搜索引擎优化(SEO) | 个人博客
不同于在各大博客平台上写博客,自建博客想要在搜索引擎上被搜索到还是需要做一些工作。如果你的博客是部署在 Github Pages 上,在不用国内 CDN 的情况是无法被在百度上被检索到的,这是由于 GitHub 屏蔽了百度的爬虫,导致百度无法抓取 GitHub 上的内容。
验证网站所有权
在 Google Search Console - 所有权 中进行所有权验证。
方法一:通过 HTML 文件验证(推荐)
- 将提供的 HTML 文件放在博客文件夹的
source目录下 - 在博客的配置文件中添加
skip_render: googleacxxxxxxxxxxxxxx.html跳过该验证文件的渲染
方法二:通过 DNS 记录验证
- 在腾讯云控制台搜索“DNS 解析”进入
- 进入当前域名解析的配置

- 添加记录

被动索引
提交站点地图
- 生成站点地图
1 | npm install --save hexo-generator-sitemap |
此时使用 hexo g 后就会在 public 文件夹下生成 sitemap.xml 文件。
- 提交站点地图
在 Google Search Console - 站点地图 中添加新的站点地图,在输入栏中输入http://your_blog_url/sitemap.xml然后提交。接下来就等待 Google 自动爬取博客内容就可以了。
请求编入索引
虽然搜索引擎会自动根据站点地图爬取网页内容,但是如果你的网站权重不高的话这个过程可能会比较久。如果你希望 Google 立即收录你的网页,可以直接在 Google Search Console 上方输入你想被收录的网页,然后点击请求编入索引,等待片刻你的网页就可以被 Google 搜索到了。
添加 nofollow 标签
一般博客中都会引用一些其他链接,为了防止搜索引擎抓取这些链接而导致分散网站权重,需要为这些站外链接设置 nofollow 标签,可以使用 hexo-autonofollow 插件自动完成这一个步骤。
1 | npm install --save hexo-autonofollow |
需要在博客配置文件配置:
1 | nofollow: |
添加 robots.txt
robots.txt 是一种存放于网站根目录下的 ASCII 编码的文本文件,它通常告诉网络搜索引擎的漫游器(又称网络蜘蛛),此网站中的哪些内容是不应被搜索引擎的漫游器获取的,哪些是可以被漫游器获取的。robots.txt 是一个协议,而不是一个命令。robots.txt 是搜索引擎中访问网站的时候要查看的第一个文件。robots.txt 文件告诉蜘蛛程序在服务器上什么文件是可以被查看的。当一个搜索蜘蛛访问一个站点时,它会首先检查该站点根目录下是否存在 robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,所有的搜索蜘蛛将能够访问网站上所有没有被口令保护的页面。
在博客的 source 文件夹下新建 robots.txt 文件,内容如下:
1 | User-agent: * |
主动推送
可以参考 hexo-submit-urls-to-search-engine 中文文档。
百度
验证网站所有权
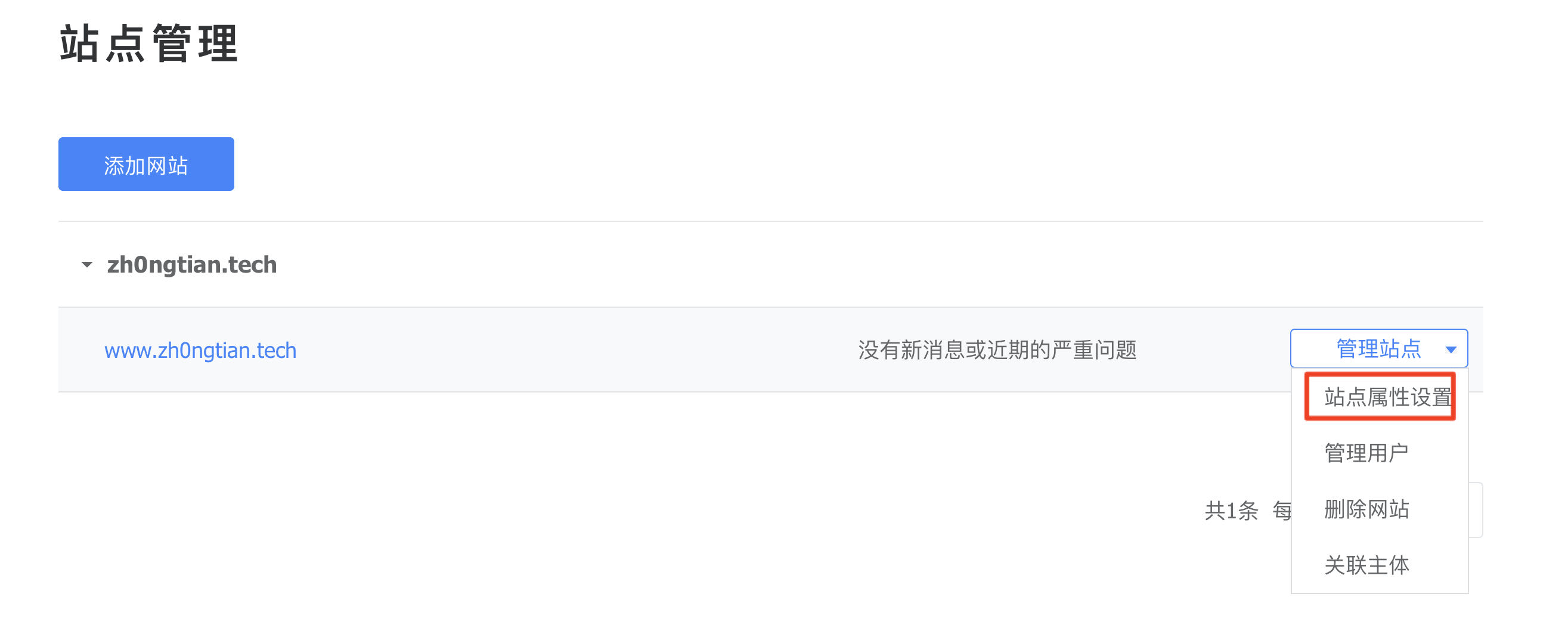
进入百度资源搜索平台,点击上方“用户中心”,选择“站点管理”-“添加网站”,按照提示进行。
验证方式同 Google,如果选择 CNAME 验证,注意主机名需要填百度给出的网址前缀,也就是说,下面两张图的黑色块部分的内容应该是相同的。
百度站点管理:
腾讯云 DNS 设置控制台:
主动推送
- 安装插件
1 | npm install hexo-baidu-url-submit |
- 修改配置
1 | # _config.yml |
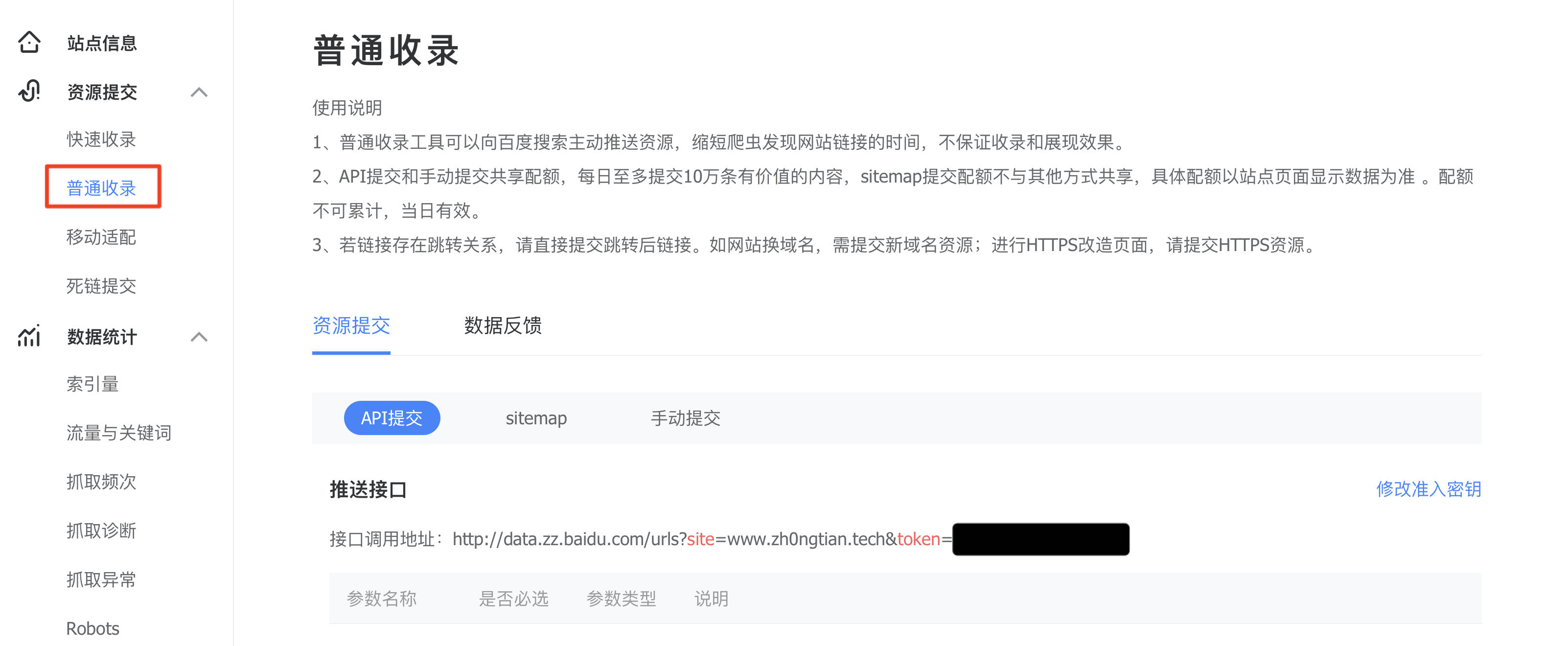
配置中的 token 可以在百度站长平台找到,步骤如下图所示,黑色块挡住的就是 token:
- 修改配置
1 | # _config.yml |
注意这里一定要和在站长平台中添加的域名一直,如果站长平台中前缀有 www 而配置中没有写,主动推送时将会报错 not_same_site。
- 在
_config.yml加入新的 deployer
1 | deploy: |
验证
在搜索引擎搜索 site:your_blog_url,如果有内容,说明已经被搜索引擎收录。
参考
搜索引擎优化(SEO) | 个人博客