CUDA 实践:前缀和 | CUDA
本文介绍了使用 CUDA 实现前缀和的思路与优化方法。
问题
对于数组 a,其前缀和为数组 b,a 和 b 的长度均为 n。对于任意 i < n 都满足 b[i] = a[0] + a[1] + ... + a[i]。
基本思路
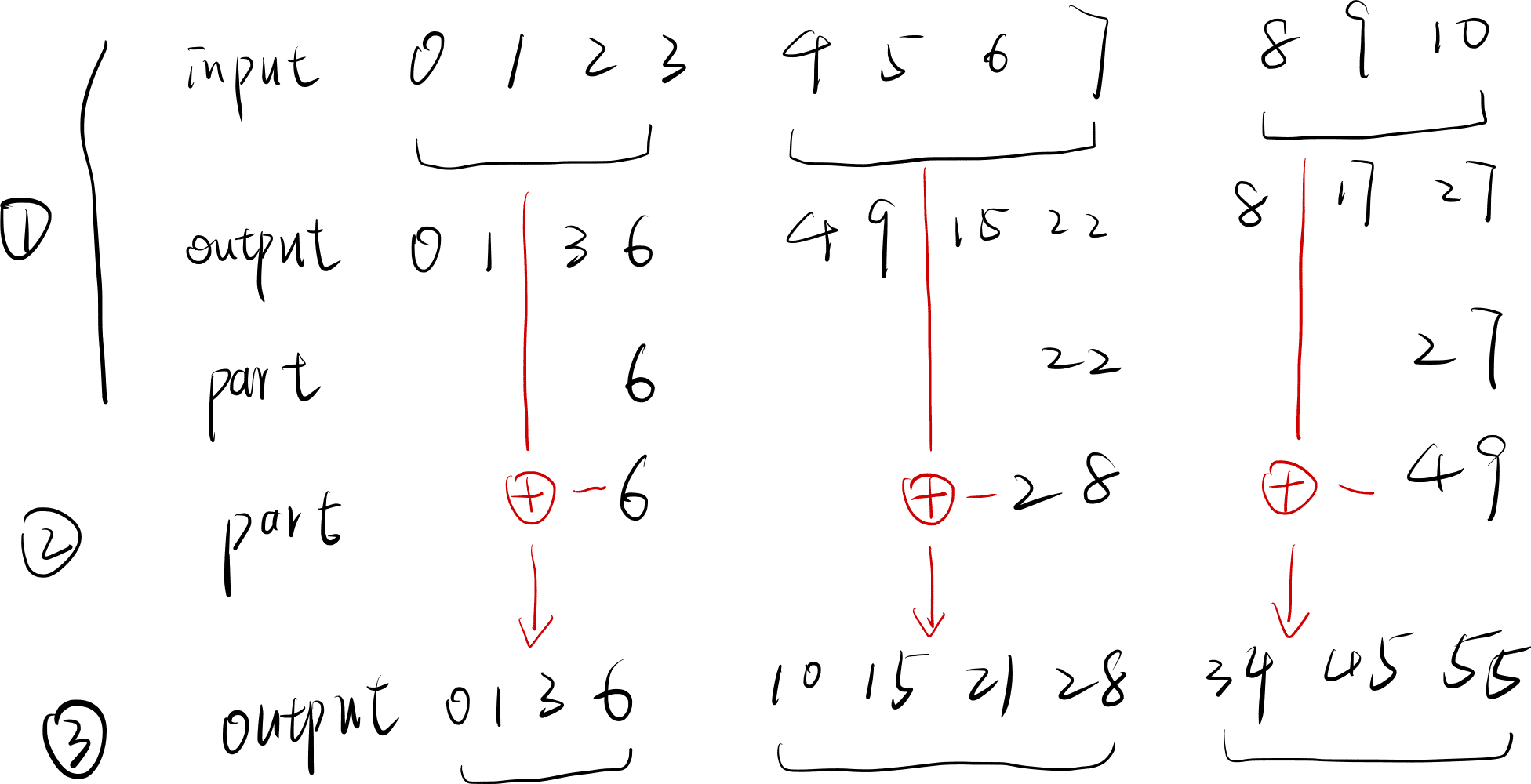
前缀和的思路如下:
- 将整个数据分成几个部分,每个部分分别计算前缀和,存入数组 output 中,然后将每个部分中最大的值存入一个数组 part 中
- 对上述数组 part 求前缀和
- 将 part 中的元素分别加到 output 中
代码实现
Baseline
1 | __global__ void ScanPart(int *input, int *part, int *output, int n, int part_num) { |
3482 us
使用共享内存
首先使用共享内存优化下数据的读取和写入:
1 | __device__ void ScanBlock(int *shm) { |
3482 us -> 610 us (-82%)
拆分至线程束级别
前面的实现将整个数组的 scan 拆分成每个 block 的 scan,这里还可以进行进一步的拆分:将 block 的 scan 拆分成 warp 的 scan。
1 | __device__ void ScanWarp(int *shm_data, int lane_id) { |
610 us -> 351 us (-42%)
优化线程束级别 scan
为了方便解释算法,这里假设对 16 个数做 scan,如下所示:
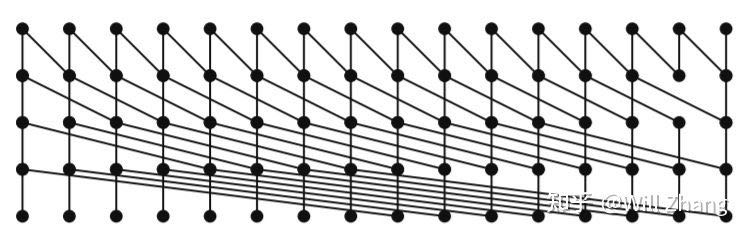
横向的 16 个点代表 16 个数,时间轴从上往下,每个入度为 2 的节点会做加法,并将结果广播到其输出节点,对于 32 个数的代码如下:
1 | __device__ void ScanWarp(int *shm_data, int lane_id) { |
351 us -> 193 us (-45%)
Zero Padding
如果要更进一步消除 ScanWarp 中的条件分,warp 中所有线程都执行同样的操作,这就意味着之前不符合条件的线程会访问越界,需要做 zero padding 使其不越界:每个 warp 需要一个 16 大小的 zero padding 才能避免 ScanWarp 在没有分支的情况下不越界。
之前需要申请共享内存的大小为 BLOCK_SIZE + 32,这里多出的 32 前面也有解释(用于存放每个 warp 的和),所以之前申请共享内存的大小也可以表示为 (warp_num + 1) * 32。由于每个 warp 额外需要 16 大小的共享内存,所以最终需要申请的共享内存大小为 (warp_num + 1) * (16 + 32)。
这里需要做两件事情:
- 申请共享内存时多申请 zero padding 的部分:
- 补 0 以消除 ScanWarp 中的条件分支
1 | __device__ void ScanWarp(int *shm_data) { |
193 us -> 192 us (-1%)
这一节的优化看似不大,主要是被瓶颈掩盖了。
递归
当前瓶颈在于,ScanPartSum 是由一个线程去做的,这块可以递归地做:
1 |
|
192 us -> 162 us (-16%)
使用 Warp Shuffle
1 | __device__ int ScanWarp(int val) { |
162 us -> 120 us (-26%)
小结
以上便是前缀和的一种解题思路。除此之外还有另一种:先计算每个 part 的和,在最后一步做 scan。具体内容见参考链接。
参考
CUDA 实践:前缀和 | CUDA