CUDA 知识点:bank 冲突 | CUDA
本文介绍了 CUDA 编程中的 bank 冲突的原理和解决方法。
什么是 bank 冲突?
为了获得高的内存带宽,共享内存在物理上被分为 32 个(刚好等于一个线程束中的线程数目,即内建变量 warpSize 的值)同样宽度的、能被同时访问的内存 bank。我们可以将 32 个 bank 从 0~31 编号。在每—个 bank 中又可以对其中的内存地址从 0 开始编号。为方便起见,我们将所有 bank 中编号为 0 的内存称为第 1 层内存,将所有 bank 中编号为 1 的内存称为第 2 层内存。在开普勒架构中,每个 bank 的宽度为 8 字节,在所有其他架构中,每个 bank 的宽度为 4 字节。
对于 bank 宽度为 4 字节的架构:共享内存中每连续的 128 字节的内容分摊到 32 个 bank 的同一层中,每个 bank 负责 4 字节的内容。如下图所示:
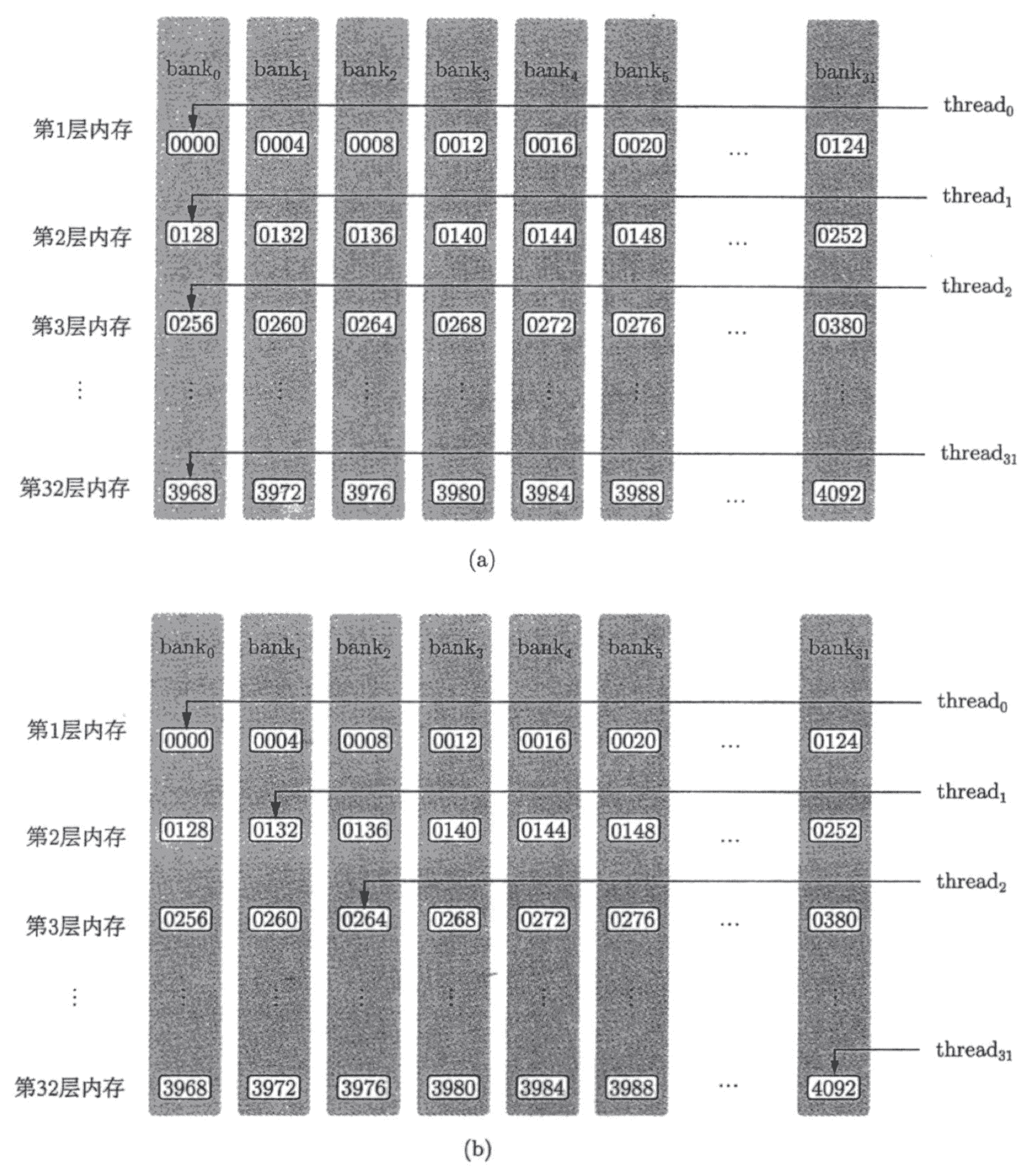
当同一个 warp 中的不同线程访问一个 bank 中的不同的地址时(访问同一个地址则会发生广播),就会发生 bank 冲突。在最坏的情况下,即一个 warp 中的所有线程访问了相同 bank 的 32 个不同地址的话,那么这 32 个访问操作将会全部被序列化,大大降低了内存带宽。在一个 warp 内对同一个 bank 中的 n 个地址同时访问将导致 n 次内存事务,称为发生了 n 路 bank 冲突。需要注意的是,不同 warp 中的线程之间不存在 bank 冲突。
上述对于 bank 冲突的讨论都是基于「地址」,如果同一个 warp 中的线程访问的是同一个 bank 中同一个地址,是不会发生 bank 冲突的。也就是说,当同一个 warp 中的线程访问同一层中一个 32 位大小的数据类型的数据时,是不会发生 bank 冲突的。
通常可以用改变共享内存数组大小的方式来消除或减轻共享内存的 bank 冲突,具体例子见《CUDA 经典问题:矩阵转置》。
检测
1 | # 读取共享内存时的 bank 冲突 |
寄存器 bank 冲突
本节转载自CUDA 矩阵乘法终极优化指南,原文有删改。
NVIDIA GPU 每个 SM 有独立的 Register File,而 Register File 被分为若干个 Bank,以 Maxwell 为例,若一条指令所需的源寄存器有 2 个以上来自于同一 Bank,则会产生 conflict,指令会相当于重发射,浪费一个 cycle。Maxwell/Pascal 的 Register File 的 Bank 数为 4,寄存器的 id%4 即为该寄存器的所属 bank(如 R0 属于 Bank 0,R5 属于 Bank 1),FFMA R1, R0, R4, R1 这样的指令就回产生寄存器 Bank conflict。而 Turing 架构做了改进,Register File 被分为 2 个 Bank,每个 Bank 有 2 个 Port,若非三个源寄存器 id 同奇偶则不会产生冲突,大大缓解了寄存器 Bank conflict。
maxas 中的 Maxwell SGEMM SASS Kernel 为了缓解寄存器 Bank conflict,就对参与 FFMA 计算的寄存器做了精巧的分配(参考 maxas 的 SGEMM 文档),如下图所示:

经过对 C 的巧妙排布,寄存器 Bank conflict 大大减少,但依然无法完全避免(如上图中黑框标识的部分,A/B 所使用的寄存器会产生 Bank conflict),这部分冲突就需要用到寄存器 Reuse 来消除。
寄存器 Reuse 是 NVIDIA 为了缓解寄存器 Bank conflict 的问题,在 Maxwell 开始引入的一种机制,NVIDIA 在读取指令操作数的 Collector 单元加入了寄存器的 Reuse Cache。Reuse Cache 是只读的,指令获取 Operand 是否通过此 Cache 由该指令的 control code(maxas 的 control code wiki 中有详细的介绍)所指定,使用 cuobjdump 反汇编一些 Kernel 可以发现一些寄存器后有.reuse的 flag,即表示该寄存器从 Reuse Cache 而非 Register File 中取值,从而消除寄存器 Bank conflict:
1 | # Maxwell GPU |
但是使用.reuse需要满足一定条件(寄存器将被改写前不能设置.reuse),胡乱设置 reuse flag 会有可能获取的是历史值,造成计算错误,根据笔者的理解,.reuse更像是使该寄存器的值在 Reuse Cache 中 hold 住的标识。nvcc 编译 CUDA Kernel 也会使用 Reuse Cache 去规避一些寄存器 Bank conflict,但是因为寄存器分配及指令排布的原因,Reuse 的利用率并不高,反汇编我们刚才写的 SGEMM Kernel,对主循环的所有 FFMA 指令做个统计,可以发现 Reuse Cache 仅达到 20%左右,而 maxas 的 SASS Kernel 通过设计使得 Reuse 的利用率可以达到 49%。
最终通过 SASS 精细调优的 SGEMM Kernel 的性能可以全面超越 cublas,感兴趣的同学们可以自行编译 maxas 中的 SGEMM Kernel 在 Maxwell 或者 Pascal GPU 上进行测试。最后,虽然使用 SASS 能充分挖掘 GPU 的性能,但面临有三大问题:1. 第三方 NV GPU 汇编器依赖于对 GPU 架构的逆向研究,可能因为没有探究到全部的硬件底层细节而存在未知的 BUG;2. 汇编 Kernel 难于开发,更难于调试;3. NV 每一代 GPU 的 ISA(指令集)都不尽相同,需要不断开发对应的汇编器和汇编 Kernel。正因为这几大问题的存在,使得使用 SASS 编写 Kernel 是个费时费力的工作,除非有追求极致性能的需求,否则不建议轻易尝试。
参考
《CUDA 编程:基础与实践》(樊哲勇,清华大学出版社)
CUDA : How to detect shared memory bank conflict on device with compute capabiliy >= 7.2?
CUDA 知识点:bank 冲突 | CUDA