CUDA 知识点:流与并发执行 | CUDA
本文介绍了 CUDA 流的概念及其在异步并发执行中的应用。
概述
CUDA 流表示一个 GPU 操作队列,同一个流中的操作将以添加到流中的先后顺序而依次执行,不同流可以并行执行。可以将流类比成 CPU 编程中的“线程”的概念(注意不是 CUDA 编程概念中的线程):同一个“线程”中的任务串行执行,不同“线程”可以并行执行。
使用 CUDA 流,首先要选择一个支持设备 overlap 功能的设备,支持设备重叠功能的 GPU 能够在执行一个 CUDA 核函数的同时,还能在主机和设备之间执行拷贝数据操作。这一功能可以有效提升设备的利用率和吞吐量。比如在深度神经网络推理的场景中,如果不对数据拷贝和网络推理做重叠,那么进行完一次推理后就需要等待数据拷贝完成,如果这个数据是从主机端拷贝到设备侧的,那么就需要等待一段时间,这段时间 GPU 就空闲了,导致利用率不够高。使用了拷贝与计算重叠后,虽然单次拷贝-推理的延迟没有降低,但是单位时间内可以完成的推理次数变多了(即吞吐量提升)。
默认流
默认流可以分为两种:legacy default stream 和 per-thread default stream。
legacy default stream
默认情况下(或者使用 nvcc 编译时加上 --default-stream legacy 编译选项),每个设备(每张 GPU 卡)会创建一个默认流(NULL 流),称为 legacy default stream,该设备上所有不指定流或者指定默认流的操作全都放到这个流中。
对于有着相同 CUDA context 的流(可以简单理解为在同一个设备上的流),legacy default stream 会与它们同步(除 non-blocking stream 之外,non-blocking stream 可以通过 cudaStreamCreateWithFlags(&stream, cudaStreamNonBlocking) 显式创建)。当在 legacy default stream 中执行某个操作(如启动内核函数)时,legacy default stream 首先和所有非 non-blocking stream 上 wait,该操作会在 legacy default stream 中排队,然后所有非 non-blocking stream 都在 legacy default stream 上等待。这句话有点令人费解,看一个例子就明白了。
1 | k_1<<<1, 1, 0, s>>>(); |
在上面的代码中 k_1 在流 s 中运行,k_2 在 legacy default stream 中运行,k_3 在流 s 中运行。结果就是 k_2 会阻塞 k_1 并且 k_3 会阻塞 k_2(也即串行执行)。
这个特性在官方编程指南中 Implicit Synchronization 一节中也有叙述:如果主机线程在来自不同流的两个命令之间向 legacy default stream 发出指令,那么这些来自不同流的命令不能同时运行。
一句话总结:legacy default stream 会和所有非 non-blocking stream 产生同步。
per-thread default stream
在 CUDA 7.0 及以后的版本中,如果使用 nvcc 编译时加上 --default-stream per-thread 编译选项,每个主机线程会创建出一个默认流,称为 per-thread default stream。这样一来,每个线程的默认流之间就可以并发执行了。但是 per-thread default stream 不是 non-blocking stream,如果和 legacy default stream 在同一个程序中混用还是会导致隐式的同步。这里你可能会产生一个疑惑:legacy default stream 和 per-thread default stream 是通过编译选项控制的,它们不应该是互斥的吗?为什么还会同时出现?同时出现当然是可能当,就是当使用第三方库的时候:如果你使用了一个第三方库,而这个库会创建 legacy default stream,你,所以解决方案就是使用 non-blocking stream 以避免和 legacy default stream 的隐式同步。
多流实验
1 | const int N = 1 << 20; |
使用 legacy default stream:
1 | nvcc ./stream_test.cu -o stream_legacy |
使用 nvvp 分析: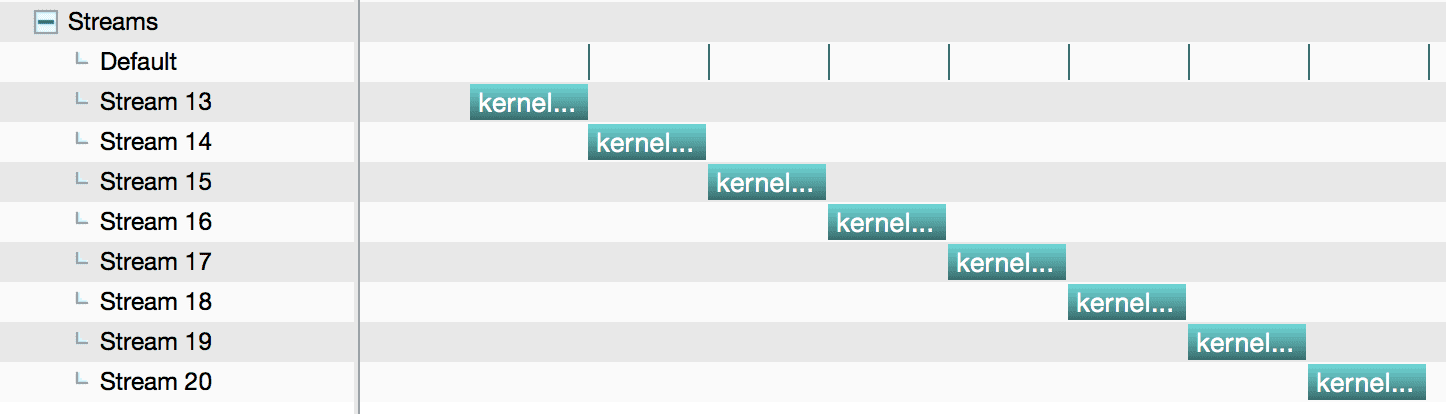
图中的 default 是 dummy kernel。这个实验验证了前面提到的一个特性:如果主机线程在来自不同流的两个命令之间向 legacy default stream 发出指令,那么这些来自不同流的命令不能同时运行。
使用 per-thread default stream:
1 | nvcc --default-stream per-thread ./stream_test.cu -o stream_per-thread |
使用 nvvp 分析:

图中的 Stream 14 是 dummy kernel。从结果可以看出,使用了 --default-stream per-thread 编译选项后,默认流从 legacy default stream 变成了 per-thread default stream,它和自定义流之间就可以并发运行了。
多线程实验
1 | const int N = 1 << 20; |
使用 legacy default stream:
1 | nvcc ./pthread_test.cu -o pthreads_legacy |
使用 nvvp 分析:
从结果可以看出,所有对内核函数的调用全都放到了 legacy default stream 中运行了。
使用 per-thread default stream:
1 | nvcc --default-stream per-thread ./pthread_test.cu -o pthreads_per_thread |
使用 nvvp 分析:
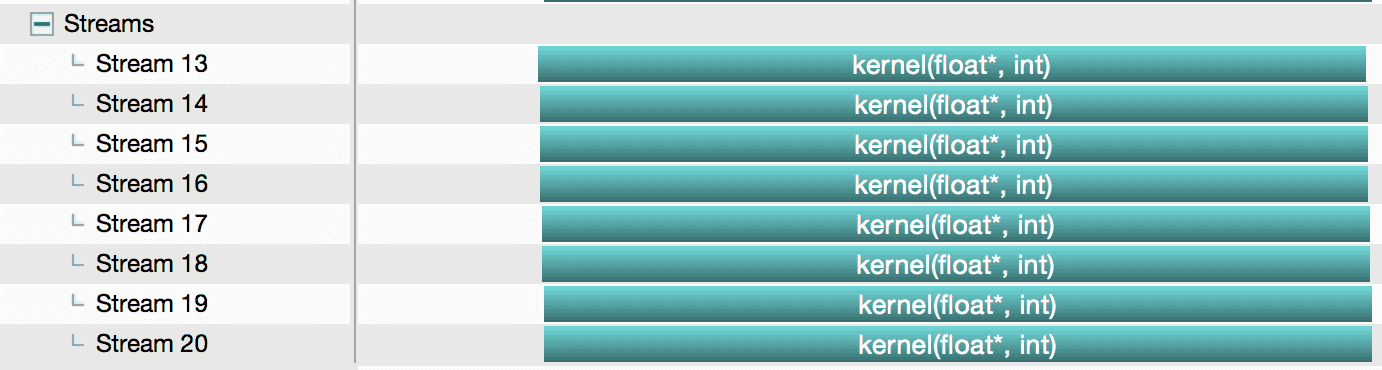
从结果可以看出,使用了 --default-stream per-thread 编译选项后,默认流从 legacy default stream 变成了 per-thread default stream,每个主机线程都创建了自己的 per-thread default stream,它们之间就可以并发运行了。
数据拷贝
同步拷贝
cudaMemcpy 是一个同步函数(即从主机端看该函数是同步的),只有在数据完成拷贝以后,函数才会返回。而且该函数会在拷贝前执行一次隐式的对默认流的同步,即 cudaMemcpy 会同步所有非 non-blocking 流。
注意:
- 对于从分页内存到设备内存的传输,一旦将分页内存的数据拷贝到临时存储器(然后通过 DMA 传输到设备存储器)函数就会返回,但到最终目标的传输可能尚未完成
- 对于从设备内存到设备内存的传输,不执行主机端同步
异步拷贝
cudaMemcpyAync 是一个异步函数,但是下面两种情况例外:
- 从设备内存到分页内存的传输相对于主机是同步的
- 从主机内存到主机内存的传输相对于主机是同步的
并发行为
CUDA 允许以下操作并发执行:
- 主机端计算
- 设备端计算(内核函数执行)
- 主机端到设备端传输数据
- 设备端到主机端传输数据
- 设备端内部传输数据
- 设备间传数据
内核函数并发执行
计算能力 ≥ 2.0 及以上的设备,支持多个内核函数并发执行。可以通过检查 concurrentKernels 来确定,如果返回 1,说明支持。
一个 CUDA context 中的内核函数不能与另一个 CUDA context 中的内核函数同时执行。
数据传输和内核函数并发执行(需要使用锁页内存)
一些设备支持数据传输(主机端到设备端、设备端到主机端)和内核执行并行,可通过检查 asyncEngineCount 来确认,大于 0 即可使用,前提是主机端使用锁页内存。一些设备支持设备端内部数据传输和内核执行/数据传输并行,可通过检查 concurrentKernels 来确认。
并发数据传输(需要使用锁页内存)
在计算能力 ≥ 2.0 的设备上,从主机锁页内存拷贝数据到设备内存和从设备内存拷贝数据到主机锁页内存,这两个操作可并发执行。可以通过检查 asyncEngineCount 属性查询这种能力,如果等于 2,说明支持。但是,相同方向的数据拷贝是不能并发执行的,如下图所示,其中棕色为从设备端到主机端的拷贝:

隐式同步
一般来讲,不同流内的命令可以并行,比如 kernel 函数计算与设备内存到锁页内存的拷贝:
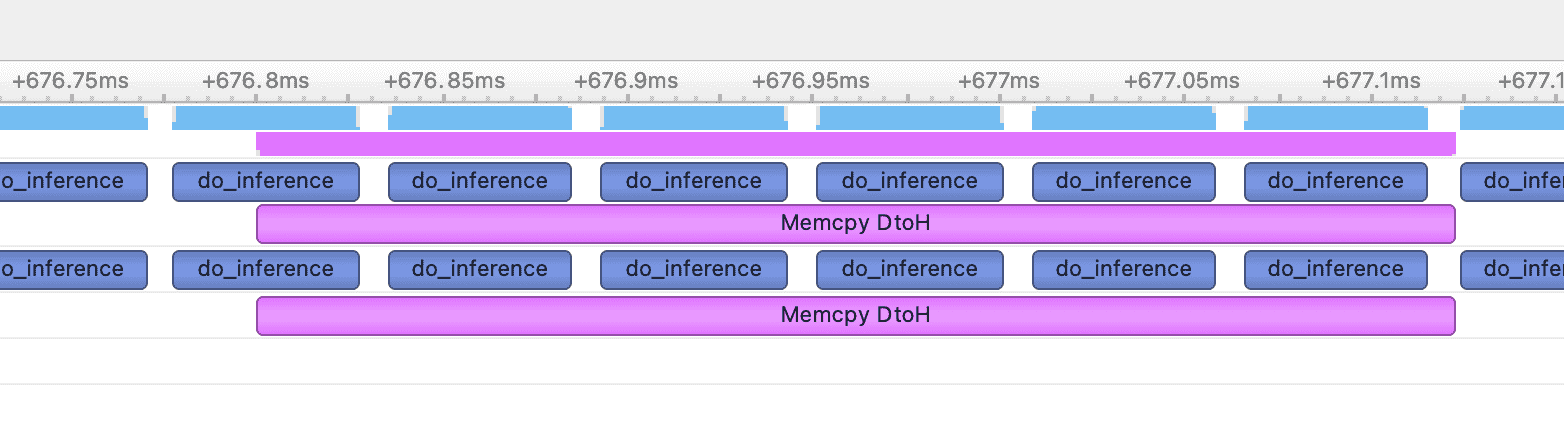
但是对于下面几种情况,它们之间不能并发:
- 锁页内存的分配
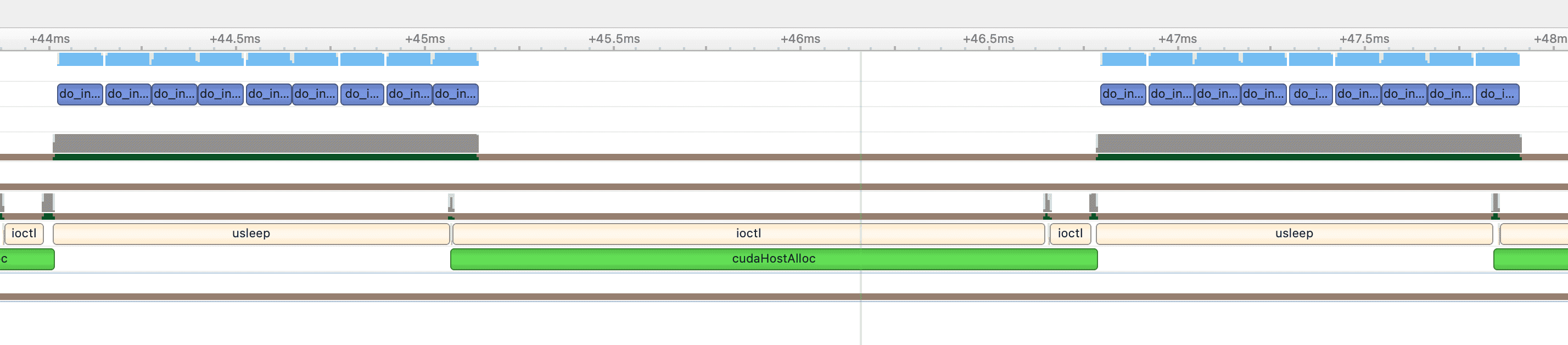
- 设备端内存分配
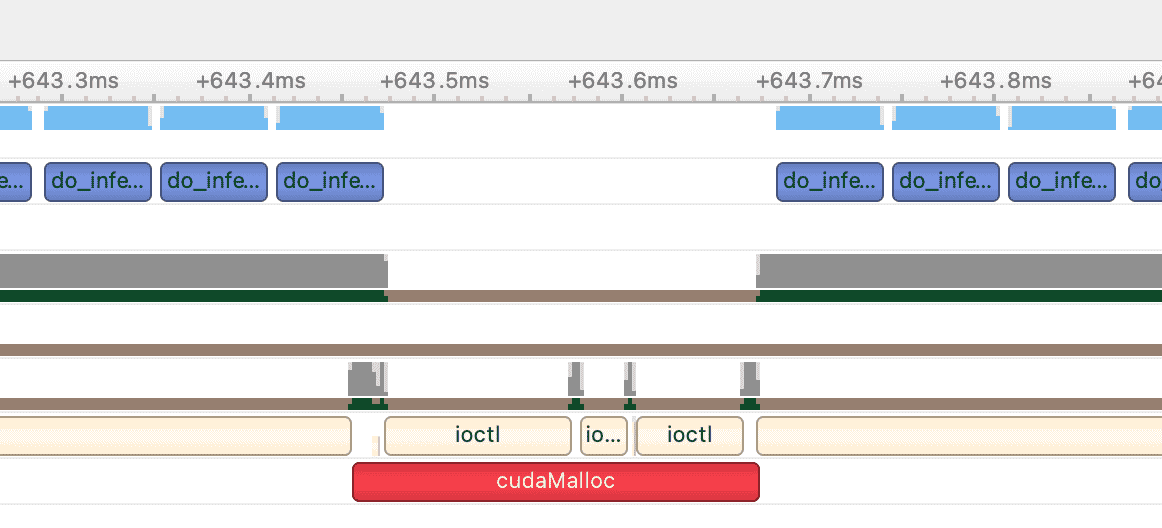
设备端内存设置(cudaMemset):cudaMemset 速度很快,影响有限
设备内部拷贝

NULL 流内的命令:显然同一个流内的命令无法并发
L1 /共享内存配置之间的切换:待验证
编译选项
而如果在编译时未指定相关 flag,或指定 --default-stream legacy,则默认流是一个特殊的流,称作 NULL stream。同一个设备的主机线程会共享这个 NULL stream。NULL stream 是一个同步流,所有命令会产生隐式的同步。对于未指定 --default-stream 进行编译的代码,将 --default-stream legacy 视为默认值。
如果在编译时使用了 --default-stream per-thread,或是在 include 任何 CUDA 头文件(包括 cuda.h 和 cuda_runtime.h)前定义 CUDA_API_PER_THREAD_DEFAULT_STREAM 1 这个宏,则主机端的每一个线程都有自己专属的默认流,即 per-thread default stream。
注意:当代码由 nvcc 编译时,#define CUDA_API_PER_THREAD_DEFAULT_STREAM 1 不能用于启用每个主机线程的默认流,因为 nvcc 在编译时会在每个编译单元(.cu 文件)之前隐式包含 cuda_runtime.h。在这种情况下,需要使用 --default-stream per-thread 编译标志,或者需要使用 -DCUDA_API_PER_THREAD_DEFAULT_STREAM=1 编译宏。
结论
- 当使用
--default-stream per-thread编译选项后,默认流就表现的和自定义流一样了,但仍然不是 non-blocking stream。 --default-stream per-thread编译选项必须在一开始编译的时候就加上,如果调用的 lib 里面有 cuda 代码,那么编译库的时候就要加上该选项,否则就无法保证在最终的程序中生效。- 由于 legacy default stream 会隐式同步每个线程的内核函数调用,而我们又无法保证我们使用的库是否在编译的时候开启了
--default-stream per-thread编译选项,所以最佳实践是显式创建 non-blocking stream:cudaStreamCreateWithFlags(&stream, cudaStreamNonBlocking)。
参考
CUDA C++ Programming Guide: Implicit Synchronization
Stream synchronization behavior
API synchronization behavior
GPU Pro Tip: CUDA 7 Streams Simplify Concurrency
CUDA 知识点:流与并发执行 | CUDA