LLVM 编译器入门 | 编译器
本文是系列视频 LLVM 编译器入门 的笔记。
项目概述
项目组成
1 | CONTRIBUTING.md flang llvm-libgcc |
- clang:解析 C/C++ 代码
- mlir:构建可重用和可扩展编译器基础设施的新方法
- openmp:提供了一个 OpenMP 运行时库函数
- polly:使用多面体模型实现了一套缓存局部性优化以及自动并行和向量化
- llvm:主要代码
命令行工具
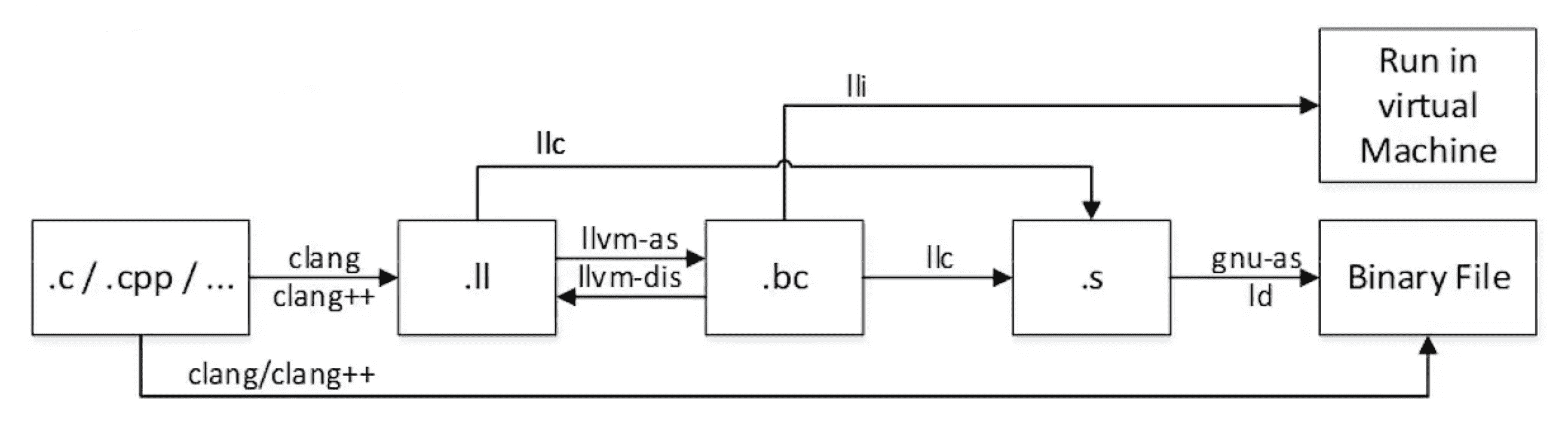
- llc:LLVM 静态编译器
- lli:直接从 LLVM 字节码执行程序
- llym-as:LLVM 汇编器
- llvm-dis:LLVM 反汇编器
- opt:LLVM 优化器
更多命令行工具:https://llvm.org/docs/CommandGuide。
Clang
Clang 组成
Clang 子项目为 LLVM 提供 C 语言系列语言(C、C++、Objective C/C++、OpenCL、CUDA 和 RenderScript)的语言前端和工具基础设施。
Clang driver(命令行表示是 clang)和 Clang 前端(依照详细实现来说就是 Clang 的那些库所实现的前端)是不同的。Clang driver 不只包括了 Clang 前端,还包括使用 LLVM 的库实现的编译器的中间阶段以及后端,同时也集成了 assembler。
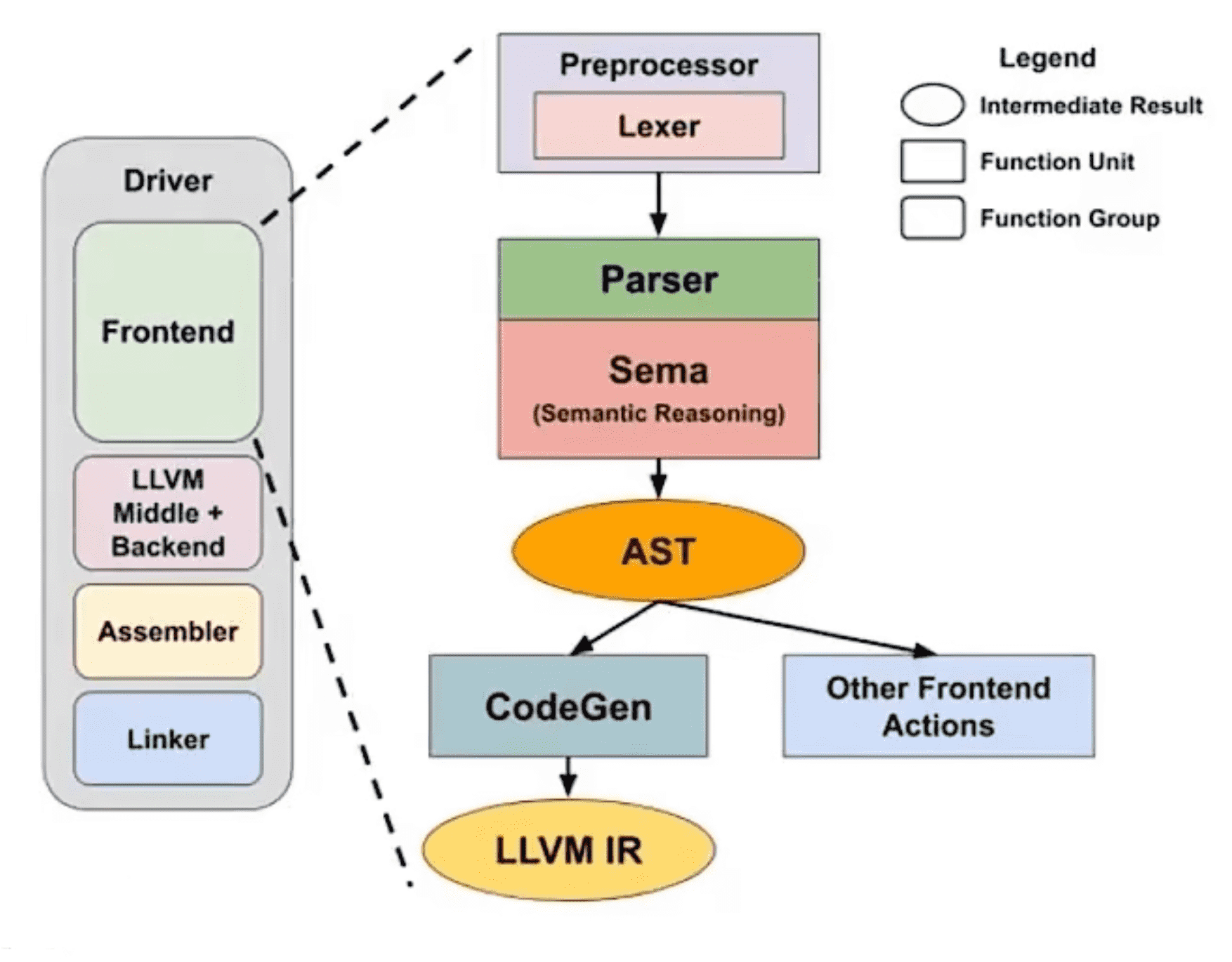
- 预处理(preprocessor):头文件以及宏的处理
- 词法分析(lexer):词法分析器的任务是从左向右逐行扫描源程序的字符,识别出各个单词并确定单词的类型 ,将识别出的单词转换成统一的表示——词法单元(token)形式
- 语法分析(parser):主要任务是从词法分析器输出的 token 序列中识别出各类短语,并构造语法分析树。如果输入字符中的各个单词恰好自左至右地站在分析树的各个叶结点上,那么这个词串就是该语言的一个句子,语法分析树描述了句子的语法结构
- 语义分析(sema):收集标识符的属性信息与语义检查。标识符的属性包括种属(kind)、类型(Type)、存储位置和长度、值、作用域、参数和返回值类型。语义检查包括变量或过程未经声明就使用、变量或过程名重复声明、运算分量类型不匹配、操作符与操作数之闻的类型不匹配
- 代码生成(CodeGen):将 AST 转换成相应的 LLVM IR
AST
举个例子,OpenMP 中 AST 节点层次结构:
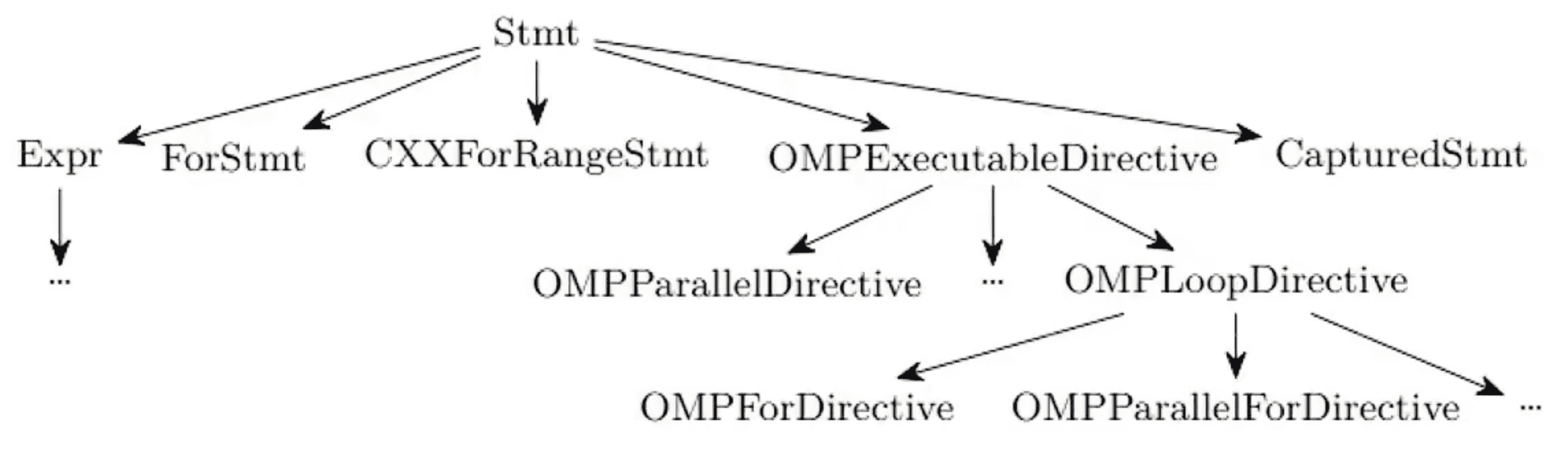
AST 可细分为:
- 声明:declaration(Decl)
- 指令:statement(Stmt)
- 表达:expression(Expr)

IR 优化
基本概念
LLVM 基于统一的中间表示来实现优化遍,中间表示采用静态单赋值(SSA)形式,该形式的虚拟指令集能够高效的表示高级语言。如下图所示,当同一变量出现多次赋值时,通过 SSA 变量重命名的方式加以区分,可以避免出现多次定义的情况:

IR 表示
LLVM IR 的三种表达形式:
- 内存形式,如 BasicBlock、Instruction 这种 C++ 类
- 字节码形式,这是一种序列化的二进制表示形式
- LLVM 汇编文件形式,也是一种序列化的表示形式,与字节码的区别是汇编文件是可读的、字符串的形式
LLVM IR 内存形式的几个类:
- Module 类,可以理解为一个完整的编译单元。一般来说,这个编译单元就是一个源码文件,如一个后缀为 cpp 的源文件
- Function 类,顾名思义就是对应于一个函数单元,可以描述两种情况,分别是函数定义和函数声明
- BasicBlock 类,表示一个基本代码块,即一段没有控制流逻辑的基本流程,相当于程序流程图中的基本过程(矩形表示)
- Instruction 类,即 LLVM 中定义的基本操作,比如加减乘除这种算数指令、函数调用指令、跳转指令、返回指令等
程序流图可视化:
1 | opt -analyze -dot-cfg-only test.ll # 简图 |
中间优化遍(pass)
优化遍有三种类型:分析(analysis passes)、转换(transform passes)、使用(utility passes),详情见 https://llvm.org/docs/Passes.html。
优化遍管理器:https://llvm.org/docs/NewPassManager.html。
代码生成
基本概念
源码结构:
- 特定目标的抽象目标描述接口的实现。这些机器描述使用 LLVM 提供的组件,并可以选择提供定制的特定于目标的传递,为特定目标构建完整的代码生成器。目标描述位于
lib/Target中 - 用于实现本机代码生成的各个阶段(寄存器分配、调度、堆栈帧表示等)的目标无关算法。此代码位于
lib/CodeGen中 - 目标独立 JIT 组件。LLVM JIT 完全独立于目标(使用 TargetJITInfo 结构来处理特定于目标的问题)。独立于目标的 JIT 的代码位于
lib/ExecutionEngine/JIT中
结构设计
- 指令选择:这个阶段主要将 LLWM 代码转换为目标指令的 DAG。通过模式将节点匹配到机器指令,指令的描述和模式由 LLVM 后端开发者进行编写,主要使用 TableGen 语法在 td 文件中进行描述,同时复杂的模式也可以通过直接 C++ 编码实现
- 调度和格式化:此阶段将指令选择完成的 DAG 转化为指令序列,该过程中可以设置符合目标硬件的调度策略。然后根据该顺序将指令作为机器指令发出
- 基于 SSA 的机器代码优化(可选阶段):一系列基于 SSA 的机器码优化,像模块调度、窥孔优化
- 寄存器分配:目标代码从 SSA 形式的无限虚拟寄存器文件转换为目标硬件使用的具体寄存器文件,此阶段将引入溢出代码并消除程序中的所有虚拟寄存器引用。
- Prolog/Epilog 代码插入:一旦为函数生成了机器码,就能推算出所需的堆栈空间量,就可以插入函数的 prolog 和 epilog 代码,并且消除「抽象堆栈位置引用」。此阶段负责实现优化,如帧指针消除和堆栈打包
- 后期机器代码优化:对「最终」机器码进行操作的优化可以放在这里,比如溢出代码调度和窥孔优化
- 代码发射:最后阶段实际输出当前函数的代码,生成目标硬件汇编码或是机器码
指令选择(IR => 汇编)
基于 SelectionDAG 的指令选择:
- 初始化 DAG:执行从输入 LLVM 代码到非法 SelectionDAG 的简单转换(-view-dag-combine-dag)
- 优化 SelectionDAG:这个阶段对 SelectionDAG 执行简单的优化以简化代码,并识别元指令。以生成高效代码,并使 DAG 阶段的选择指令更简单(-view-legalize-dags)
- 合法化 SeleetionDAG 类型:转换 SelectionDAG 节点,以消除目标硬件不支持的数据类型(-view-agcombine2-dags)
- 优化 SelectionDAG:清除类型合法化造成的代码元余(-view-isel-dags)
- 合法化 SelectionDAG 操作:转换 SelectionDAG 节点,以消除目标硬件不支持的任何操作 (-view-sched-dags)
- 优化 SelectionDAG:消除操作合法化造成的代码冗余
- 从 DAG 中选择指令:将 DAG 操作与目标硬件指令相匹配,将目标无关的输入 DAG 转换为目标硬件指令的另一个 DAG
- SelectionDAG 调度:最后一个阶段为目标指令 DAG 中的指令分配一个线性顺序,并将它们发送到正在编译的 MachineFunction 中
上述命令行选项是针对 llc 的。
接下来看一个例子:

在适配新的目标硬件时,主要的工作量在于:
- promote:本机类型不支持,做类型提升,如不支持 f32,使用 f64 完成 f32 指令
- custom:自定义处理方法,如不支持 fma,就需要自己用 mul 和 add 拼一个 fma
- expand:本机类型不支持,promote 也做不了,就略过或者直接不支持
- legal:本机支持
LLVM 编译器入门 | 编译器