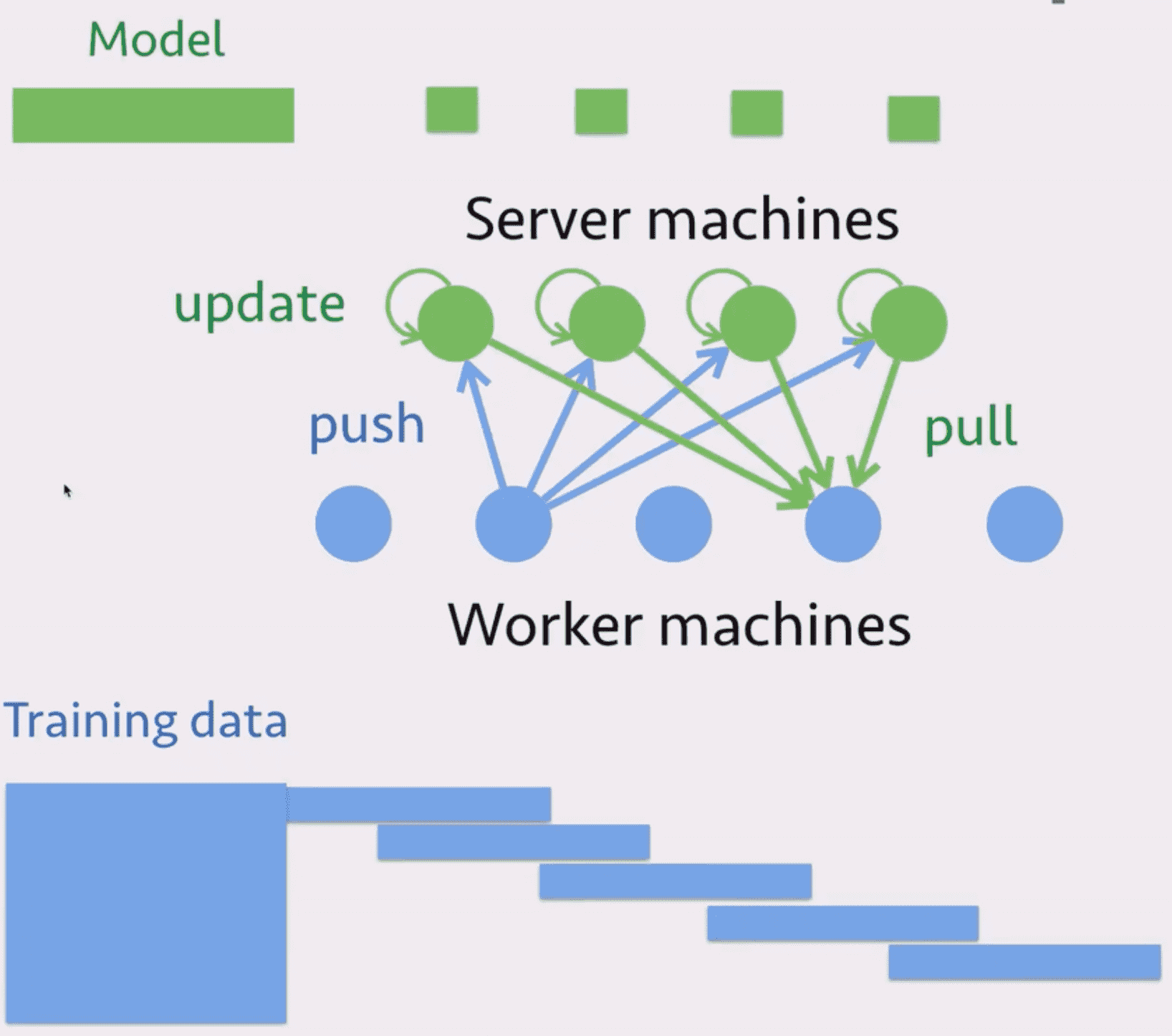
- 任务分割:将训练数据分成多部分,每个 worker 分配一部分。将模型也分割成多个部分,每个 server 分配一部分。
- 计算:worker 计算梯度发送给所有 server,server 更新模型,worker 获取到新的模型然后计算下一轮梯度。
一些 idea
灵活的一致性模型:迭代之间
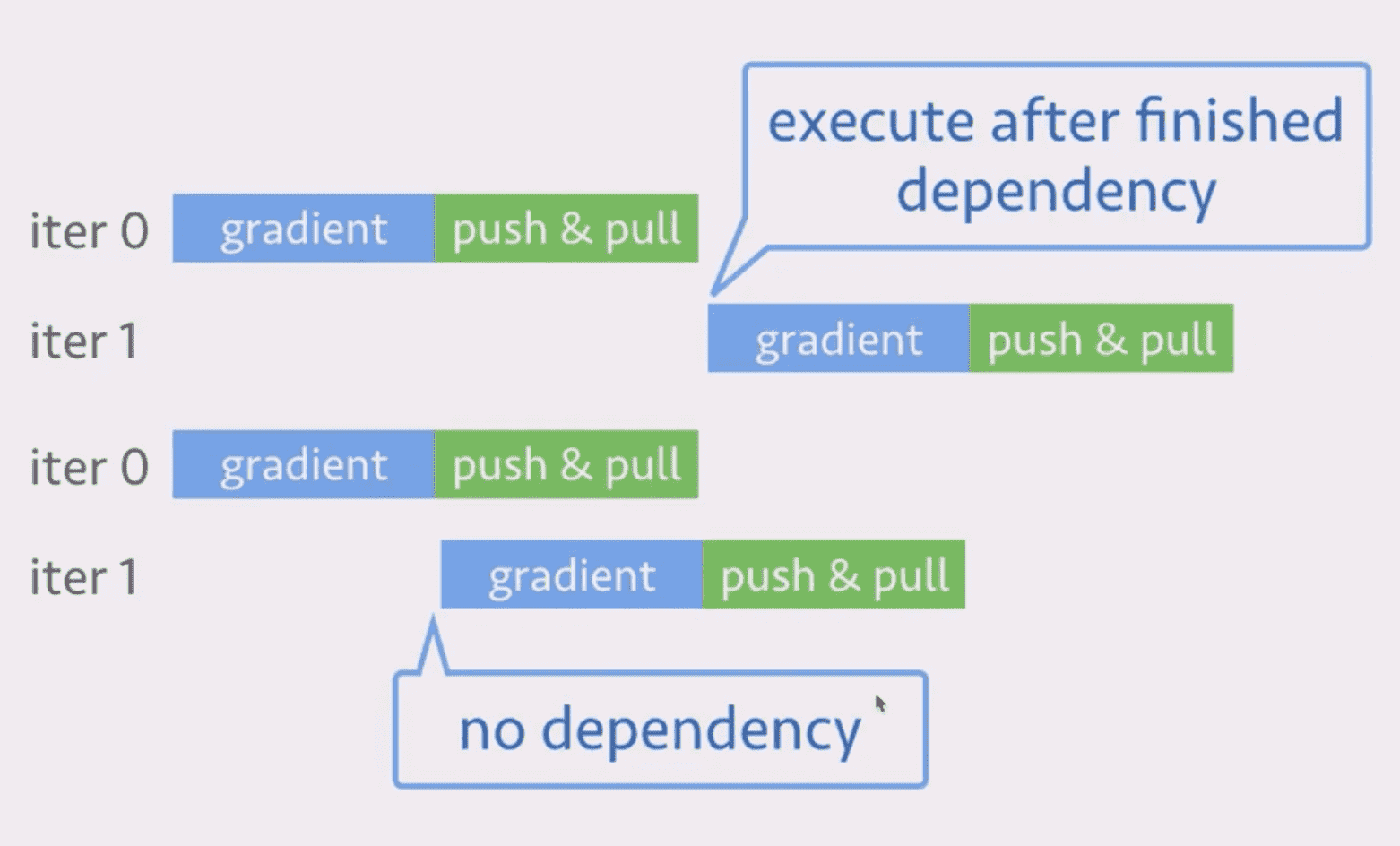
蓝色的是计算,绿色的是通信。如果不保证 push 发生在 pull 之前(这一次梯度计算可能是基于上次的模型),可以一定程度上提高运算效率。
下图中每个节点都代表一个计算过程,没有依赖之间的计算过程是可以并行进行的: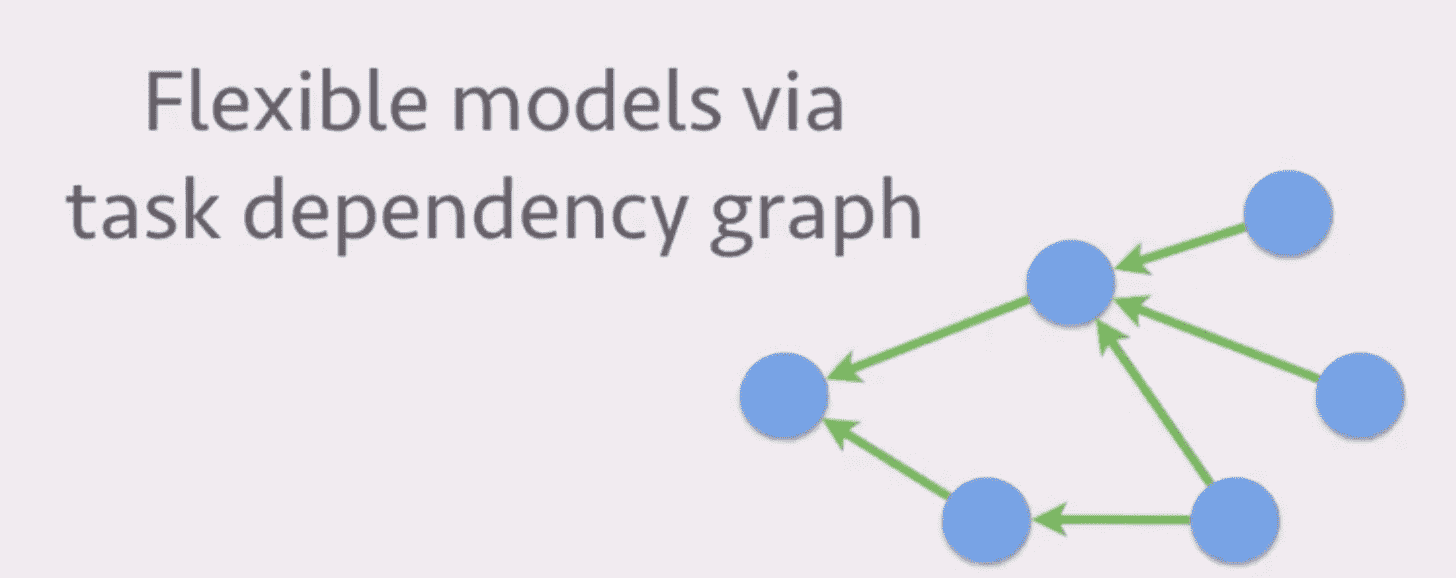
有以下几种方案: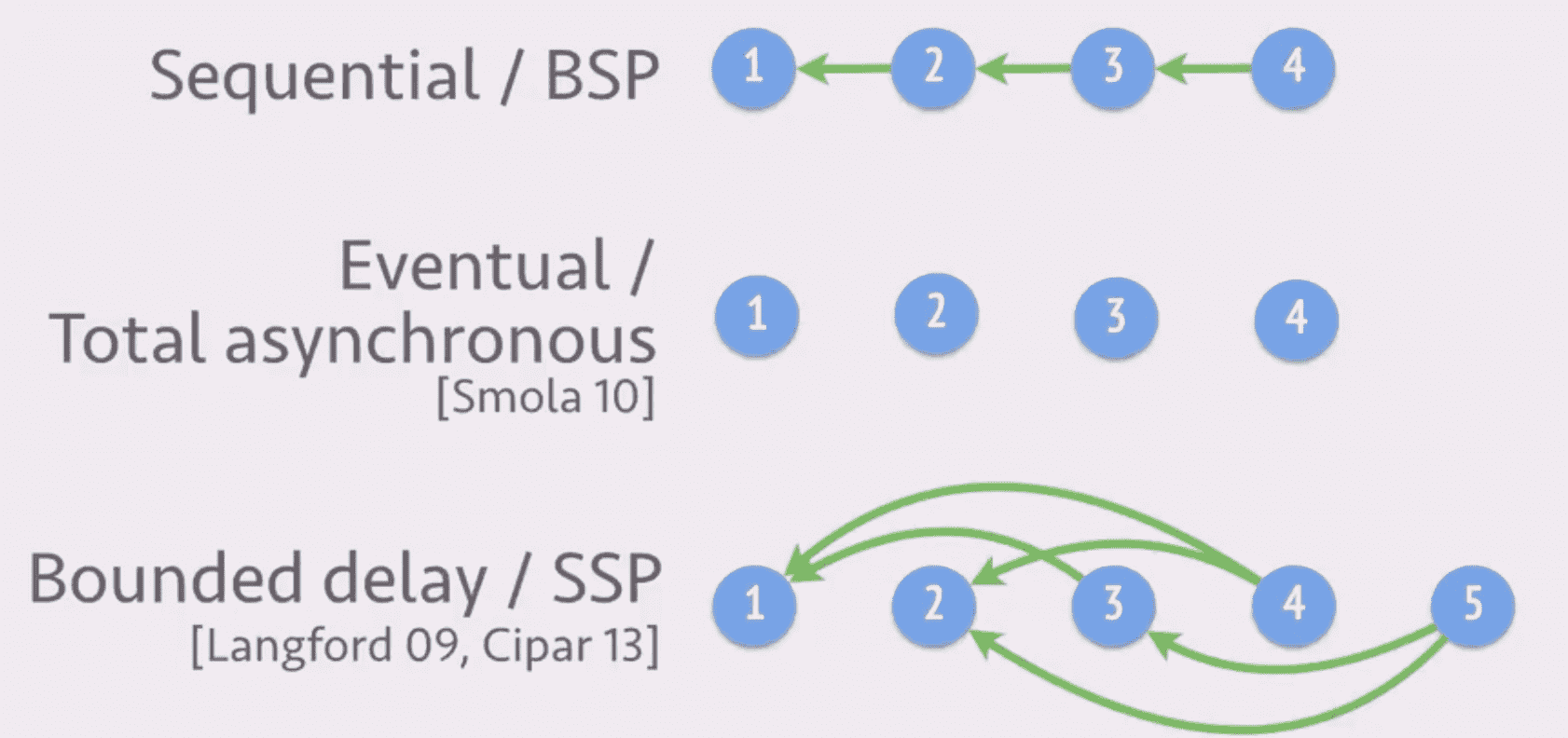
高效的通信:迭代内部
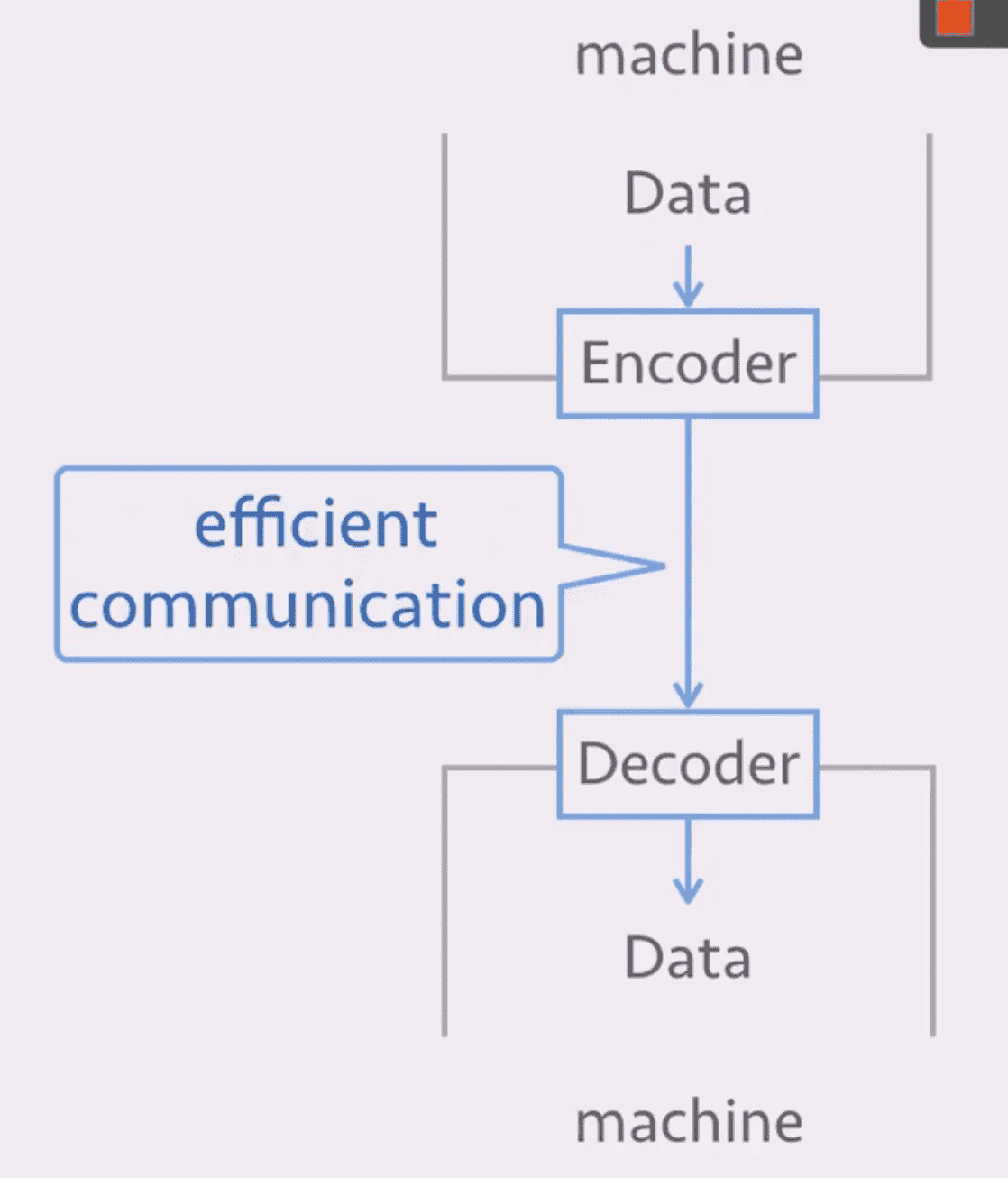
- 用户定义的编码/解码器以实现更高的通信效率
- 无损压缩:LZ、LZR 等
- 有损压缩:随机丢弃一部分值、梯度剪枝、使用定点数
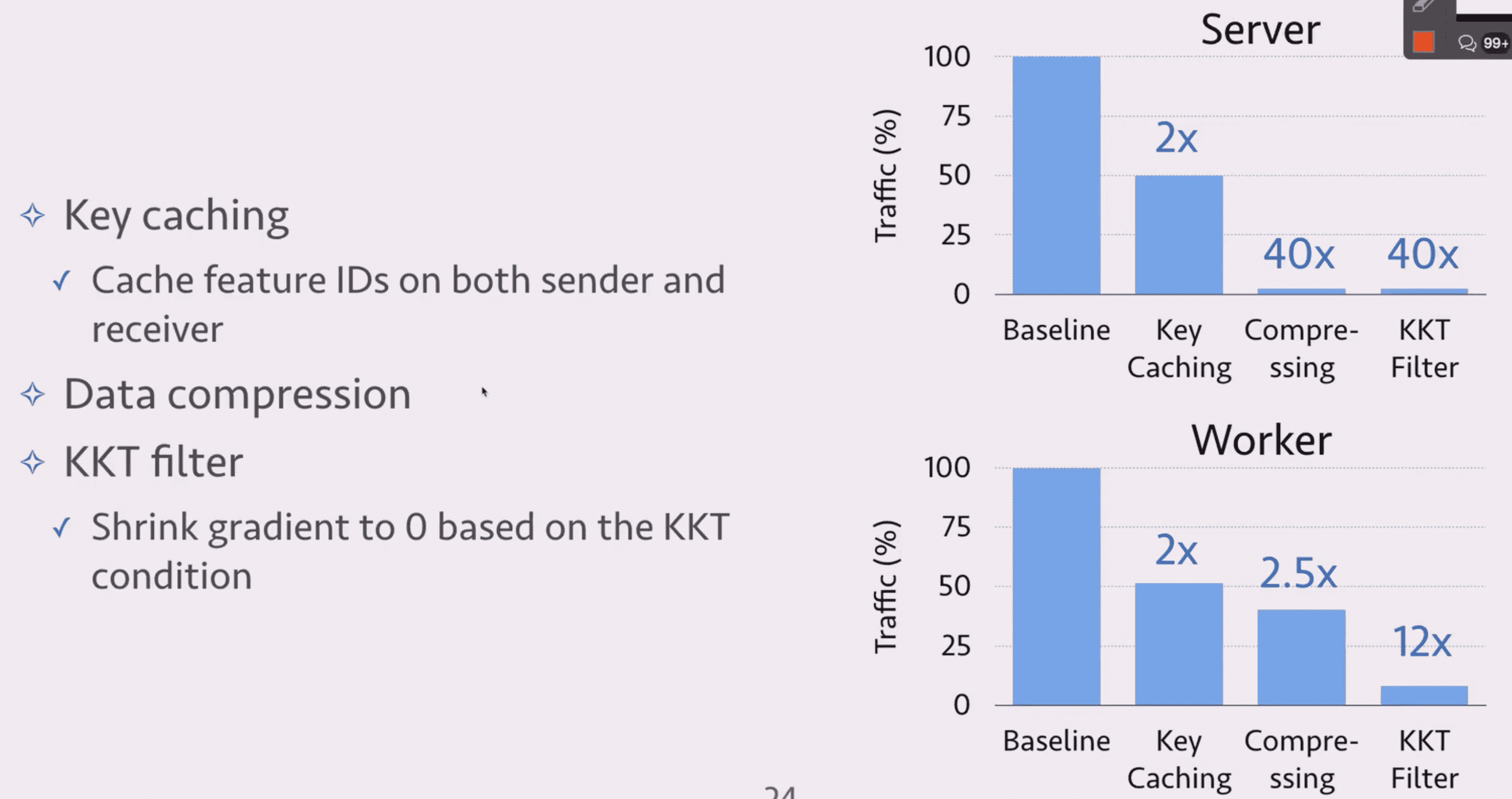
容灾
使用 chain replication 进行容灾,sever 0 的数据在 server 1 上备份一下: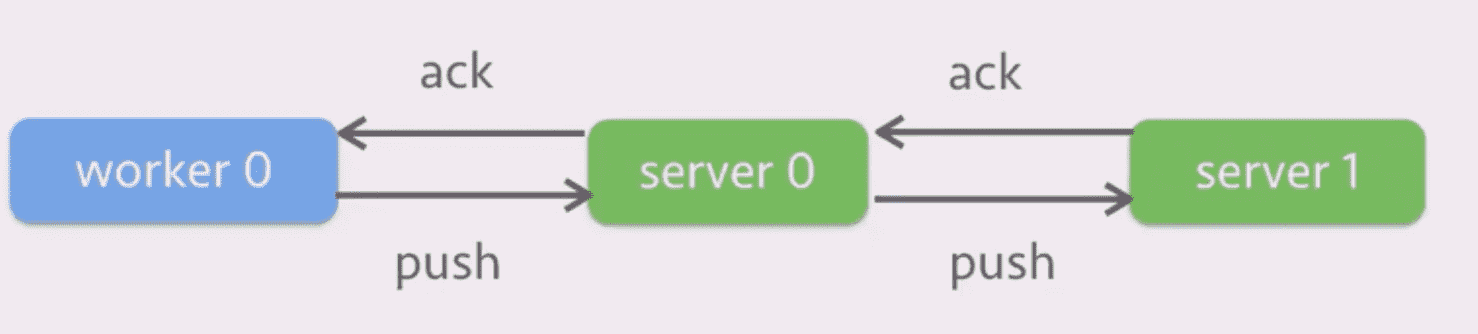
一个方法是合并多个 worker 的梯度后再传给 server 0: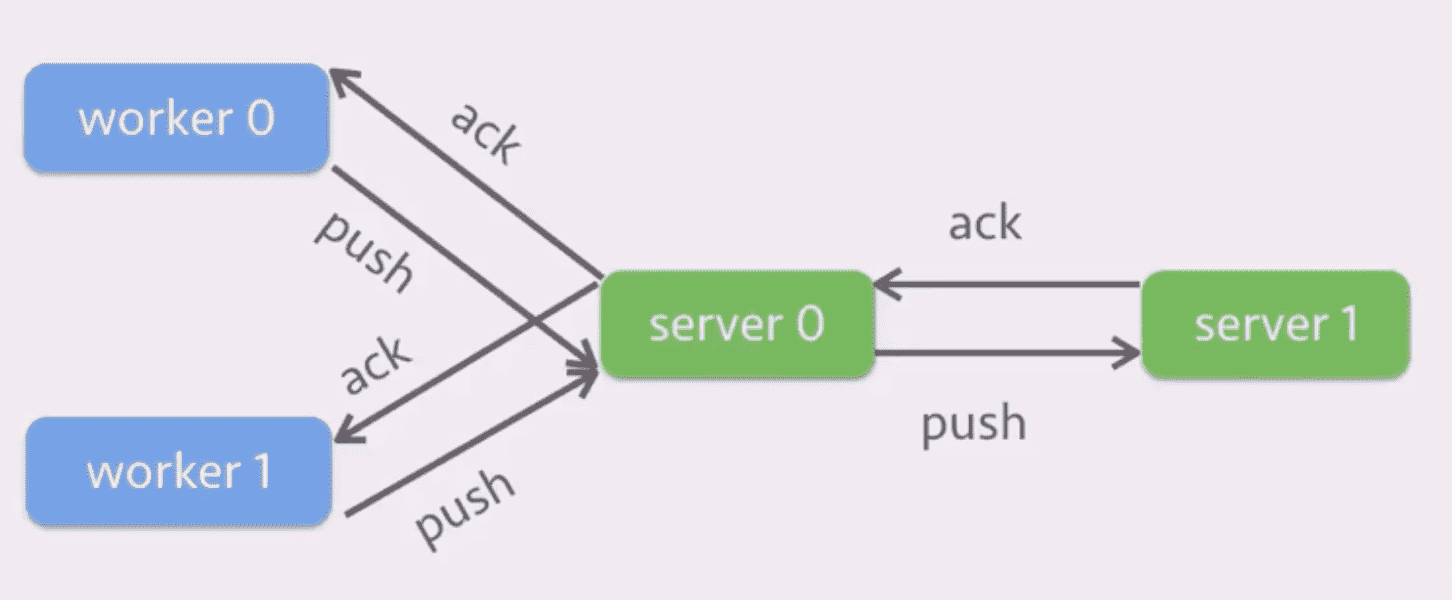
但是这样的缺陷在于 latency 会变低。
深度学习:Scale to Multiple GPU Machines
实验设置
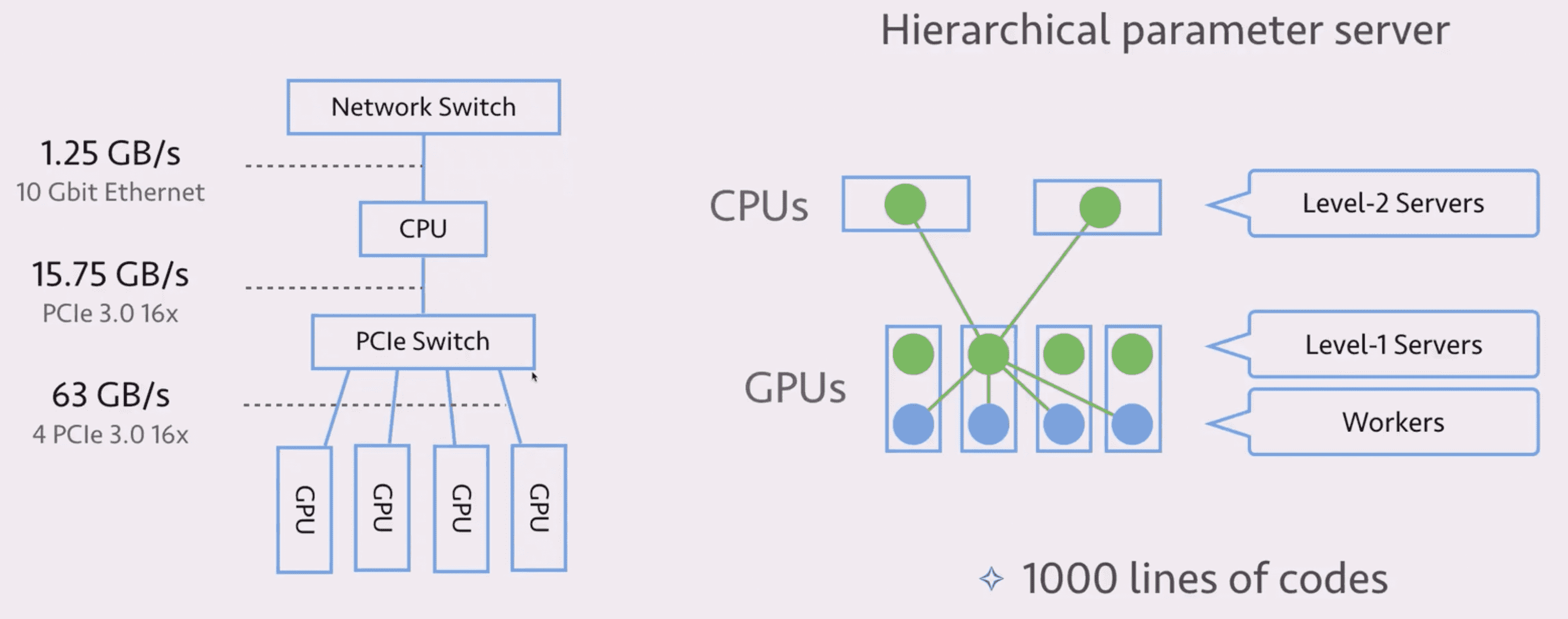

通信
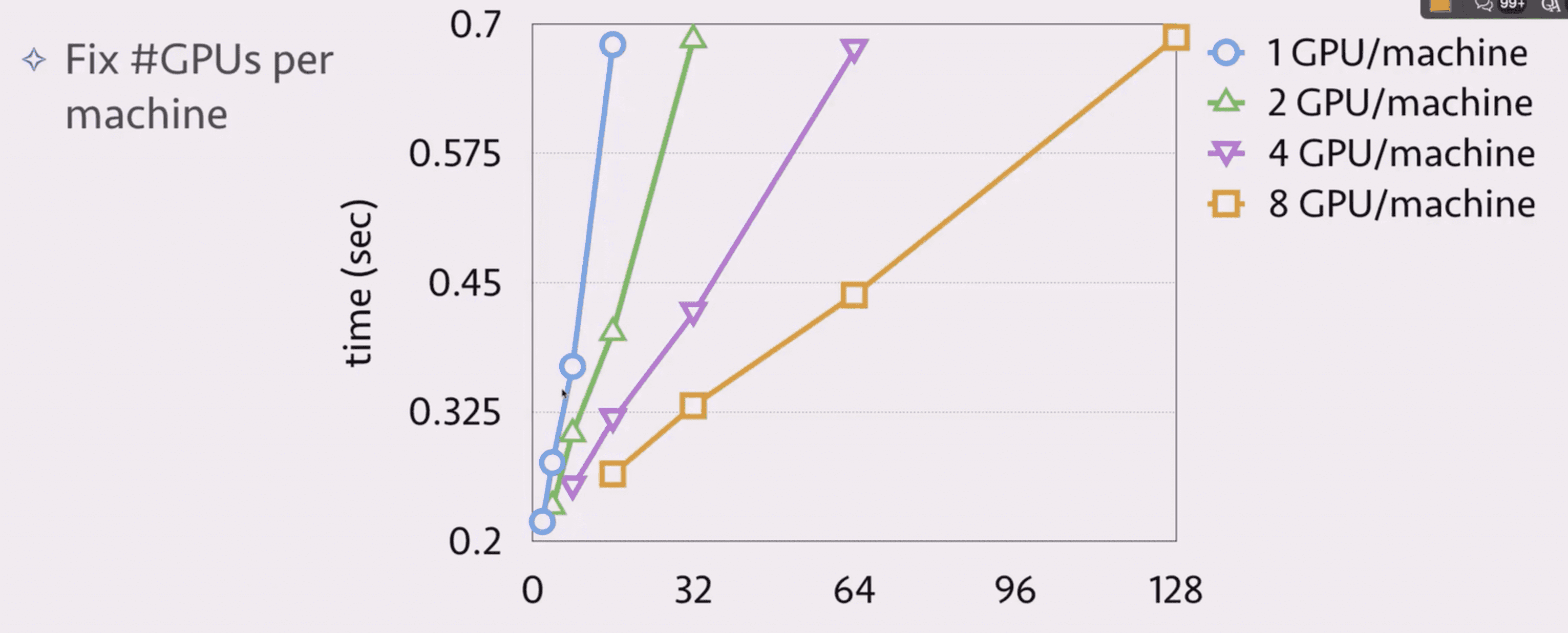
其中纵轴是每一个 mini-batch 的通信时间。
所以尽量利用一台机器上 GPU 之间的通信优势。
计算
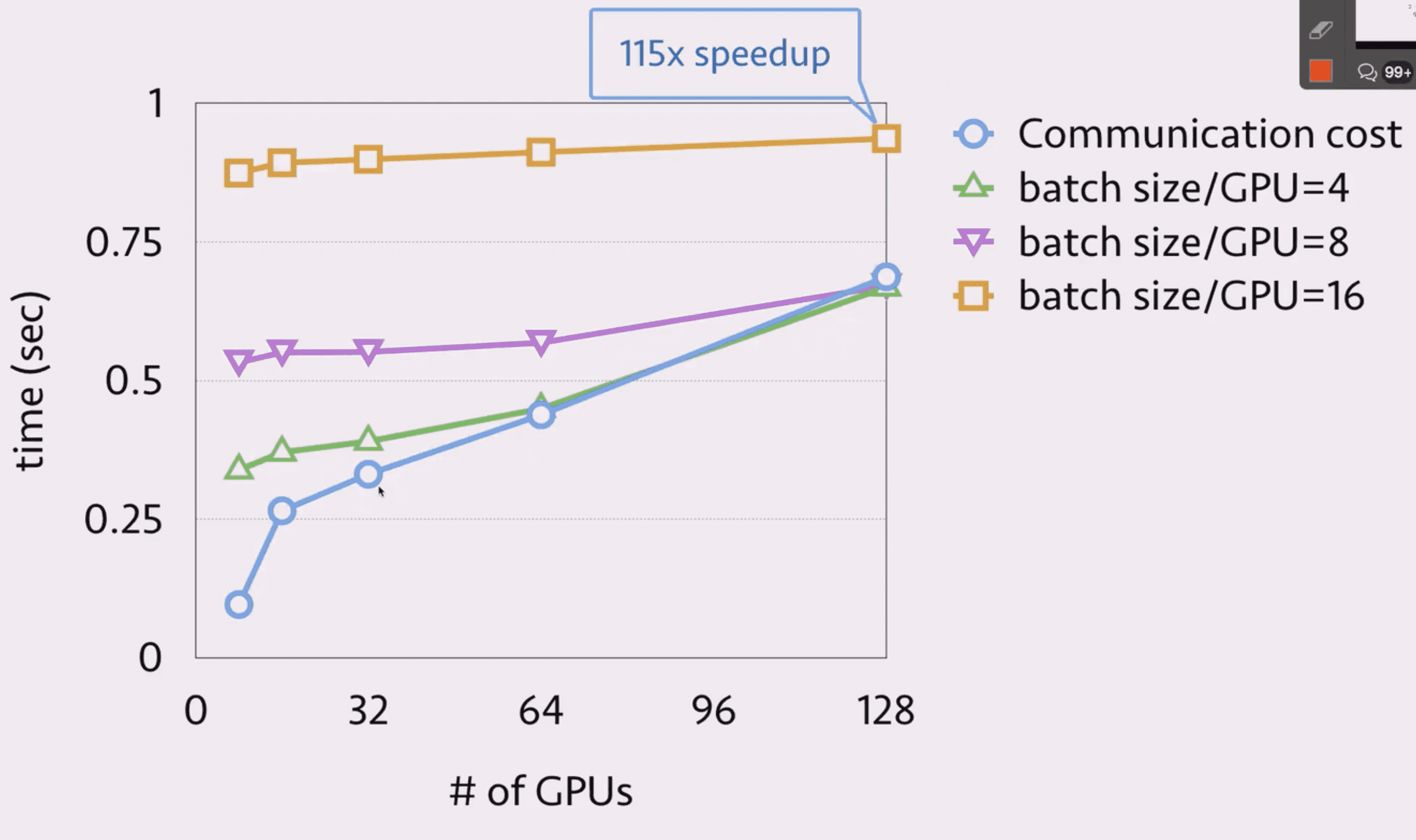
其中纵轴为计算开销。
所以尽量使用大的 batch_size 以使用计算掩盖通信。
收敛性
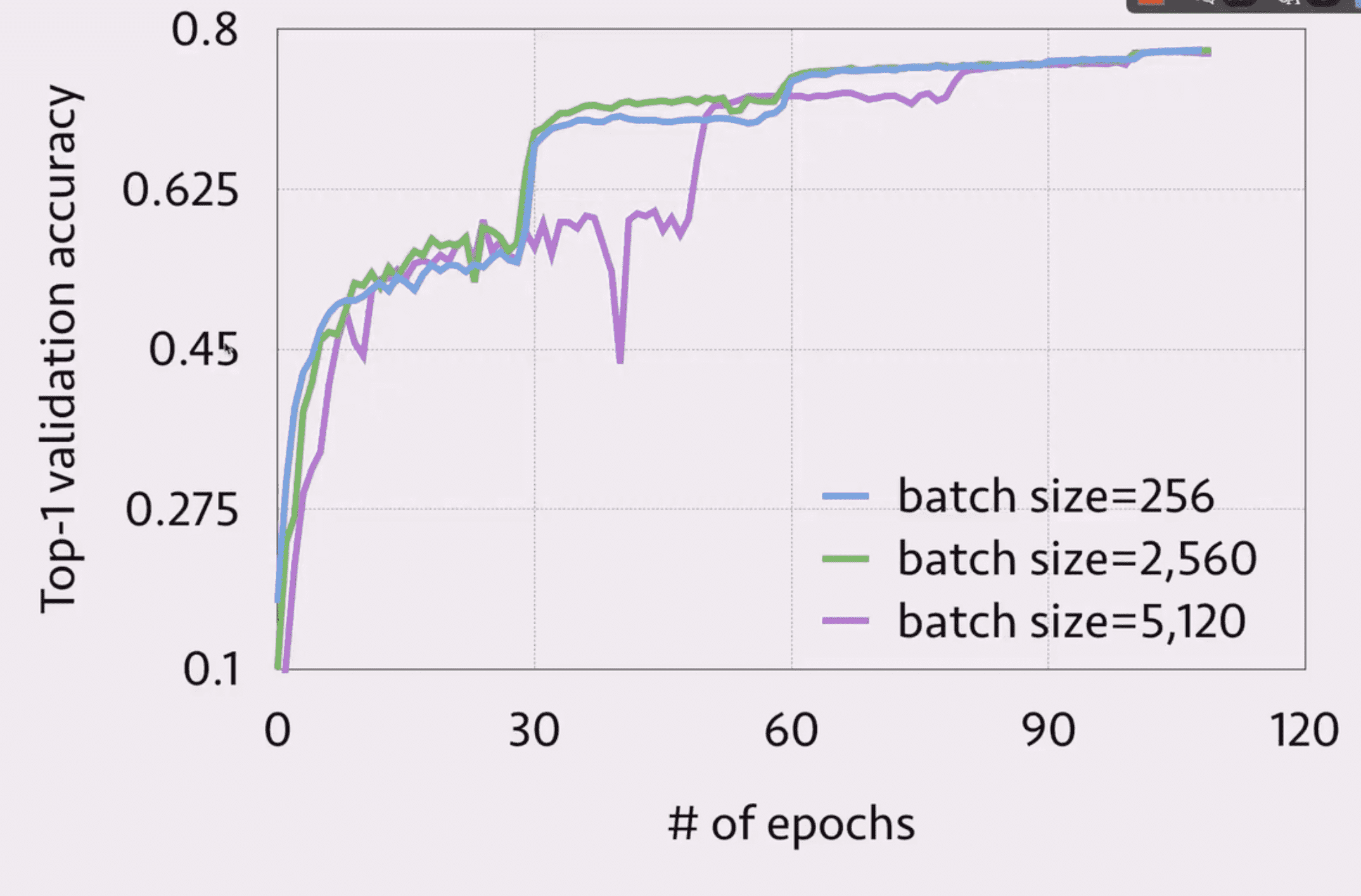
Delayed Block Proximal Gradient (DBPG)
Proximal Gradient Method

DBPG

- 每次只更新一个 block 的 feature
- block 之间可以并行跑,允许 block 之间的延迟
- 压缩通信流量
EMSO:efficient mini-batch SGD
mini-batch SGD
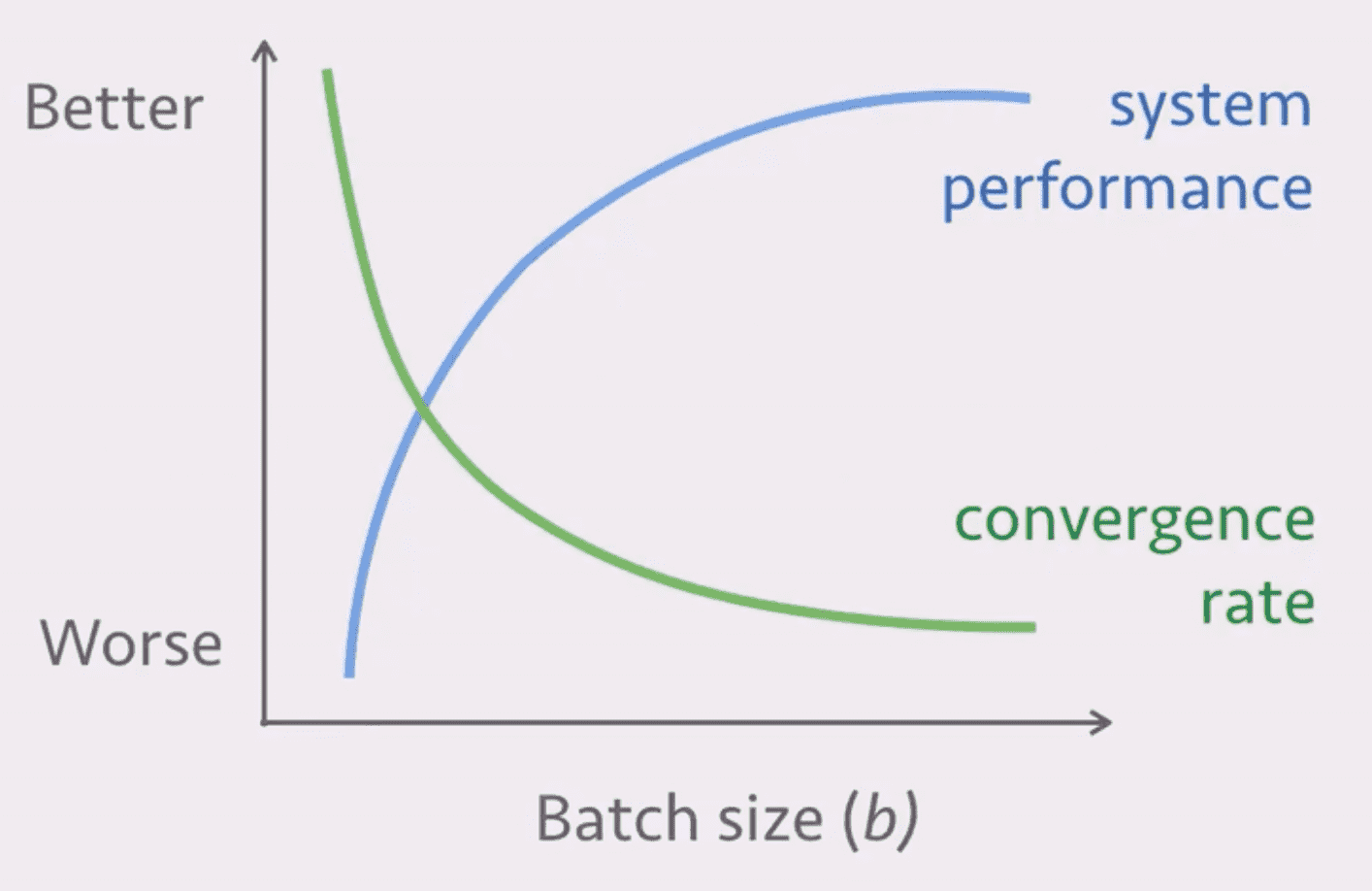
motivation

efficient mini-batch SGD

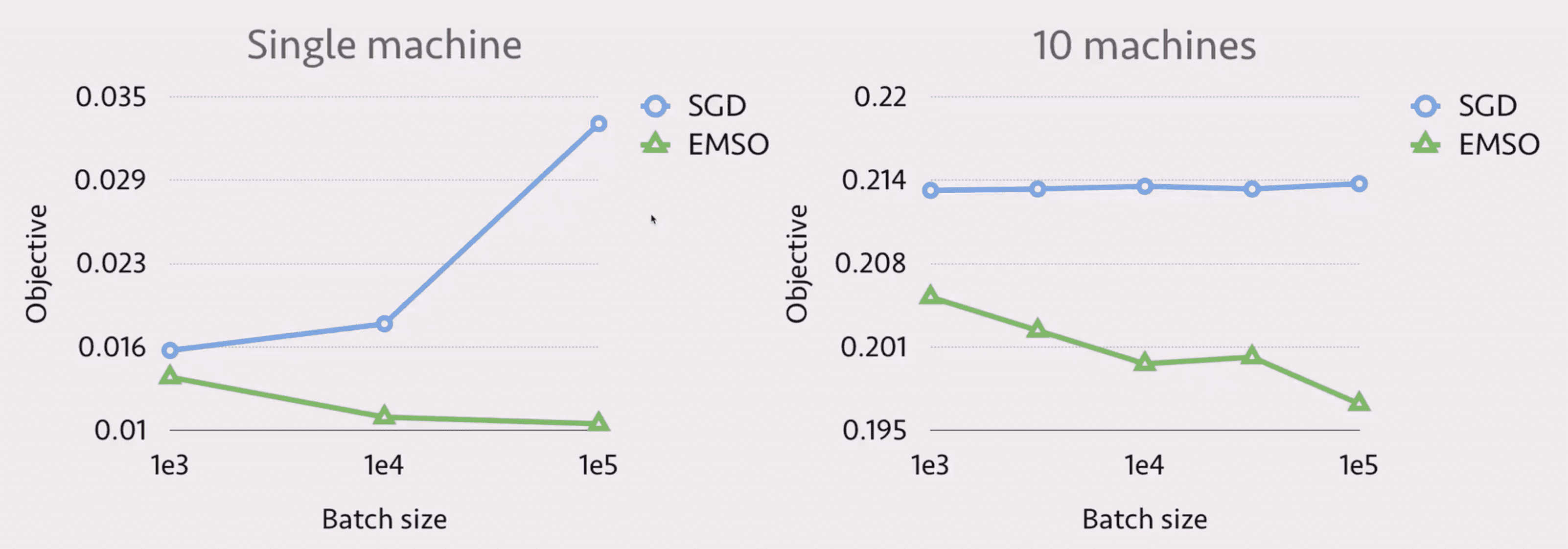
实验
李沐:基于系统和算法的协同设计的大规模分布式机器学习 | 系统开发