CUDA 实践:矩阵转置 | CUDA
本文介绍了使用 CUDA 实现矩阵转置的两种方式与优化方法。
使用全局内存进行矩阵转置
1 | __global__ void matrix_trans_kernel(int *in, int *out) { |
以上两条语句都能实现矩阵转置,但是它们将带来不同的性能。在不考虑数据内存地址是否对齐的情况下,我们可以说上面那行代码对矩阵 in 和 out 的访问分别是非合并的和合并的,下面那行代码则反过来。
值得一提的是,从帕斯卡架构开始,如果编译器能够判断某个全局内存变量在整个核函数的范围都只可读(如这里的矩阵 in),则会自动用函数 __ldg() 读取全局内存,从而对数据的读取进行缓存,缓解非合并访问带来的影响。对于全局内存的写入则没有类似的函数可用。所以,在不能同时满足读取和写入都是合并的情况下,一般来说应当尽量做到合并地写入。
使用共享内存优化矩阵转置
在矩阵转置问题中,对全局内存的读和写这两个操作,总有一个是合并的,另一个是非合并的。利用共享内存可以改善全局内存的访问模式,使得对全局内存的读和写都是合并的。核心思路是用一个 block 处理 BLOCK_SIZE * BLOCK_SIZE 的矩阵块。
1 | const int BLOCK_SIZE = 32; |
优化 bank 冲突
在上面的例子中,从 out[j * N + i] = buffer[threadIdx.x][threadIdx.y]; 这一行代码可以看出,同一个线程束中的 32 个线程(连续的 32 个threadIdx.x 值)将对应共享内存数组中跨度为 32 的数据,也就是说这 32 个线程将刚好访问同一个 bank 中的 32 个数据,这将导致 32 路 bank 冲突。
通常可以用改变共享内存数组大小的方式来消除或减轻共享内存的 bank 冲突。将上述核函数中的共享内存定义修改为 __shared__ int buffer[BLOCK_SIZE][BLOCK_SIZE + 1]; 就可以完全消除 bank 冲突(共享内存的读写代码也要进行相应的修改)。这是因为这样做改变了共享内存同一列中元素同属一个 bank 的情况,如下图所示:
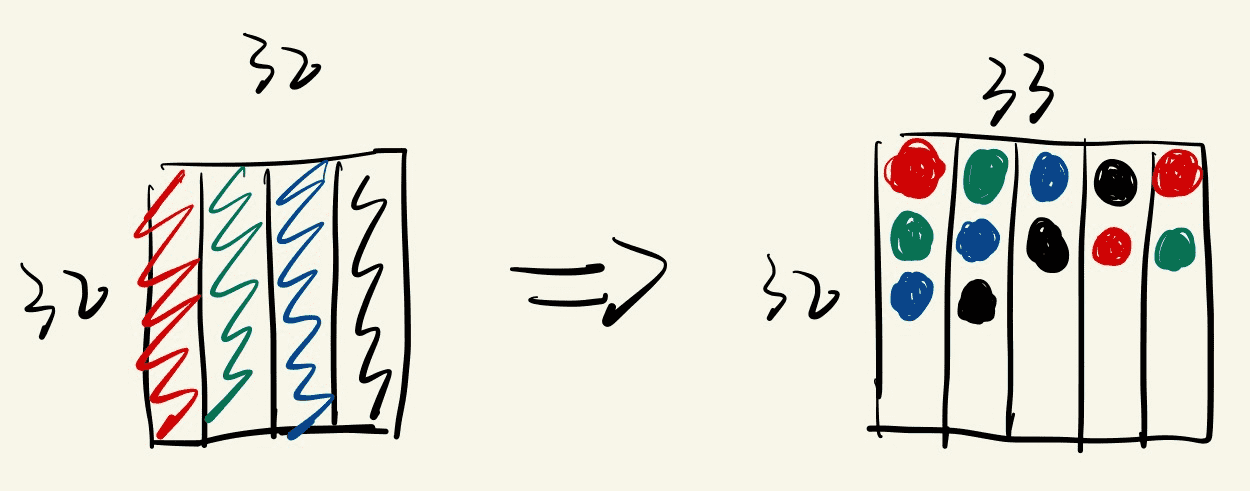
同一个线程束中的 32 个线程(连续的 32 个 threadIdx.x 值)将对应共享内存数组中跨度为 33 的数据。如果第 1 个线程访问第 1 个 bank 的第 1 层,第 2 个线程则会访问第 2 个 bank 的第 2 层(而不是第 1 个 bank 的第 2 层),以此类推。
参考
《CUDA 编程:基础与实践》(樊哲勇,清华大学出版社)
CUDA 实践:矩阵转置 | CUDA