本系列是《Let’s Build A Simple Interpreter 》的阅读笔记。
语法 以下面的示例程序为例:
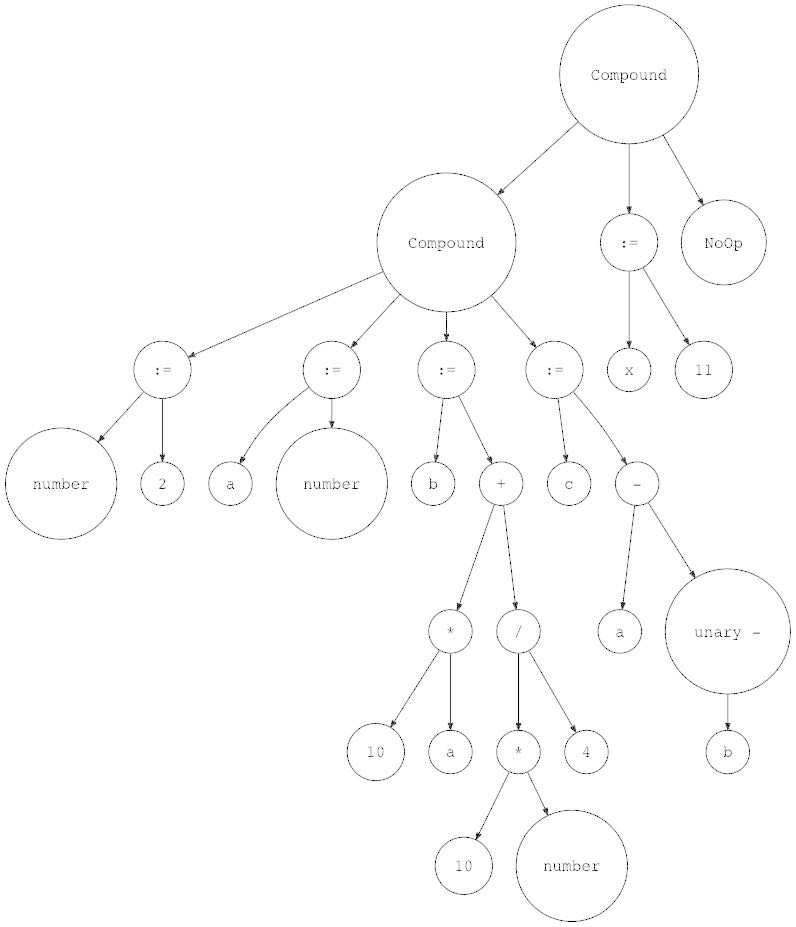
1 2 3 4 5 6 7 8 9 BEGIN BEGIN number := 2 ; a := number; b := 10 * a + 10 * number / 4 ; c := a - - b END ; x := 11 ; END .
一个 Pascal program 由一个点号结尾的复合语句组成。下面是一个 program 的例子:
注:这并不是一个完整的 program 定义,我们会在本系列的后续扩展它。
复合语句 compound statement 是一个由 BEGIN 和 END 标识的块,可以包含一组(可能为空)语句,这些语句也可能是复合语句。复合语句中的每条语句,除了最后一条,都必须以一个分号结尾。块中的最后一条语句可以包含或不包含结尾分号。这里是一些合法的复合语句:
1 2 3 4 BEGIN END BEGIN a := 5 x := 11 END BEGIN a := 5 x := 11 ; END BEGIN BEGIN a := 5 END ; x := 11 END
statement list 是一列在复合语句中的 0 或多个语句。参考上面的例子。
statement 可以是一个复合语句,一个赋值语句,也可以是一个空语句。
assignment statement 是一个变量后跟一个 ASSIGN token(两个字符,“:”和“=”) 后再跟一个表达式。
1 2 a := 11 b := a + 9 - 5 * 2
variable 是一个标识符。我们使用 ID token 表示变量。token 的值是该变量的名字如 “a”,“number”等。在下面的代码块中“a”和“b”是变量:
1 BEGIN a := 11 ; b := a + 9 - 5 * 2 END
empty 语句表示一个没有更多产生式的语法规则。我们在 parser 中用空语句语法规则来 标志语句列表的结束及允许复合语句中为空如 ‘BEGIN END’。
factor 规则被修改为处理变量。
上述语法使用 BNF 记法表达如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 program : compound_statement DOT compound_statement : BEGIN statement_list END statement_list : statement | statement SEMI statement_list statement : compound_statement | assignment_statement | empty assignment_statement : variable ASSIGN expr empty : expr : term ((PLUS | MINUS) term)* term : factor ((MUL | DIV) factor)* factor : PLUS factor | MINUS factor | INTEGER | LPAREN expr RPAREN | variable variable : ID
这里没有在 compound_statement 规则中使用星号这个符号来表示 0 或 多次重复,而是明确地定义了 statement_list 规则。这是表示“0 或多次”操作的另一种方式。
词法分析器 lexer 为了支持 Pascal 的 program 定义,以及 compound statement, assignment statement 和 variable,lexer 需要返回新的 token:
BEGIN:标识 compound statement 的开始
EN:标识 compound statement 的结束
DOT:代表点字符“.”的 token,pascal 的 program 定义需要它
ASSIGN:代表两个字符序列“:=”的 token
SEMI:代表分号字符“;”的 token,用来在 compound statement 中标识一条 statement 的结束
ID:代表合法标识符的 token。标识符由字母开头,后跟任意数量的字母或数字
因为 Pascal 变量和保留关键字都是标识符,我们会在一个方法 _id 中处理它们。它的工作方式是 lexer 消耗一个字母数字序列然后查看它是否是保留字。如果是,就返回一个为该关键字预先构建好的 token。如果不是,就返回一个新的 ID token,它的值就是所消耗的字符串(lexeme)。代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 RESERVED_KEYWORDS = { 'BEGIN' : Token('BEGIN' , 'BEGIN' ), 'END' : Token('END' , 'END' ), } def _id (self ): """Handle identifiers and reserved keywords""" result = '' while self.current_char is not None and self.current_char.isalnum(): result += self.current_char self.advance() token = RESERVED_KEYWORDS.get(result, Token(ID, result)) return token
句法分析器 parser parser 新增了 4 个节点:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class Compound (AST ): """Represents a 'BEGIN ... END' block""" def __init__ (self ): self.children = [] class Assign (AST ): def __init__ (self, left, op, right ): self.left = left self.token = self.op = op self.right = right class Var (AST ): """The Var node is constructed out of ID token.""" def __init__ (self, token ): self.token = token self.value = token.value class NoOp (AST ): pass
parser 新增了 7 个新方法。这些方法负责解析新语言结构及构建新的 AST 结点:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 def program (self ): """program : compound_statement DOT""" node = self.compound_statement() self.eat(DOT) return node def compound_statement (self ): """ compound_statement : BEGIN statement_list END """ self.eat(BEGIN) nodes = self.statement_list() self.eat(END) root = Compound() for node in nodes: root.children.append(node) return root def statement_list (self ): """ statement_list : statement | statement SEMI statement_list """ node = self.statement() results = [node] while self.current_token.type == SEMI: self.eat(SEMI) results.append(self.statement()) if self.current_token.type == ID: self.error() return results def statement (self ): """ statement : compound_statement | assignment_statement | empty """ if self.current_token.type == BEGIN: node = self.compound_statement() elif self.current_token.type == ID: node = self.assignment_statement() else : node = self.empty() return node def assignment_statement (self ): """ assignment_statement : variable ASSIGN expr """ left = self.variable() token = self.current_token self.eat(ASSIGN) right = self.expr() node = Assign(left, token, right) return node def variable (self ): """ variable : ID """ node = Var(self.current_token) self.eat(ID) return node def empty (self ): """An empty production""" return NoOp()
还需要更新现在的 factor 方法来解析变量:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 def factor (self ): """factor : PLUS factor | MINUS factor | INTEGER | LPAREN expr RPAREN | variable """ token = self.current_token if token.type == PLUS: self.eat(PLUS) node = UnaryOp(token, self.factor()) return node ... else : node = self.variable() return node
前面的示例程序对应的 AST 如下:
解释器 interpreter 针对上面新增的四个 Op,需要为 interpreter 需要添加相应的 visitor 方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 def visit_Compound (self, node ): for child in node.children: self.visit(child) def visit_NoOp (self, node ): pass def visit_Assign (self, node ): var_name = node.left.value self.GLOBAL_SCOPE[var_name] = self.visit(node.right) def visit_Var (self, node ): var_name = node.value val = self.GLOBAL_SCOPE.get(var_name) if val is None : raise NameError(repr (var_name)) else : return val
visit_Assign 方法保存了一个键值对(变量名和与之相关的值)到一个名为 GLOBAL_SCOPE 符号表中。符号表是一个用来跟踪源代码中各种符号的抽象数据类型。目前仅有的符号类型就是变量。visit_Var 方法访问一个 Var 结点时,首先得到变量名,然后把该名字当作键值从 GLOBAL_SCOPE 字典中得到变量的值。如果它找到了值,就返回它,如果没有找到,就抛出一个异常。
完善语法 为了可以解析下面这个完整的 Pascal 程序,需要进一步完善语法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 PROGRAM Part10;VAR number : INTEGER; a, b, c, x : INTEGER; y : REAL; BEGIN BEGIN number := 2 ; a := number; b := 10 * a + 10 * number DIV 4 ; c := a - - bb END ; x := 11 ; y := 20 / 7 + 3.14 ; END .
program 语法规则的定义更新为了包含 PORGRAM 保留关键字,程序名,和一个点号结尾的 block。下面是一个完整 Pascal 程序的例子:
1 2 3 PROGRAM Part10;BEGIN END .
block 规则将 declarations 规则和 compoundstatement 规则组合在一起。下面是一个 block 的例子:
1 2 3 4 5 VAR number : INTEGER; BEGIN END
再来一个例子:
Pascal 的 declarations 有几个部分组成,且每个部分都是可选的。在本文中,我们只 会使用变量声明这部分。 declarations 规则要么有一个 variabledeclaration 子规则,要么为空。
Pascal 是一门静态有类型语言,意味着每个变量都需要一个变量声明来指定它的类型。 在 Pascal 中,变量必须在使用之前声明。这通过在程序的 variabledeclaration 部分使用保留关键字 VAR 来实现。你可以使用如下方式定义变量:
1 2 3 4 VAR number : INTEGER; a, b, c, x : INTEGER; y : REAL;
typespec 规则用来处理类型 INTEGER 和 REAL 以及在变量声明时使用。在下面的例子中
1 2 3 VAR a : INTEGER; b : REAL;
变量“a”被声明为类型 INTEGER 而变量 “b”被声明为了类型 REAL(float)。本文不会强制类型检查,但在后续文章中会加入。
term 规则修改为了使用关键字 DIV 表示整数除法以及用斜杠/表示浮点数除法。
之前,20 除以 7 使用斜杠会产生一个整数 2:
现在,20 除以 7 使用斜杠会产生一个实数(浮点数) 2.85714285714 :
从现在起,要得到一个整数而非实数,你需要使用 DIV 关键字:
factor 规则更新为了同时处理整数和实数(浮点数)常量。我还移除了子规则 INTEGER,因为常量会用 token INTEGERCONST 和 REALCONST 来表示,tokenINTEGER 会被用来表示整数类型。在下面的例子中 lexer 会为 20 和 7 生成一个 INTEGERCONST token,为 3.14 生成一个 REALCONST token:
上述语法使用 BNF 记法表达如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 program : PROGRAM variable SEMI block DOT block : declarations compound_statement declarations : VAR (variable_declaration SEMI)+ | empty variable_declaration : ID (COMMA ID)* COLON type_spec type_spec : INTEGER | REAL compound_statement : BEGIN statement_list END statement_list : statement | statement SEMI statement_list statement : compound_statement | assignment_statement | empty assignment_statement : variable ASSIGN expr empty : expr : term ((PLUS | MINUS) term)* term : factor ((MUL | INTEGER_DIV | FLOAT_DIV) factor)* factor : PLUS factor | MINUS factor | INTEGER_CONST | REAL_CONST | LPAREN expr RPAREN | variable variable : ID
注:在 declarations 的表达式中,+ 号代表匹配 1 次或多次。
接下来仍然需要像前面那样修改 lexer、parser 和 interpreter。
lexer
新的 token
PROGRAM(保留关键字)
VAR(保留关键字)
COLON(:)
COMMA(,)
INTEGER(表示整数类型而不是像 3 或 5 这样的整型常量)
REAL(表示 Pascal 的 REAL 类型)
INTEGERCONST(如,3 或 5)
REALCONST(如,3.14 等)
INTEGERDIV 表示整数除法(保留关键字 DIV )
FLOATDIV 表示浮点数除法(即斜杠 /)
新的 skep_comments 方法,用来处理 Pascal 注释
重命名 integer 方法并做一些修改
更新 get_next_token 方法使它能返回新的 token
parser 新增节点:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Program (AST ): def __init__ (self, name, block ): self.name = name self.block = block class Block (AST ): def __init__ (self, declarations, compound_statement ): self.declarations = declarations self.compound_statement = compound_statement class VarDecl (AST ): def __init__ (self, var_node, type_node ): self.var_node = var_node self.type_node = type_node class Type (AST ): def __init__ (self, token ): self.token = token self.value = token.value
新增函数以解析新的语言结构及构建新的 AST 结点:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 def block (self ): """block : declarations compound_statement""" declaration_nodes = self.declarations() compound_statement_node = self.compound_statement() node = Block(declaration_nodes, compound_statement_node) return node def declarations (self ): """declarations : VAR (variable_declaration SEMI)+ | empty """ declarations = [] if self.current_token.type == VAR: self.eat(VAR) while self.current_token.type == ID: var_decl = self.variable_declaration() declarations.extend(var_decl) self.eat(SEMI) return declarations def variable_declaration (self ): """variable_declaration : ID (COMMA ID)* COLON type_spec""" var_nodes = [Var(self.current_token)] self.eat(ID) while self.current_token.type == COMMA: self.eat(COMMA) var_nodes.append(Var(self.current_token)) self.eat(ID) self.eat(COLON) type_node = self.type_spec() var_declarations = [ VarDecl(var_node, type_node) for var_node in var_nodes ] return var_declarations def type_spec (self ): """type_spec : INTEGER | REAL """ token = self.current_token if self.current_token.type == INTEGER: self.eat(INTEGER) else : self.eat(REAL) node = Type (token) return node
修改 program、term、factor 这些方法来适应修改过的语法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 def program (self ): """program : PROGRAM variable SEMI block DOT""" self.eat(PROGRAM) var_node = self.variable() prog_name = var_node.value self.eat(SEMI) block_node = self.block() program_node = Program(prog_name, block_node) self.eat(DOT) return program_node def term (self ): """term : factor ((MUL | INTEGER_DIV | FLOAT_DIV) factor)*""" node = self.factor() while self.current_token.type in (MUL, INTEGER_DIV, FLOAT_DIV): token = self.current_token if token.type == MUL: self.eat(MUL) elif token.type == INTEGER_DIV: self.eat(INTEGER_DIV) elif token.type == FLOAT_DIV: self.eat(FLOAT_DIV) node = BinOp(left=node, op=token, right=self.factor()) return node def factor (self ): """factor : PLUS factor | MINUS factor | INTEGER_CONST | REAL_CONST | LPAREN expr RPAREN | variable """ token = self.current_token if token.type == PLUS: self.eat(PLUS) node = UnaryOp(token, self.factor()) return node elif token.type == MINUS: self.eat(MINUS) node = UnaryOp(token, self.factor()) return node elif token.type == INTEGER_CONST: self.eat(INTEGER_CONST) return Num(token) elif token.type == REAL_CONST: self.eat(REAL_CONST) return Num(token) elif token.type == LPAREN: self.eat(LPAREN) node = self.expr() self.eat(RPAREN) return node else : node = self.variable() return node
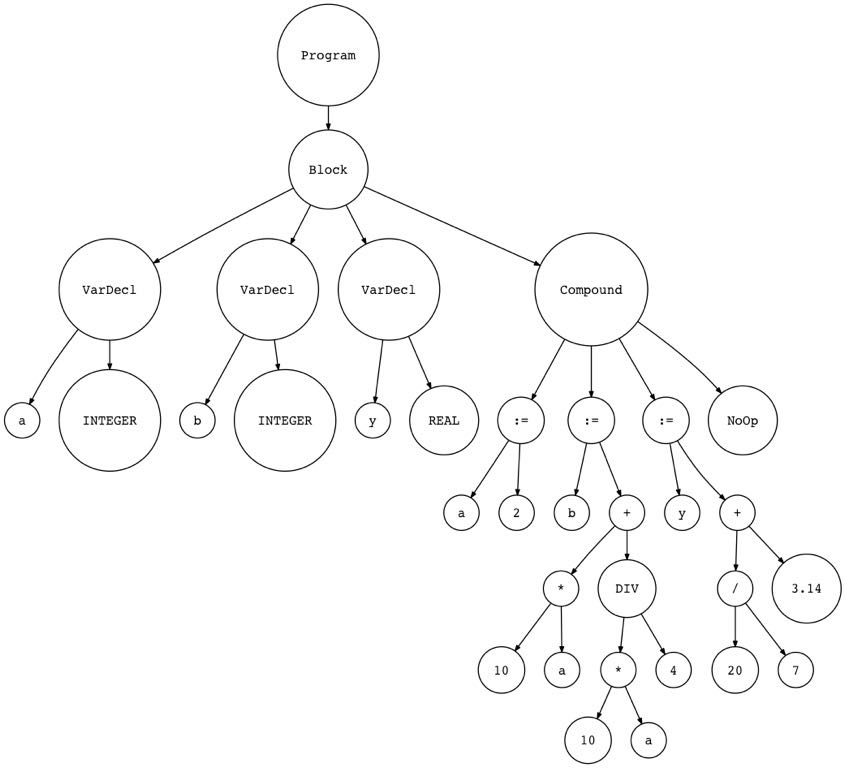
对于下面这段简短但是完整的代码,其 AST 是这样的:
1 2 3 4 5 6 7 8 9 10 PROGRAM Part10AST; VAR a, b : INTEGER; y : REAL; BEGIN {Part10AST} a := 2; b := 10 * a + 10 * a DIV 4; y := 20 / 7 + 3.14; END. {Part10AST}
interpreter 增加了四个新的访问结点的方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def visit_Program (self, node ): self.visit(node.block) def visit_Block (self, node ): for declaration in node.declarations: self.visit(declaration) self.visit(node.compound_statement) def visit_VarDecl (self, node ): pass def visit_Type (self, node ): pass
还需要修改 visit_BinOp 方法来解释整数和浮点数除法:
1 2 3 4 5 6 7 8 9 10 11 def visit_BinOp (self, node ): if node.op.type == PLUS: return self.visit(node.left) + self.visit(node.right) elif node.op.type == MINUS: return self.visit(node.left) - self.visit(node.right) elif node.op.type == MUL: return self.visit(node.left) * self.visit(node.right) elif node.op.type == INTEGER_DIV: return self.visit(node.left) // self.visit(node.right) elif node.op.type == FLOAT_DIV: return float (self.visit(node.left)) / float (self.visit(node.right))